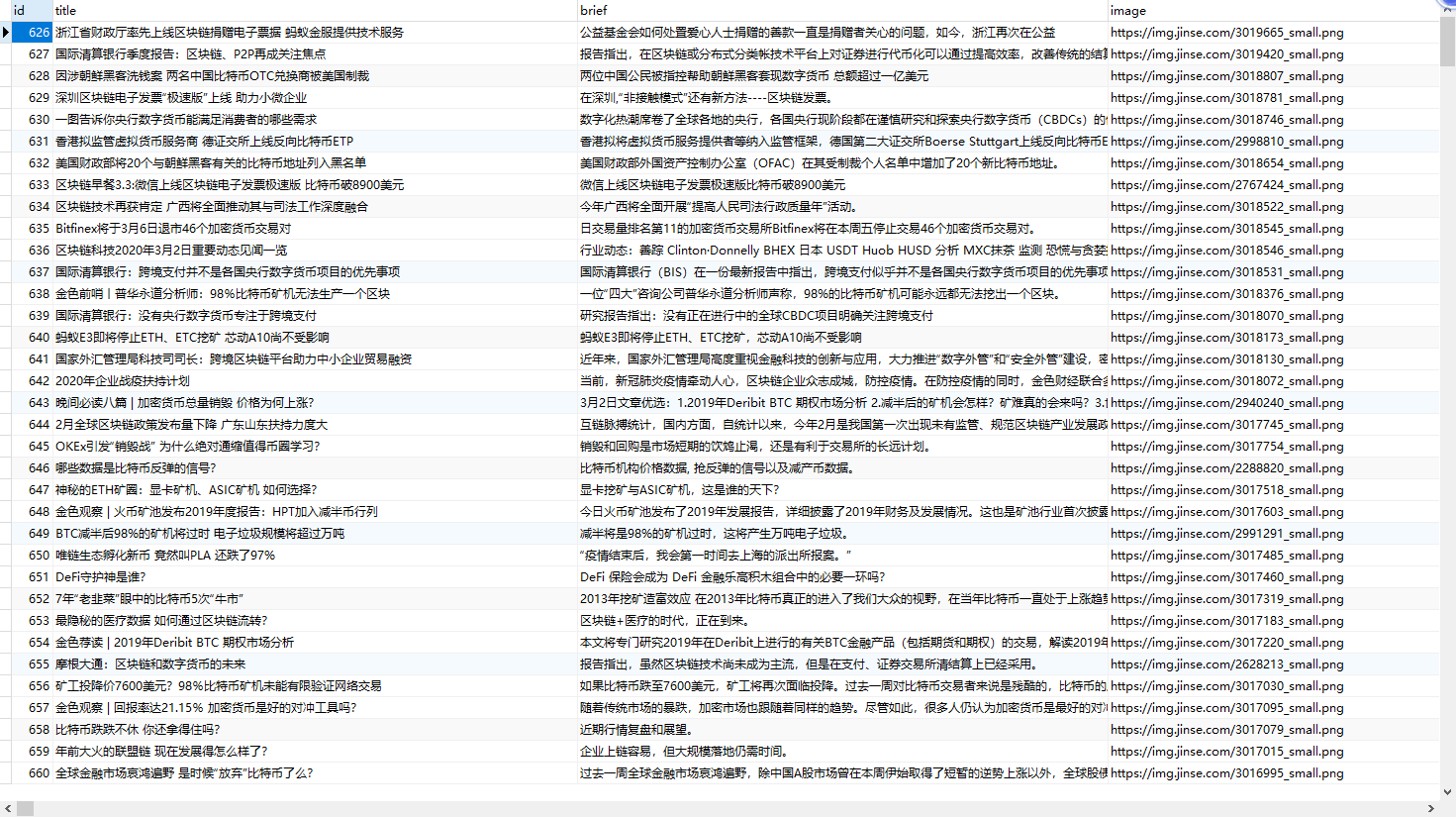
scrapy 基础教程
1. 认识Scrapy:
来一张图了解一下scrapy工作流程:(这张图是在百度下载的)
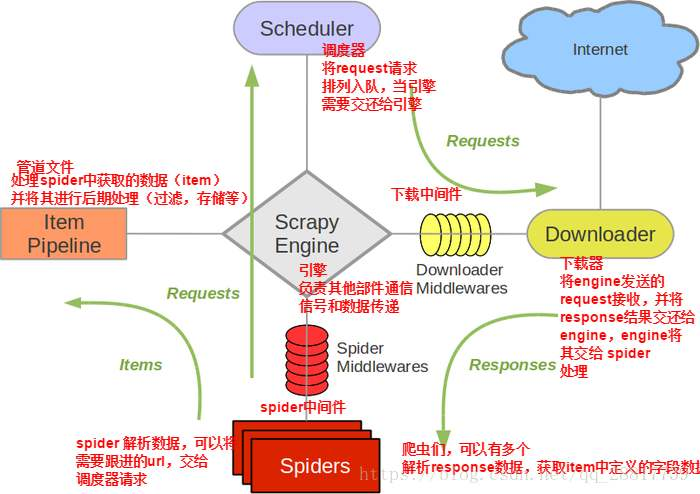
scrapy 各部分的功能:
1. Scrapy Engine(引擎): 负责Spider,Item Pipeline,Downloader,Scheduler 中间的通讯,信号,数据传递等
2. Scheduler(调度器): 负责接收引擎发送过来的 request 请求,并按照一定的方式进行整理队列,入队,当引擎需要时,交还给引擎
3. Downloader(下载器): 负责下载 Scrapy Engine(引擎)发送的所有 request 请求,并将其获取到的 response 交还给 Scrapy Engine(引擎),由 引擎 交给spider 来处理
4. Spider(爬虫): 它负责处理所有response,从中分析提取数据,获取item字段需要的数据,并将需要跟进的URL提交个 引擎 再次进入 Scheduler(调度器)
4. Item Pipeline(管道): 它负责处理Spider中获取到的item,并进行后期处理(详细分析,过滤,存储等)的地方
5. Downloader Middlewares(下载中间件): 你可以当作是一个可以自定义扩展下载功能的组件
6. Spider Middlewares(Spider中间件): 可以理解为是一个可以自定义扩展和操作 引擎 和 Spider 之间通信的功能组件(例如进入Spider 的responses 和从 Spider 出去的 requests)
scrapy 运行流程:
1. 引擎: Hi! Spider,你要处理哪一个网站?
2. Spider: 老大要我处理 xxx.xxx.com.
