题目描述:
Catcher是MCA国的情报员,他工作时发现敌国会用一些对称的密码进行通信,比如像这些ABBA,ABA,A,123321,但是他们有时会在开始或结束时加入一些无关的字符以防止别国破解。比如进行下列变化 ABBA->12ABBA,ABA->ABAKK,123321->51233214 。因为截获的串太长了,而且存在多种可能的情况(abaaab可看作是aba,或baaab的加密形式),Cathcer的工作量实在是太大了,他只能向电脑高手求助,你能帮Catcher找出最长的有效密码串吗?
输入描述:
输入一个字符串
输出描述:
返回有效密码串的最大长度
输入:
ABBA
输出:
4
思路:
法一:中心扩展法
字符或两个字符向两边扩散(分别对应ABA、ABBA型),返回最大值。时间复杂度为o(n^2)。代码如下:
1 #include<iostream> 2 #include<algorithm> 3 using namespace std; 4 int getlen(string s,int i){ //s[i]或s[i]、s[i+1]为中心向两边延伸的最大回文长度 5 int m=0,n=0; 6 for(int j=i,k=i;j>=0&&k<s.length()&&s[j]==s[k];--j,++k,++m); 7 for(int j=i,k=i+1;j>=0&&k<s.length()&&s[j]==s[k];--j,++k,++n); 8 return max(m*2-1,n*2); 9 } 10 int main(){ 11 string s; 12 while(cin>>s){ 13 int maxn=0; 14 for(int i=0;i<s.length();++i) 15 maxn=max(maxn,getlen(s,i)); 16 cout<<maxn<<endl; 17 } 18 }
法二:Manacher算法。
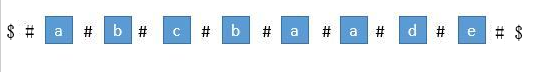
我们用一个数组 P 保存从中心扩展的最大个数,而它刚好也是去掉 "#" 的原字符串的总长度。例如下图中下标是 6 的地方。可以看到 P[ 6 ] 等于 5,所以它是从左边扩展 5 个字符,相应的右边也是扩展 5 个字符,也就是 "#c#b#c#b#c#"。而去掉 # 恢复到原来的字符串,变成 "cbcbc",它的长度刚好也就是 5。


一、求每个 P [ i ]
接下来是算法的关键了,它充分利用了回文串的对称性。
我们用 C 表示回文串的中心,用 R 表示回文串的右边半径坐标,所以 R = C + P[ C ] 。C 和 R 所对应的回文串是当前循环中 R 最靠右的回文串。
让我们考虑求 P [ i ] 的时候,如下图。
用 i_mirror 表示当前需要求的第 i 个字符关于 C 对应的下标。
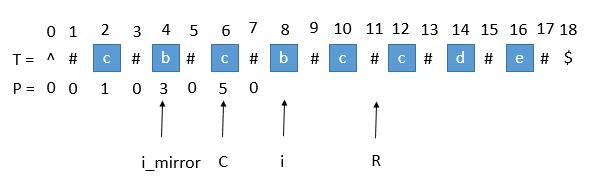
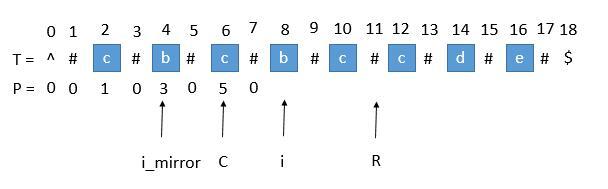
我们现在要求 P [ i ], 如果是用中心扩展法,那就向两边扩展比对就行了。但是我们其实可以利用回文串 C 的对称性。i 关于 C 的对称点是 i_mirror ,P [ i_mirror ] = 3,所以 P [ i ] 也等于 3 。
但是有三种情况将会造成直接赋值为 P [ i_mirror ] 是不正确的,下边一一讨论。
1. 超出了 R
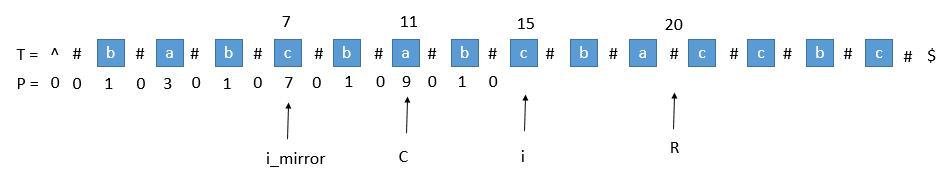
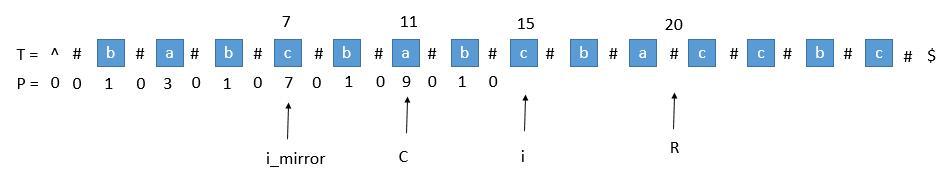
当我们要求 P [ i ] 的时候,P [ mirror ] = 7,而此时 P [ i ] 并不等于 7 ,为什么呢,因为我们从 i 开始往后数 7 个,等于 22 ,已经超过了最右的 R ,此时不能利用对称性了,但我们一定可以扩展到 R 的,所以 P [ i ] 至少等于 R - i = 20 - 15 = 5,会不会更大呢,我们只需要比较 T [ R+1 ] 和 T [ R+1 ]关于 i 的对称点就行了,就像中心扩展法一样一个个扩展。
