一、直接寻址表
如果某应用要用到一个动态集合,其中每个元素都是全域U={0,1….,m}中的一个关键字 为表示动态集合,使用数组。称为直接寻址表,记为T[m],其中每个位置称为一个槽slot,对应于全域中的一个关键字。槽k指向集合中一个关键字为k的元素。如果该集合中没有关键字为k的元素,则T[k]=NIL;

1、直接寻址技术优点
当关键字的全域U比较小时,直接寻址是一种简单而有效的方法。
2、直接寻址技术缺点
当域U很大时,需要消耗大量内存,很不实际;
如果域U很大而实际出现的key很少,则大量空间被浪费;
无法处理关键字不是数字的情况。
3、将直接寻址表改进为哈希表
直接寻址表:key为k的元素放到k的位置上。
改进方法:
(1)构建大小为m的寻址表T;
(2)key为k的元素放到h(k)位置上;
(3)h(k)是一个函数,其将域U映射到表T[0,1,...,m-1]。
二、哈希表
在直接寻址表上加了一个哈希函数就成了哈希表。
哈希表(Hash Table,又称为散列表),是一种线性表的存储结构。哈希表由一个直接寻址表和一个哈希函数组成。哈希函数h(k)将k作为自变量,返回元素的存储下标。
假设有一个长度为7的哈希表,哈希函数h(k)=k%7。元素集合{14,22,3,5}的存储方式如下图:

14%7=0,因此14存在index=0的位置;22%7=1,因此22存在index=1的位置;3%7=3,因此3存在index=3的位置;5%7=5,因此5存在index=5的位置。
1、常见哈希函数
- 除法哈希法:h(k) = k mod m # mod就是% # 除留余数法
- 乘法哈希法:h(k) = floor(m*(A*key%1)) 0<A<1 # 对1取模也就是取它的小数部分, floor是向下去找
- 全域哈希法:ha,b(k) = ((a*key + b) mod p) mod m a,b=1,2,...,p-1
三、哈希冲突
由于哈希表的大小是有限的,而要存储的值的总数量是无限的,因此对于任何哈希函数,都会出现两个不同元素映射到同一个位置上的情况 ,这种情况叫做哈希冲突。
比如h(k)=k%7, h(0)=h(7)=h(14)=...
1、解决哈希冲突——开放寻址法
开放寻址法:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值。
线性探查:如果位置i被占用,则探查i+1,i+2,......
二次探查:如果位置i被占用,则探查i+12,i-12,i+22,i-22,......
二度哈希:有n个哈希函数,当使用第一个哈希函数h1发送冲突时,则尝试使用h2,h3,......
2、解决哈希冲突——拉链法
哈希表每个位置都连接一个链表,当冲突发生时,冲突的元素将被加到该位置链表的最后。
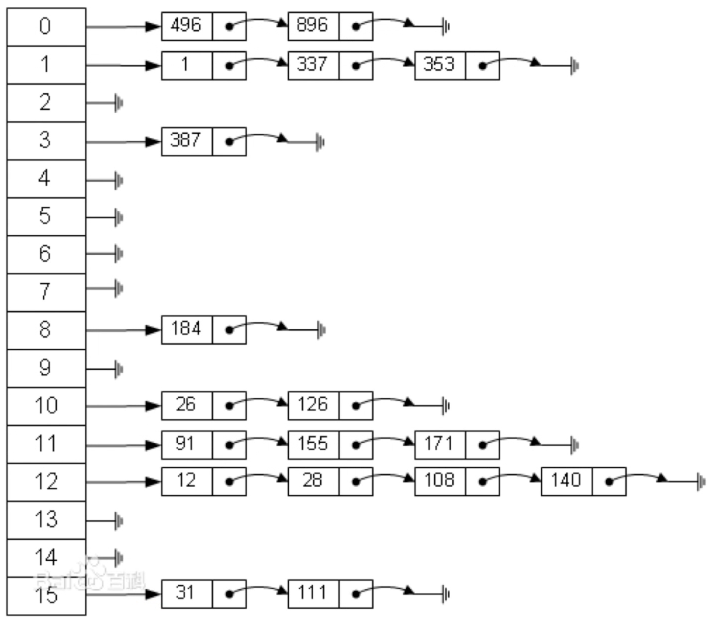
四、哈希表的实现
# -*- coding:utf-8 -*-
__author__ = 'Qiushi Huang'
class LinkList:
"""链表类"""
class Node:
"""链表中的节点"""
def __init__(self, item=None):
self.item = item
self.next = None
class LinkListIterator:
"""迭代器类"""
def __init__(self, node):
self.node = node
def __next__(self):
if self.node: # 如果node不为空
cur_node = self.node
self.node = cur_node.next # 更新node为下一个
return cur_node.item # 输出前一个node
else:
raise StopIteration
def __iter__(self):
return self
def __init__(self, iterable=None):
"""
构造函数
:param iterable: 传递的列表
"""
self.head = None
self.tail = None
if iterable:
self.extend(iterable)
def append(self, obj):
"""
插入节点
:param obj:要插入的对象
:return:
"""
s = LinkList.Node(obj)
if not self.head:
self.head = s
self.tail = s
else:
self.tail.next = s
self.tail = s
def extend(self, iterable):
for obj in iterable:
self.append(obj)
def find(self, obj):
for n in self:
if n == obj:
return True
else:
return False
def __iter__(self):
"""