3. 引擎: 你把第一个需要处理的URL给我吧。
4. Spider: 给你,第一个URL是 xxx.xxx.com.
5. 引擎: Hi! 调度器,我这里有request请求你帮我排序入队一下。
6. 调度器: 好的,正在处理你等一下。
7. 引擎: Hi! 调度器,你把处理好的request请求给我。
8. 调度器: 给你,这是我处理好的request请求。
9. 引擎: Hi! 下载器,你你按照老大的 下载中间件 的设置当我下载一下这个request请求。
10. 下载器: 好的!给你这是下载好的东西。(如果下载失败:sorry,这个request下载失败了,然后 引擎 告诉 调度器 ,这个request 下载失败了,你记录一下,我们待会再下载)
11. 引擎:Hi! Spider,给你,这是下载好的东西,并且已经按照老大的 下载中间件 处理过了,你自己处理一下(注意!这儿responses默认式交给 def parse() 这个函数处理的)
12. Spider: (处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的item数据。
13. 引擎: Hi! 管道 我这里有个item你帮我处理一下!调度器!这是需要跟进的URL你帮我吃力一下。然后从第四步开始循环,知道老大去玩需要的全部数据。
14. 管道 调度器: 好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止(也就是说对弈下载失败的URL,Scrapy也会重新下载)
2. 准备工作:
安装scrapy
1 pip install wheel
2 pip install scrapy
这里如果安装失败(安装失败很正常)
https://www.cnblogs.com/xingxingnbsp/p/12132020.html 这里有解决办法
