1.课前鸡汤
《伟大领袖传》
《亡命之徒》
《西部世界》
2.RabbitMQ
话说python自己又消息队列功能,为啥还要用这个MQ,见详解:
Threading QUEU(线程QUEU)、进程QUEU两种;这两种都是python自带的QUEU,这两只能用在同一个进程下的所有子进程或父进程与子进程之间的通讯所以就有了第三方的消息队列,主流的消息队列有很多,如:rabbitmq,RocketMQ等
优点:1,省去维护网络通讯的繁琐事情
2,可以在多个应用之间起到消息通讯
废话少说,上代码:
消息生产端
# Author:Sean sir import pika # 在建立链接的时候,我们可以指定N多参数, # host=None,port=None,virtual_host=None,credentials=None,channel_max=None,frame_max=None,heartbeat_interval=None,ssl=None,ssl_options=None,connection_attempts=None,retry_delay=None,socket_timeout=None,locale=None,backpressure_detection=None connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明queue channel.queue_declare(queue='hello') # n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange. # 发送一条信息到rabbitmq服务器,消息队列为hello,消息内容为hello world! channel.basic_publish(exchange='',routing_key='hello',body='Hello World!' ) # 发送完成后在本地打印一条信息 print(" [x] Sent 'Hello World!'") # 关闭这个链接 connection.close()
消息消费端
# Author:Sean sir __author__ = 'Alex Li' import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # You may ask why we declare the queue again ‒ we have already declared it in our previous code. # We could avoid that if we were sure that the queue already exists. For example if send.py program # was run before. But we're not yet sure which program to run first. In such cases it's a good # practice to repeat declaring the queue in both programs. # 上面大王拽了一大堆的英文,大概的意思就是,下面这个管道我们可以不声明,但是前提你的确定生产者已经生命了 # 这里我们虽然确定生产者已经生命,但是我们不确定在运行的时候是生产者先运行,还是消费者先运行,故这里也 # 声明了一遍 channel.queue_declare(queue='hello') def callback(ch, method, properties, body): print(" [x] Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback,queue='hello',no_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()
生产者运行完毕后,一次性生效,如果还要发消息,需要再次运行;消费者运行后,永久接受消息,如想终止消息接受,需要按Ctrl+C终止
MQ如何才能确保消费者真正成功的消费了一条消息
新的问题又来了,上面我们发现,假如我们有多个消费者,对应一个mq,那么某个消息被消费者消费后是否消费成功,mq并不care,只要你消费了,成功与否不管,那么就会在mq中去掉这条消息,那么问题来了,假如消费者并没真正的处理完消息,就宕机了,那怎么办呢?
看代码:生产者代码不变,只需要更改消费者,
可以先后启动多个消费者,然后消费的过程sleep30秒,假如mq中有一个消息,启动第一个消费者,然后关掉,再启动第二个消费者,看是是否能收到消息,
答案是肯定的
# Author:Sean sir __author__ = 'Alex Li' import pika,time connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # You may ask why we declare the queue again ‒ we have already declared it in our previous code. # We could avoid that if we were sure that the queue already exists. For example if send.py program # was run before. But we're not yet sure which program to run first. In such cases it's a good # practice to repeat declaring the queue in both programs. # 上面大王拽了一大堆的英文,大概的意思就是,下面这个管道我们可以不声明,但是前提你的确定生产者已经生命了 # 这里我们虽然确定生产者已经生命,但是我们不确定在运行的时候是生产者先运行,还是消费者先运行,故这里也 # 声明了一遍 channel.queue_declare(queue='hello')
def callback(ch, method, properties, body): print(" [x] Received %r" % body) time.sleep(30) print('处理完毕') ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_consume(callback,queue='hello', # 这句话的意思大概就是不给mq发送处理完成的确认请求,那么注释掉,默认消费者如果消费失败,那么就不会给mq发送确认信息,自然mq消息还在等待下一个消费者继续消费 #no_ack=True ) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()
队列持久化
上面的代码能保证消息成功消费了;假如mq宕机了怎么办?经过主编测试MQ服务器宕机了,mq消息都没了,这肯定不行啊,解决办法看下面:
先来持久化一下消息队列,上代码:
# Author:Sean sir import pika,time # 在建立链接的时候,我们可以指定N多参数, # host=None,port=None,virtual_host=None,credentials=None,channel_max=None,frame_max=None,heartbeat_interval=None,ssl=None,ssl_options=None,connection_attempts=None,retry_delay=None,socket_timeout=None,locale=None,backpressure_detection=None connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明queue,在这里只需要加一个durable=True就可以了 channel.queue_declare(queue='hello5',durable=True) # n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange. # 发送一条信息到rabbitmq服务器,消息队列为hello,消息内容为hello world! channel.basic_publish(exchange='',routing_key='hello5',body='Hello World!' ) # 发送完成后在本地打印一条信息 print(" [x] Sent 'Hello World!'") # 关闭这个链接 connection.close()
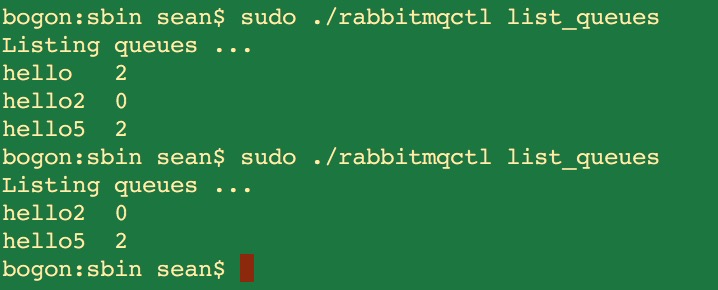
讲一个MQ的命令:查看MQ存放的未被消费的消息
bogon:sbin sean$ sudo ./rabbitmqctl list_queues
Listing queues ...
hello2 0 #消息队列hello2有0条消息
hello5 0 #消息队列hello5有0条消息
消息持久化
当我们发送一个消息队列为hello5的时候,不消费消息,那么down掉mq服务,然后再启动服务,我们发现消息队列还在,可是消息没了,问题还是没能得到解决:
继续上代码,这个代码解决,持久化消息和队列的问题:
# Author:Sean sir import pika,time # 在建立链接的时候,我们可以指定N多参数, # host=None,port=None,virtual_host=None,credentials=None,channel_max=None,frame_max=None,heartbeat_interval=None,ssl=None,ssl_options=None,connection_attempts=None,retry_delay=None,socket_timeout=None,locale=None,backpressure_detection=None connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明queue channel.queue_declare(queue='hello5', # 持久化队列 durable=True) # n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange. # 发送一条信息到rabbitmq服务器,消息队列为hello,消息内容为hello world! channel.basic_publish(exchange='',routing_key='hello5',body='Hello World!', # 持久化消息 properties=pika.BasicProperties( delivery_mode=2, )) # 发送完成后在本地打印一条信息 print(" [x] Sent 'Hello World!'") # 关闭这个链接 connection.close()
查看结果:
我们发现,重启了mq服务,hello5的消息还存在!
消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。------引用自大王博客
新技能:生产者生产一条消息,所有的消费者都能同时收到这条消息!
缓存
mongodb 直接持久化,现在用的比较少
redis 半持久化,需要手动配置,才会持久化
memcache 轻量级缓存,不会持久化
redis------>异步缓存,读写速度惊人!
