读完这篇博文,你能够收获什么?
- 从数据处理到利用朴素贝叶斯进行分类的整个过程
- 本文更关注于数据处理阶段,朴素贝叶斯模型直接使用sklearn库中自带的
先给出整个算法的流程:
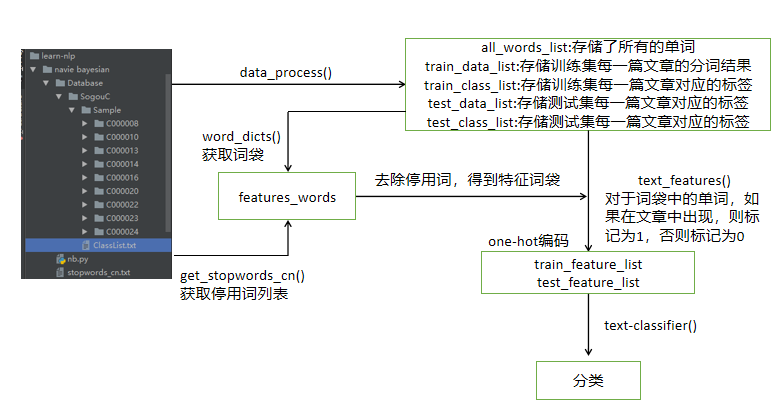
采用的是sogou语料库的部分数据,每个C开头的文件各代表一类,里面包含着若干篇txt类型的文章,具体类别如下:

1.数据审视阶段(查看是否有不符合规范或异常的数据),由于我们这里的数据是比较规整的,就直接进行下一阶段了;
2.要想训练一个模型,我们必须得有训练集和测试集。我们要明确训练集和测试集里面是什么。这里,我们使用的是词袋,即包含有不同单词的列表。
首先导入相应的包:
#用于处理文件路径 import os #用于打乱数据,产生随机的训练集和测试集 import random #用于分词 import jieba #朴素贝叶斯模型 from sklearn.naive_bayes import MultinomialNB
然后是词袋模型的建立:
def data_process(): #获取当前文件的绝对路径 cur_path = os.path.dirname(os.path.abspath(__file__)) #定位包含数据的那级目录 path = cur_path + '/Database/SogouC/Sample/' #测试集占总数据的百分比 test_size = 0.2 #Sample下的所有文件 folder_list = os.listdir(path) #存储分词后的列表 data_list =[] #存储标签列表 class_list = [] #遍历C000008等类型的文件夹 for folder in folder_list: #取得该文件夹绝对路径 new_folder_path = os.path.join(path,folder) #取得该文件夹下所有txt类型的数据,并返回 files=os.listdir(new_folder_path) #读取txt文件 for file in files: #打开txt文件 with open(os.path.join(new_folder_path,file),'r',encoding='utf-8') as fp: #读取里面的内容 raw = fp.read() #进行结巴分词 word_cut=jieba.cut(raw,cut_all=False) #将分词后的结果转成列表,即单词列表 word_list=list(word_cut) #将该文件夹下的所有txt分词后添加到data_list中 data_list.append(word_list) #获得标签列表,就是文件夹名称 class_list.append(folder) #将分词列表和标签对应并返回 data_class_list = list(zip(data_list,class_list)) #打乱数据以获得随机的训练集和测试集 random.shuffle(data_class_list) #通过索引来切分数据 index = int(len(data_class_list)*test_size)+1 #训练集(包含数据和标签) train_list=data_class_list[index:] #测试集(包含数据和标签 test_list=data_class_list[:index] #拆分 train_data_list,train_class_list=zip(*train_list) #拆分 test_data_list,test_class_list=zip(*test_list) #取得所有文章分词后构成的词袋 all_words_dict ={} #取得训练集中的每一篇分词后的列表 for word_list in train_data_list: #取得每一个单词 for word in word_list: #判断是否存在于词袋中,如果没有,则出现次数为1,否则+1 if word in all_words_dict: all_words_dict[word]+=1 else: all_words_dict[word]=1 #将所有词语按出现次数由大到小排列 all_words_tuple_dict=sorted(all_words_dict.items(),key=lambda x:x[1],reverse=True) #取出单词,并转为列表 all_words_list=list(list(zip(*all_words_tuple_dict))[0]) #返回词袋,训练集,训练集标签,测试集,测试集标签 return all_words_list,train_data_list,train_class_list,test_data_list,test_class_list

我们虽然得到了词袋模型,但是,我们发现里面的词并不是我们所需要的,我们还要进行下一步操作:去除一些不必要的词和一些没有意义的词,这里得用到stopwods_cn.txt:

上图展示的是部分停用词。首先,我们必须从txt中获得停用词列表:
def get_stopwords_cn(): stopwords_cn_path = os.path.dirname(os.path.abspath(__file__)) + "\stopwords_cn.txt" with open(stopwords_cn_path,'r',encoding='utf-8') as fp: stopwords_cn=fp.read().split(" ") return set(stopwords_cn)
然后,我们词袋中的每一个单词,如果不在停用词中,就加入到新的列表中:
def word_dicts(all_words_list,deleteN,stopwords_set=set()): #用来存储不位于停词中的单词 features_words=[] #用于指定词袋的长度 n=1 for t in range(deleteN,len(all_words_list),1):
#限定词袋的长度为1000 if n>1000: break #如果不是数字且不在停词列表中且1<长度<5 if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1<len(all_words_list[t])<5: #加入到新的词袋中 features_words.append(all_words_list[t]) n+=1 return features_words
接下来,我们得到修正过后的词袋后,还需要将原本文章的分词列表转换成One-hot编码,这才是我们真正需要的特征:
def text_features(train_data_list,test_data_list,features_words): #text是每一条train_data_list中或test_data_list的数据 #辅助函数 def helper(text,features_words): #首先过滤掉重复的值 text_words = set(text) #如果该词位于词袋中,则编码成1,否则为0 features = [1 if word in text_words else 0 for word in features_words] return features #对训练集进行编码 train_feature_list=[helper(text,features_words) for text in train_data_list] #对测试集进行编码 test_feature_list = [helper(text, features_words) for text in test_data_list] #返回新的特征 return train_feature_list,test_feature_list
我们已经拥有特征了,最后需要定义朴素贝叶斯模型:
def text_classifier(train_feature_list,train_class_list,test_feature_list,test_class_list): classifier = MultinomialNB().fit(train_feature_list,train_class_list) test_accuracy=classifier.score(test_feature_list,test_class_list) print(classifier.predict(test_feature_list)) print(test_class_list) return test_accuracy
最后,将所有部件组合起来,就大功告成了:
def main(): all_words_list, train_data_list, train_class_list, test_data_list, test_class_list = data_process() #去除掉停用词 features_words = word_dicts(all_words_list,0,get_stopwords_cn()) train_feature_list, test_feature_list=text_features(train_data_list,test_data_list,features_words) accuracy = text_classifier(train_feature_list,train_class_list,test_feature_list,test_class_list) print(accuracy) if __name__ == '__main__': main()
我们来看下输出:

由于只是个较为基础的实现,所以准确率并不算太高,最主要的还是掌握整个过程。虽然代码比较多,但是画了流程图和基本上都会有注释,看起来应该会简单些。
相关代码和资料:链接: https://pan.baidu.com/s/1odwgJ8Vy_h1QyMrWpsi68Q 提取码: d74g