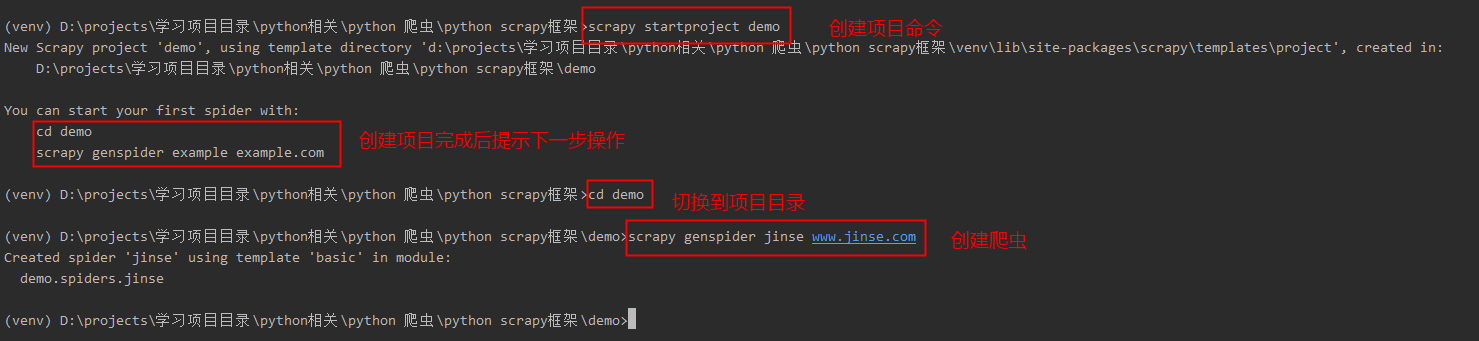
3. 创建项目:
1 # 创建scrapy项目步骤命令
2 # 创建项目
3 scrapy startproject 项目名
4 # 创建爬虫
5 scrapy genspider 爬虫名 www.jinse.com
6 # 运行爬虫
7 + scrapy crawl 爬虫名
如果你已经安装好scrapy 但是还出现下边错误:
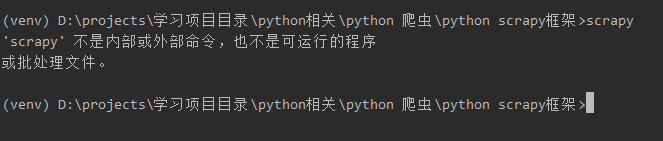
问题所在:
这是由于在当前虚拟环境下找不到scrapy
解决问题:
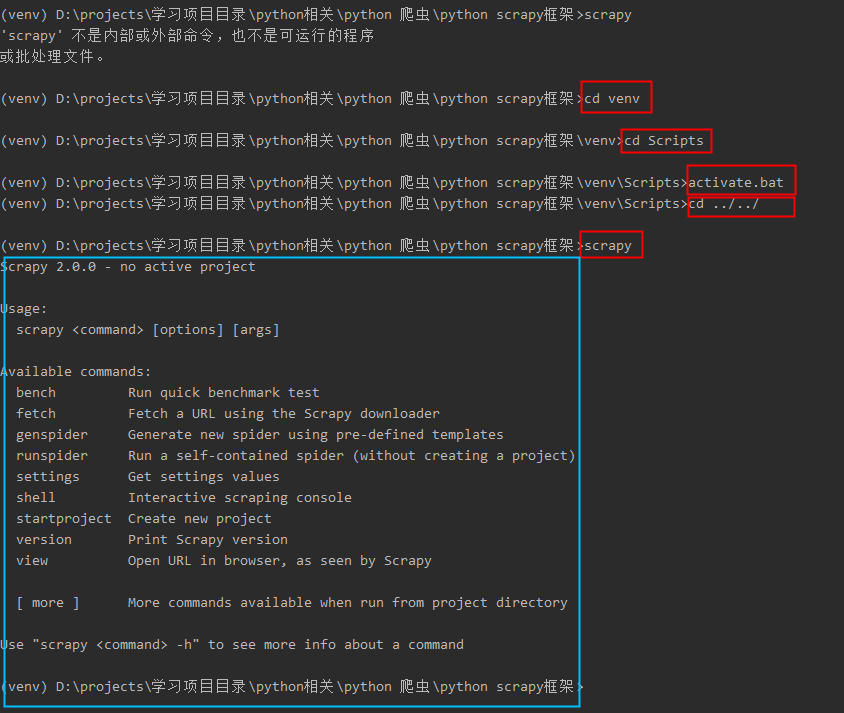
到这里项目就算创建成功了(就是这么简单O(∩_∩)O哈哈~)
4. scrapy 常用命令:
语法:
scrapy <command> [options] [args]
常用命令:
1 bench Run quick benchmark test
2 check Check spider contracts
3 crawl Run a spider
4 edit Edit spider
5 fetch Fetch a URL using the Scrapy downloader
6 genspider Generate new spider using pre-defined templates
7 list List available spiders
8 parse Parse URL (using its spider) and print the results
9 runspider Run a self-contained spider (without creating a project)
10 settings Get settings values