介绍:
查看redis当下有什么key:
> keys *
设置一个key name存活时间2秒钟
> set name jack ex 2
使用python调用本机redis
方法一:
# Author:Sean sir import redis r = redis.Redis(host='localhost', port=6379) r.set('hufuyang', 'name') print(r.get('hufuyang'))
方法二:
由于后期写代码使用redis会频繁连接redis频繁建立socket连接,我们可以建立一个连接池,所有的连接都从这个池子中去建立好的连接
# Author:Sean sir import redis pool = redis.ConnectionPool(host='localhost',port=6379) r = redis.Redis(connection_pool=pool) r.set('name','sean') print(r.get('name'))
redis不简单支持一个key-value的操作,还支持下面的操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
我们先来看一下string操作:
set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time)
# 设置值 # 参数: # time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值 # 参数: # time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
批量设置值 如: mset(k1='v1', k2='v2') 或 mget({'k1': 'v1', 'k2': 'v2'})
get(name)
获取值
mget(keys, *args)
批量获取 如: mget('ylr', 'wupeiqi') 或 r.mget(['ylr', 'wupeiqi'])
getset(name, value)
设置新值并获取原来的值
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符) # 参数: # name,Redis 的 name # start,起始位置(字节) # end,结束位置(字节) # 如: "武沛齐" ,0-3表示 "武"
127.0.0.1:6379> get name "sean" 127.0.0.1:6379> GETRANGE name 0 1 "se" 127.0.0.1:6379>
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加) # 参数: # offset,字符串的索引,字节(一个汉字三个字节) # value,要设置的值
127.0.0.1:6379> get name "sean" 127.0.0.1:6379> SETRANGE name 0 S (integer) 4 127.0.0.1:6379> get name "Sean"
setbit(name, offset, value)
#使用二进制的方法对key进行操作
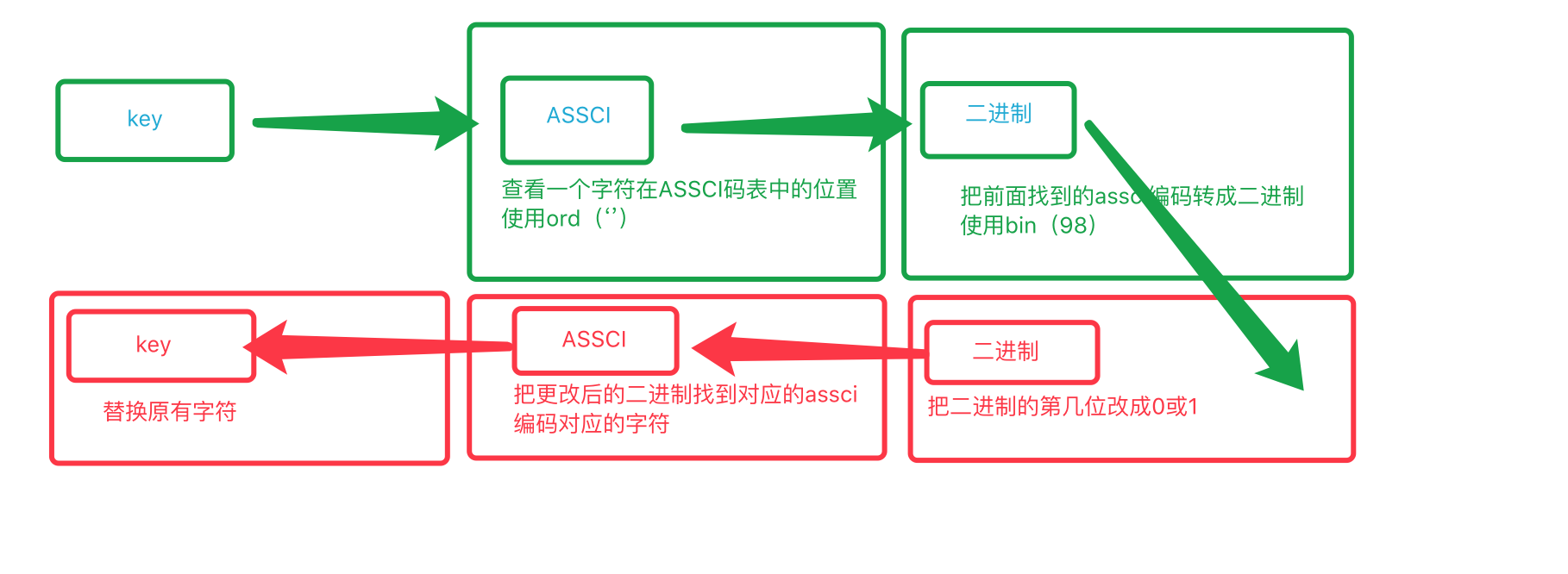
我觉得我说说法更接地气,下面操作一个看看
127.0.0.1:6379> set name sean #设置一个变量 OK >>> ord('s') #查看s对应的assci的编码号 115 >>> ord('S') #查看S对应的assci的编码号 83 >>> bin(115) #查看115转成二进制是多少 '0b1110011' >>> bin(83) #查看83转成二进制是多少 '0b1010011' #想办法吧115编程83,那就是吧115的第2位 由1→0,这个是从左边数 127.0.0.1:6379> SETBIT name 2 0 (integer) 1 127.0.0.1:6379> get name "Sean"
在操作一个变换第二个字符