如果一个类想被用于for ... in循环,类似list或tuple那样,就必须实现一个__iter__()方法
该方法返回一个迭代对象,然后,Python的for循环就会不断调用该迭代对象的__next__()方法拿到循环的下一个值,
直到遇到StopIteration错误时退出循环。
:return:
"""
return self.LinkListIterator(self.head)
def __repr__(self): # 转换为字符串
return "<<" + ", ".join(map(str, self)) + ">>"
# 哈希表做成类似集合的结构
class HashTable:
def __init__(self, size=101):
self.size = size
self.T = [LinkList() for i in range(self.size)] # 未传值时,LinkList()是一个空链表
def h(self, k): # 哈希函数
return k % self.size
def insert(self, k): # 插入函数
i = self.h(k)
if self.find(k):
print("Duplicated Insert")
else:
self.T[i].append(k)
def find(self, k): # 查找函数
i = self.h(k)
return self.T[i].find(k)
ht = HashTable()
ht.insert(0)
ht.insert(1)
ht.insert(0) # Duplicated Insert
ht.insert(3)
ht.insert(102) # 102%101=1
print(",".join(map(str, ht.T)))
print(ht.find(102))
"""
<<0>>,<<1, 102>>,<<>>,<<3>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,
<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,
<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,
<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,
<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>
True
"""
五、哈希表的应用
1、集合与字典
-
字典与集合都是通过哈希表来实现的,e.g. a={'name':'Alex', 'age':18, 'gender':'Man'}
- 使用哈希表存储字典,通过哈希函数将字典的键映射为下标。假设h('name')=3,h('age')=1,h('gender')=4,则哈希表存储为[None, 18, None, 'Alex', 'Man']
- 如果发生哈希冲突,则通过拉链法或开放寻址法解决
2、md5算法
MD5(Message-Digest Algorithm 5)曾经是密码学中常用的哈希函数,可以把任意长度的数据映射为128位的哈希值。
(1)MD5曾经包含如下特征
1)同样的消息,其MD5值必定相同;
2)可以快速计算出任意给定消息的MD5值;
3)除非暴力枚举所有可能的消息,否则不可能从哈希值反推出消息本身;
4)两条消息之间即使只有微小的差别,其对应的MD5值也应该是完全不同、完全不相关的;
5)不能在有意义的时间内人工地构造两个不同的消息,使其具有相同的MD5值。
(2)应用举例——文件的哈希值
算出文件的哈希值,若两个文件的哈希值相同,则可认为这两个文件是相同的。因此:
1)用户可以利用它来验证下载的文件是否完整。
2)云存储服务商可以利用它来判断用户要上传的文件是否已经存在于服务器上,从而实现秒传的功能,同时避免存储过多相同的文件副本。
3、SHA2算法
历史上MD5和SHA-1曾经是使用最为广泛的cryptographic hash function,但是随着密码学的发展,这两个哈希函数的安全性相继受到了各种挑战。
因此现在安全性较重要的场合推荐使用SHA-2等新的更安全的哈希函数。
SHA-2包含了一系列的哈希函数:SHA-224,SHA-256,SHA-384,SHA-512,SHA-512/224,SHA-512/256,其对应的哈希值长度分别为224,256,384or512位。
SHA-2具有与MD5类似的性质(参见MD5算法的特征)。
(1)应用举例
例如,在比特币系统中,所有参与者需要共同解决如下问题:对于一个给定的字符串U,给定的目标哈希值H,需要计算出一个字符串V,使得U+V的哈希值与H的差小于一个给定值D。此时,只能通过暴力枚举V来进行猜测。首先计算出结果的人可获得一定奖金。而某人首先计算成功的概率与其拥有的计算量成正比,所以其获得的奖金的期望值与其拥有的计算量成正比。