11 shell Interactive scraping console
12 startproject Create new project
13 version Print Scrapy version
14 view Open URL in browser, as seen by Scrapy
5. 了解项目:
项目目录
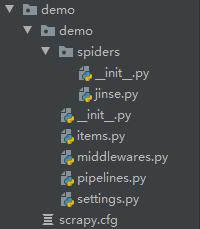
items.py:
数据的存储容器,在对数据进行有处理的操作时,必须要用,例如写入txt,插入数据库等,没有对数据进行操作时,可以不使用
middlewares.py:
该文件是scrapy的中间件文件,可以设置随机请求头,代理,cookie,会话维持等
pipelines.py:
该文件和主要用来存储数据
settings.py:
该文件是scrapy的设置文件,可以配置数据库连接等
spiders/jinse.py:
该文件就是我们刚才创建的爬虫文件
6. 项目开始:
6.1 明确目标:

6.2 分析目标网站:
(1) 网页右键检查,向下拉:
(2) 发现了三个ajax请求:
(3) 随便打开一个请求:
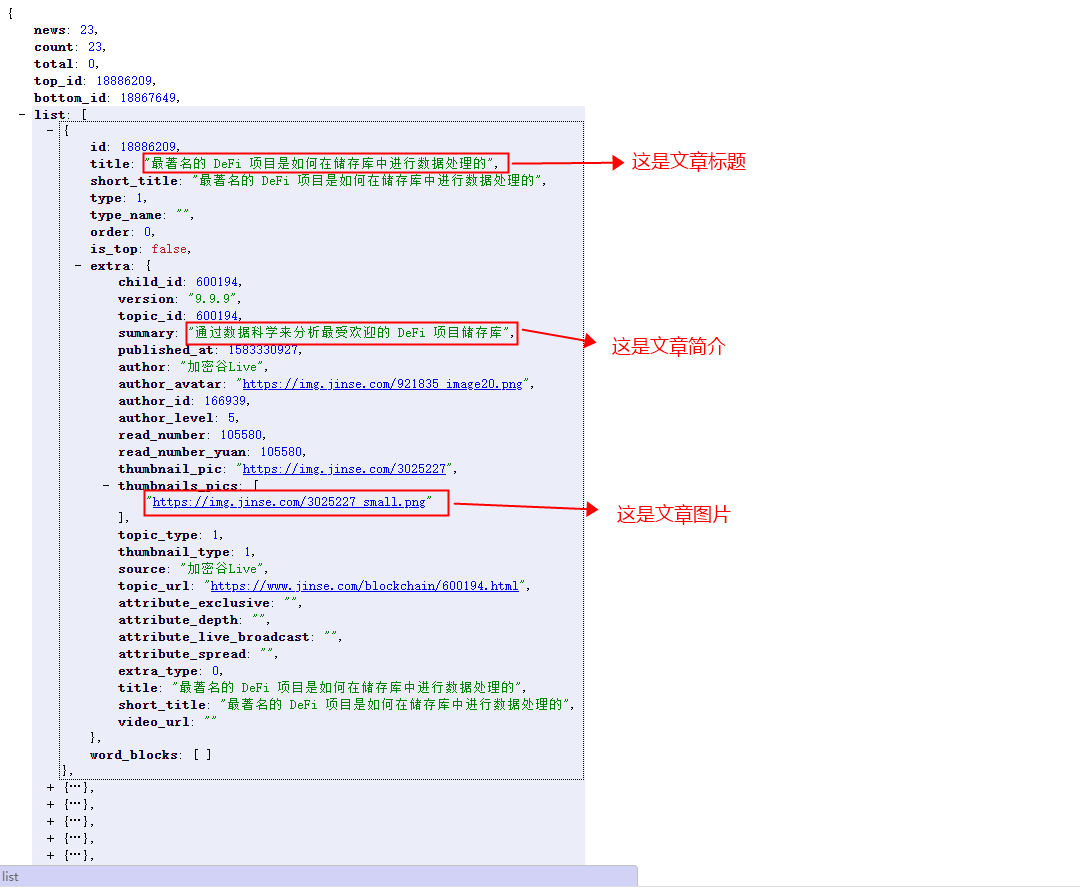
(4) 好的找到了数据,我们还要翻页(这里就要找规律了)
https://api.jinse.com/v6/www/information/list?catelogue_key=news&limit=23&information_id=18886241&flag=down&version=9.9.9&_source=www
https://api.jinse.com/v6/www/information/list?catelogue_key=news&limit=23&information_id=18867649&flag=down&version=9.9.9&_source=www