127.0.0.1:6379> set name sean OK >>> ord('n') 110 >>> ord('N') 78 >>> bin(110) '0b1101110' >>> bin(78) '0b1001110' #这里需要注意的是,我们要更改的是name的第4个字符,这个字符 把n→N前面有三位占据了3*8=24位了,但是计算机是从0开始的,也就是23位,更改n要就是从24位开始数,第24位是0,25不变,26从1变成0 127.0.0.1:6379> SETBIT name 26 0 (integer) 1 127.0.0.1:6379> get name "seaN"
bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数 # 参数: # key,Redis的name # start,位起始位置 # end,位结束位置
127.0.0.1:6379> set n1 b OK 127.0.0.1:6379> BITCOUNT n1 (integer) 3 >>> ord('b') 98 >>> bin(98) '0b1100010'
使用这个bitcount和setbit可以实现一个很牛逼的功能(大王这么说的)
假如要统计一微博现在在线人数,我们可以使用这个方法:
使用setbit每登录一个账户并把这个账户的id对应的位数设置成1,最后使用bitcount来统计这个变量中一共有多少个1,就有多少个在线人数
127.0.0.1:6379> SETBIT n5 222 1 (integer) 0 127.0.0.1:6379> SETBIT n5 55 1 (integer) 0 127.0.0.1:6379> SETBIT n5 495 1 (integer) 0 127.0.0.1:6379> BITCOUNT n5 (integer) 3
登录了三个账户,最后统计一下n5有多少个1,就说明有多少个在线用户数
incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数: # name,Redis的name # amount,自增数(必须是整数) # 注:同incrby
decr(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。 # 参数: # name,Redis的name # amount,自减数(整数)
strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)
incrbyfloat(self, name, amount=1.0)
指定小数的增加
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。 # 参数: # name,Redis的name # amount,自减数(整数)
append(key, value)
# 在redis name对应的值后面追加内容 # 参数: key, redis的name value, 要追加的字符串
127.0.0.1:6379> set name sean OK 127.0.0.1:6379> APPEND name xin (integer) 7 127.0.0.1:6379> get name "seanxin"
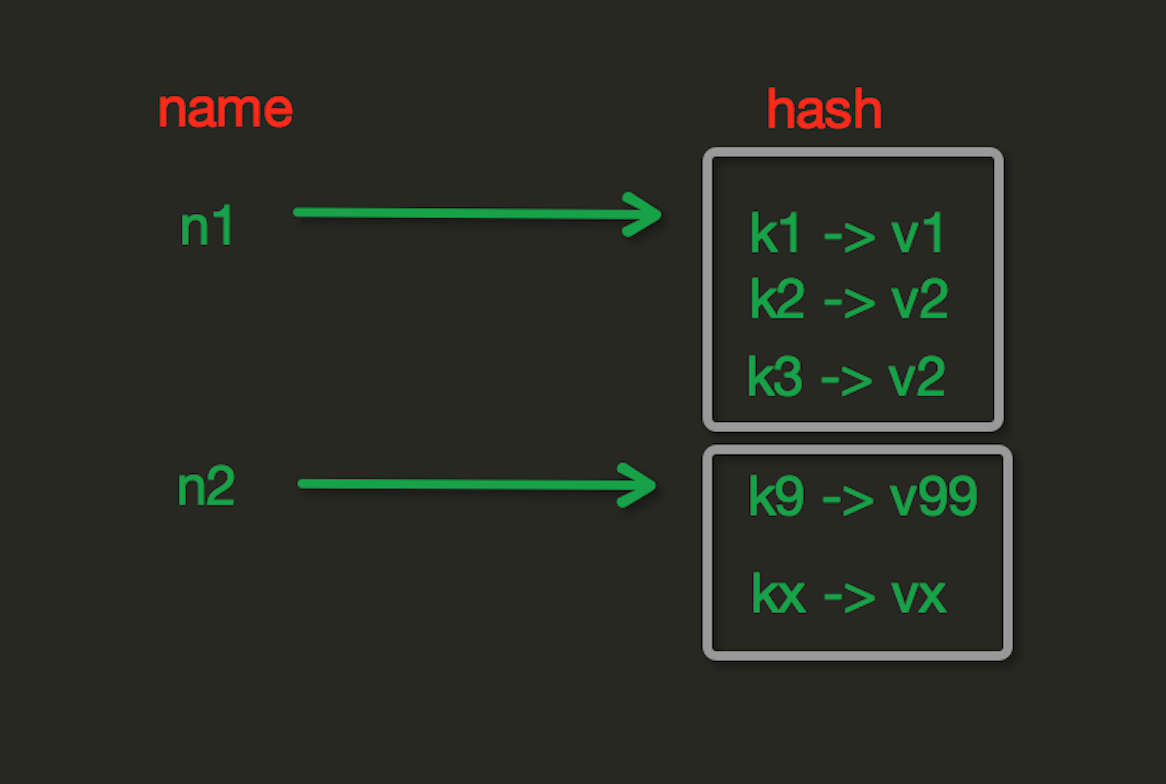
Hash操作,redis中Hash在内存中的存储格式如下图:
hash就是通过一些算法操作,把一个字符串生成一个唯一的数字串
hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数: # name,redis的name # key,name对应的hash中的key # value,name对应的hash中的value # 注: # hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
127.0.0.1:6379> HSET info name sean (integer) 1 127.0.0.1:6379> HSET info age 22 (integer) 1 127.0.0.1:6379> hset info id 999 (integer) 1 #获取单个 127.0.0.1:6379> HGET info id "999" #获取所有 127.0.0.1:6379> HGETALL info 1) "name" 2) "sean" 3) "age" 4) "22" 5) "id" 6) "999"