2. P [ i_mirror ] 遇到了原字符串的左边界
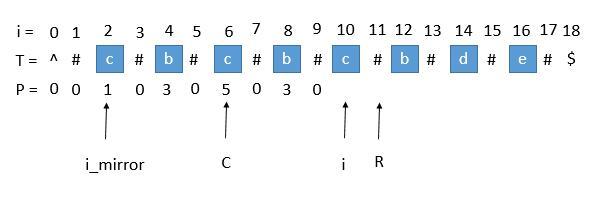
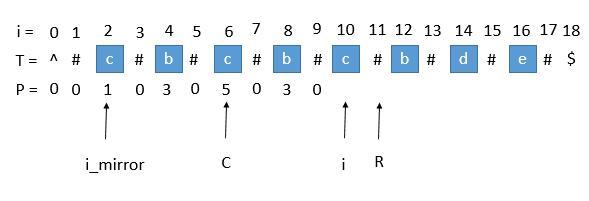
此时P [ i_mirror ] = 1, P [ i_mirror ] 在扩展的时候首先是 "#" == "#" ,之后遇到了 "^"和另一个字符比较,也就是到了边界,终止了循环。而 P [ i ] 并没有遇到边界,所以我们可以继续通过中心扩展法一步一步向两边扩展。
3. i 等于了 R
此时P[i]=R-i== 0 ,然后通过中心扩展法一步一步扩展。
二、考虑 C 和 R 的更新
就这样一步一步的求出每个 P [ i ],当求出的 P [ i ] 的右边界大于当前的 R 时,我们就需要更新 C 和 R 为当前的回文串了。因为我们必须保证 i 在 R 里面,所以一旦有更右边的 R 就要更新 R。
此时的 P [ i ] 求出来将会是 3 ,P [ i ] 对应的右边界将是 10 + 3 = 13,所以大于当前的 R ,我们需要把 C 更新成 i 的值,也就是 10 ,R 更新成 13。继续下边的循环。
三、总结
1、第一步先令p[i]等于其对称点与i到R的距离中的最小值:p[i]=min(R-i,p[i_mirrior])。
2、这时p[i]可能因为以上三种原因而并不准确,而不难发现以上三种情况都需要扩展。所以要从p+p[i]+1向右与p-p[i]-1向左的逐个对比中查看是否递增。
3、如果i+p[i]>R(2的缘故),更新C、R:C=i;R=i+p[i]。
代码如下:
1 #include<iostream> 2 #include<cstring> 3 #include<algorithm> 4 using namespace std; 5 void init(string& s) { 6 string s1 = " "; 7 for (int i = 0; i < s.length(); ++i) { 8 s1 += s[i]; 9 s1 += " "; 10 } 11 s = s1; 12 } 13 int manacher(string s) { 14 init(s); //字符之间(包括两端)插入空格 15 int len = s.length(); 16 int* p = new int[len]; 17 memset(p, 0, len * sizeof(int)); 18 int C = 0, R = 0, maxn = 0; 19 for (int i = 0; i < len; ++i) { 20 int i_mirror = 2 * C - i; 21 if (i <= R) 22 p[i] = min(R - i, p[i_mirror]);//不超过右边界的情况下p[i]等于其对称点,否则等于到右边界的距离。 23 for (int j = i - p[i] - 1, k = i + p[i] + 1; j >= 0 && k < len && s[j] == s[k]; --j, ++k, ++p[i]);//防止三种情况,进行以i为中心向外扩展。 24 maxn = max(maxn, p[i]); 25 if (i + p[i] > R) { //当i+p[i]右边界时,更新对称中心和右边界 26 C = i; 27 R = i + p[i]; 28 } 29 } 30 delete[]p; 31 return maxn; 32 } 33 int main() { 34 string s; 35 while (cin >> s) 36 cout << manacher(s) << endl; 37 }