https://api.jinse.com/v6/www/information/list?catelogue_key=news&limit=23&information_id=18858401&flag=down&version=9.9.9&_source=www
(5) 把这三个请求地址拿出来很明显除了 ‘information_id’ 的值不一样其他的都一样
(6) 又出来了一个问题 information_id 感觉没啥规律啊(难搞哦)
(7) 看刚才的请求结果上边有一个bottom_id 刚好和第二个的 information_id的值一样(这里我们就不试了,我已经试过了确实是这样的)
(8) 现在已经知道规律并且知道网址了那就开干吧
6.3 开始写BUG:
(1) 首先我们先在 items.py 中指定我们要的数据
import scrapy
class DemoItem(scrapy.Item):
# 文章标题
title = scrapy.Field()
# 文章简介
brief = scrapy.Field()
# 文章图片
image = scrapy.Field()
(2) 指定好我们要的数据 下一步编写我们的爬虫 spiders/jinse.py
# -*- coding: utf-8 -*-
import json
import scrapy
from ..items import DemoItem
class JinseSpider(scrapy.Spider):
name = 'jinse'
allowed_domains = ['www.jinse.com']
start_urls = ['https://api.jinse.com/v6/www/information/list?catelogue_key=news&limit=23&information_id=18851073&flag=down&version=9.9.9&_source=www']