hkeys(name)
# 获取name对应的hash中所有的key的值
hvals(name)
# 获取name对应的hash中所有的value的值
hmset(name, mapping)
# 在name对应的hash中批量设置键值对 # 参数: # name,redis的name # mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如: # r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
127.0.0.1:6379> HMSET info2 n1 xiaoxin n2 ceshi OK 127.0.0.1:6379> HKEYS info2 1) "n1" 2) "n2" 127.0.0.1:6379> HVALS info2 1) "xiaoxin" 2) "ceshi"
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值 # 参数: # name,reids对应的name # keys,要获取key集合,如:['k1', 'k2', 'k3'] # *args,要获取的key,如:k1,k2,k3 # 如: # r.mget('xx', ['k1', 'k2']) # 或 # print r.hmget('xx', 'k1', 'k2')
127.0.0.1:6379> HMGET info2 n1 n2 1) "xiaoxin" 2) "ceshi"
hlen(name)
# 获取name对应的hash中键值对的个数
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key 有就返回1
127.0.0.1:6379> HEXISTS info2 n1 (integer) 1 127.0.0.1:6379> HEXISTS info2 n3 (integer) 0
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数: # name,redis中的name # key, hash对应的key # amount,自增数(整数)
127.0.0.1:6379> HGET info2 n1 "xiaoxin" # 如果这个key存在且对应的value不是数字,那么抛出异常 127.0.0.1:6379> HINCRBY info2 n1 1 (error) ERR hash value is not an integer 127.0.0.1:6379> HINCRBY info2 n3 1 (integer) 1 127.0.0.1:6379> HINCRBY info2 n3 1 (integer) 2 127.0.0.1:6379> HINCRBY info2 n3 1 (integer) 3 127.0.0.1:6379> HINCRBY info2 n3 1 (integer) 4
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数: # name,redis中的name # key, hash对应的key # amount,自增数(浮点数) # 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 # 参数: # name,redis的name # cursor,游标(基于游标分批取获取数据) # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None) # 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None) # ... # 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
白话:一个info里可以存放可以200亿个key,如果使用hkeys 查找出来消耗资源巨多,可以使用scan进行过滤查找了,