def parse(self, response):
# 获取响应并使用json解析
data = json.loads(response.text)
# 获取下一页的 bottom_id
bottom_id = data["bottom_id"]
# 这里是数据列表
data_list = data["list"]
for data in data_list:
# 实例化DemoItem
jinse_item = DemoItem()
# 获取文章标题
jinse_item["title"] = data["title"]
# 获取文章简介
jinse_item["brief"] = data["extra"]["summary"]
# 获取文章图片
jinse_item["image"] = data["extra"]["thumbnails_pics"][0]
# 将数据放入管道中
yield jinse_item
# 判断是否还有下一页
if bottom_id:
# 执行回调函数
yield scrapy.Request(
"https://api.jinse.com/v6/www/information/list?catelogue_key=news&limit=23&information_id={}&flag=down&version=9.9.9&_source=www".format(bottom_id), callback=self.parse)
(3) 获取到了数据我们打印出来看一下 :
scrapy crawl jinse # 注意当前所在的目录

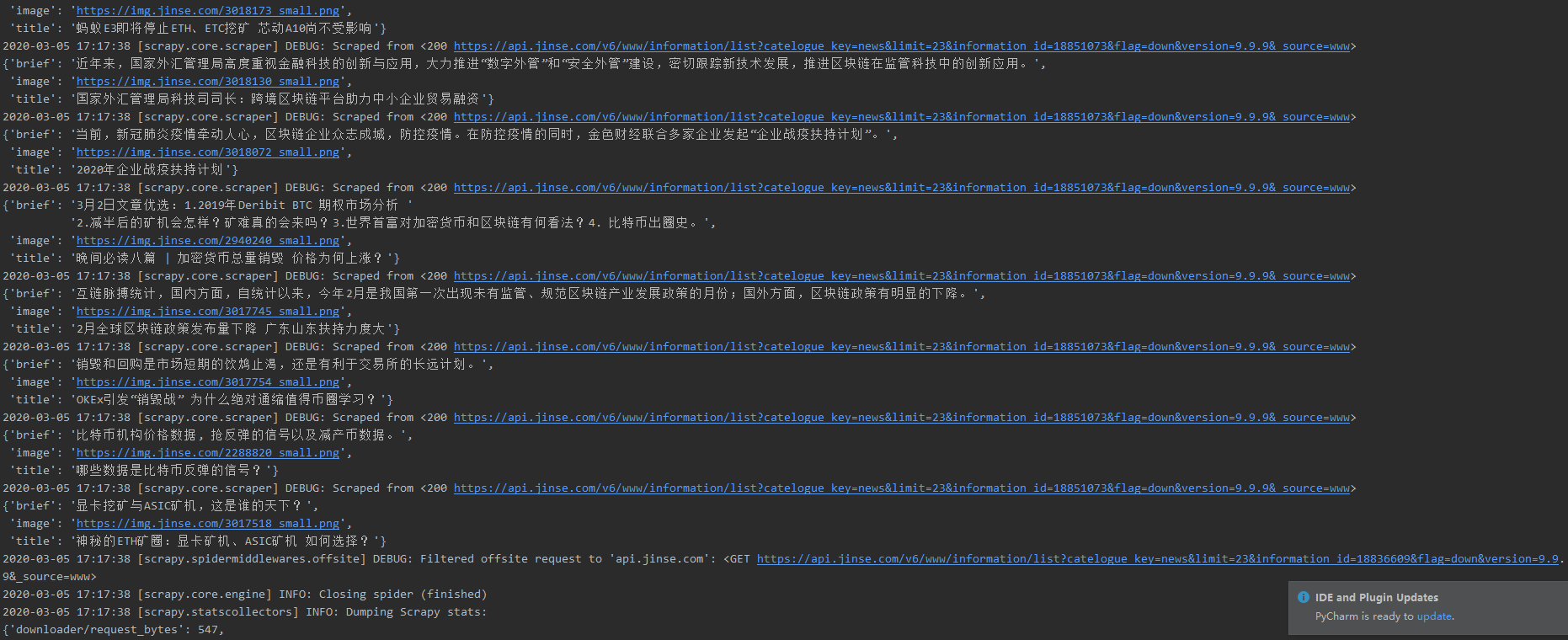
(4) 结果出来了但是为什么只打印了一页???(一脸懵逼.....)

(5) 看到错误了
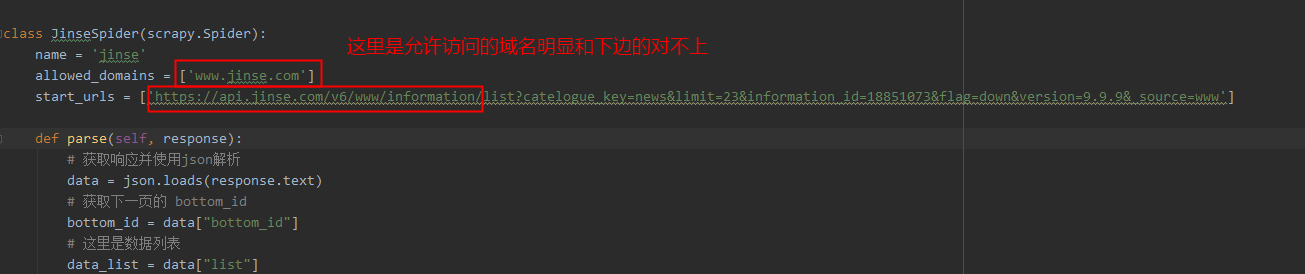
这是因为下边的URL是api接口的地址
(6) 解决问题:
将 api.jinse.com 添加到允许的域名中

(7) 再次运行:

这次没问题了,程序一顿狂搂(想要停止按 Crlt+c)
6.4 将数据存储在mysql数据库中
(1) 创建数据库(这里我是使用的工具)
1. 创建数据库 (数据库名为 jinse)
2. 创建表名叫 jinse
3. 数据库字段(id要自增,要不然会报错)

(2) 在 settings.py 中配置数据库连接参数:
# 配置mysql数据库连接
mysql_db = {
"host":"127.0.0.1",
"port":3306,
"user":"root",
"password":"你的密码",
"db":"jinse"
}
(3) 在 pipelines.py 中连接数据库存储数据
安装 pymysql pip install pymysql
from .settings import mysql_db
import pymysql
class DemoPipeline(object):
def __init__(self):
host = mysql_db["host"]
port = mysql_db["port"]
user = mysql_db["user"]
password = mysql_db["password"]
db = mysql_db["db"]
# 创建连接
self.conn = pymysql.connect(host=host, port=port, user=user, password=password, db=db, charset='utf8')
# 创建游标
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = """ insert into jinse(title,brief,image) values ('%s','%s','%s')""" %(item["title"],item["brief"],item["image"])
try:
self.cursor.execute(sql)
self.conn.commit()
except:
self.conn.rollback()
return item
(4) 在 settings.py 中修改
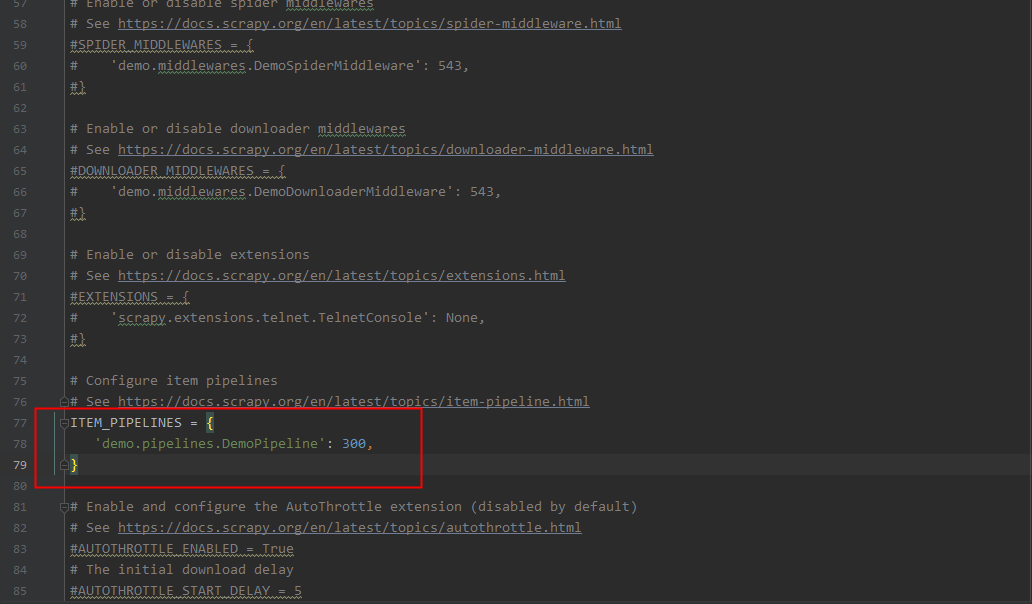
把注释去掉
(5) 运行项目
scrapy crawl jinse # 注意当前所在的目录
跑了10秒左右 505条数据(我的id不是从1开始是因为我之前把数据删了,速度还可以)