127.0.0.1:6379> HKEYS info2 1) "n1" 2) "n2" 3) "n3" 4) "name" 127.0.0.1:6379> hscan info2 0 match key* 1) "0" 2) (empty list or set) 127.0.0.1:6379> hscan info2 0 match n* 1) "0" 2) 1) "n1" 2) "xiaoxin" 3) "n2" 4) "ceshi" 5) "n3" 6) "4" 7) "name" 8) "xiaoxin"
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数: # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # for item in r.hscan_iter('xx'): # print item
白话:加入有200亿个key,扫描出来10亿个数据,还嫌多,就可以使用hscan_iter进行操作,生成结果是一个迭代器,在对这个结果进行循环
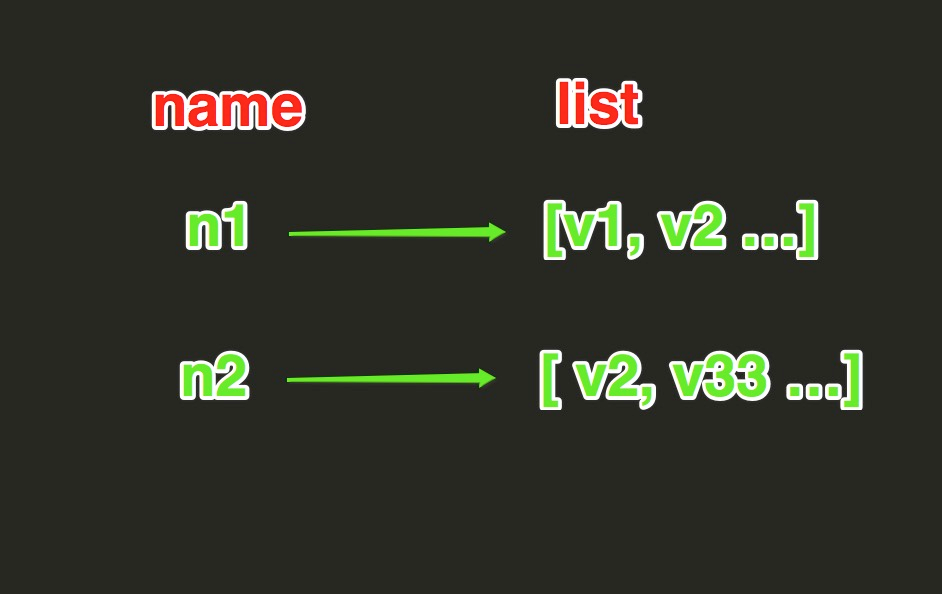
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
lpush(name,values) 先进后出
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 # 如: # r.lpush('oo', 11,22,33) # 保存顺序为: 33,22,11 # 扩展: # rpush(name, values) 表示从右向左操作
127.0.0.1:6379> LPUSH names sean hanyang xiaoxin jack
(integer) 4
lrange(name, start, end)
# 在name对应的列表分片获取数据 # 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置
127.0.0.1:6379> LRANGE names 0 -1 1) "jack" 2) "xiaoxin" 3) "hanyang" 4) "sean"
rpush(name,values) 先入先出
127.0.0.1:6379> RPUSH info3 sean hanyang xiao jack (integer) 4 127.0.0.1:6379> LRANGE info3 0 -1 1) "sean" 2) "hanyang" 3) "xiao" 4) "jack"
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边 # 更多: # rpushx(name, value) 表示从右向左操作
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值 # 参数: # name,redis的name # where,BEFORE或AFTER # refvalue,标杆值,即:在它前后插入数据 # value,要插入的数据
127.0.0.1:6379> LRANGE info3 0 -1 1) "sean" 2) "hanyang" 3) "xiao" 4) "jack" # 在sean之前插入一个ceshi 127.0.0.1:6379> LINSERT info3 before sean ceshi (integer) 5 127.0.0.1:6379> LRANGE info3 0 -1 1) "ceshi" 2) "sean" 3) "hanyang" 4) "xiao" 5) "jack" # 在sean之后插入一个ceshi 127.0.0.1:6379> LINSERT info3 after sean ceshi (integer) 6 127.0.0.1:6379> LRANGE info3 0 -1 1) "ceshi" 2) "sean" 3) "ceshi" 4) "hanyang" 5) "xiao" 6) "jack" 127.0.0.1:6379>
lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值 # 参数: # name,redis的name # index,list的索引位置 # value,要设置的值
127.0.0.1:6379> LRANGE info3 0 -1 1) "ceshi" 2) "sean" 3) "ceshi" 4) "hanyang" 5) "xiao" 6) "jack" # 把第三个值更改为HANYANG 127.0.0.1:6379> LSET info3 3 HANYANG OK 127.0.0.1:6379> LRANGE info3 0 -1 1) "ceshi" 2) "sean" 3) "ceshi" 4) "HANYANG" 5) "xiao" 6) "jack"
lrem(name, value, num)
# 在name对应的list中删除指定的值 # 参数: # name,redis的name # value,要删除的值 # num, num=0,删除列表中所有的指定值; # num=2,从前到后,删除2个; # num=-2,从后向前,删除2个
127.0.0.1:6379> LRANGE info3 0 -1 1) "ceshi" 2) "ceshi" 3) "sean" 4) "ceshi" 5) "HANYANG" 6) "xiao" 7) "jack" 127.0.0.1:6379> LREM info3 2 ceshi (integer) 2 127.0.0.1:6379> LRANGE info3 0 -1 1) "sean" 2) "ceshi" 3) "HANYANG" 4) "xiao" 5) "jack"
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是删除的元素 # 更多: # rpop(name) 表示从右向左操作
127.0.0.1:6379> LRANGE info3 0 -1 1) "sean" 2) "ceshi" 3) "HANYANG" 4) "xiao" 5) "jack" 127.0.0.1:6379> LPOP info3 "sean" 127.0.0.1:6379> LRANGE info3 0 -1 1) "ceshi" 2) "HANYANG" 3) "xiao" 4) "jack"
lindex(name, index)
# 在name对应的列表中根据索引获取列表元素
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值 # 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置
127.0.0.1:6379> LRANGE info3 0 -1 1) "ceshi" 2) "HANYANG" 3) "xiao" 4) "jack" 127.0.0.1:6379> LTRIM info3 1 2 OK 127.0.0.1:6379> LRANGE info3 0 -1 1) "HANYANG" 2) "xiao"
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边 # 参数: # src,要取数据的列表的name # dst,要添加数据的列表的name
127.0.0.1:6379> LRANGE info3 0 -1 1) "HANYANG" 2) "xiao" 127.0.0.1:6379> LRANGE info4 0 -1 1) "sean" 127.0.0.1:6379> RPOPLPUSH info3 info4 "xiao" 127.0.0.1:6379> LRANGE info3 0 -1 1) "HANYANG" 127.0.0.1:6379> LRANGE info4 0 -1 1) "xiao" 2) "sean"
blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素 # 参数: # keys,redis的name的集合 # timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞 # 更多: # r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧 # 参数: # src,取出并要移除元素的列表对应的name # dst,要插入元素的列表对应的name # timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