1、安装hugging face的transformers
pip install transformers
2、下载相关文件
字表:
wget http://52.216.242.246/models.huggingface.co/bert/bert-base-uncased-vocab.txt
配置文件:
wget http://52.216.242.246/models.huggingface.co/bert/bert-base-uncased-config.json
模型文件:
wget http://52.216.242.246/models.huggingface.co/bert/bert-base-uncased-pytorch_model.bin
3、数据集
simplifyweibo_4_moods数据集:
数据集下载地址: https://pan.baidu.com/s/16c93E5x373nsGozyWevITg
36 万多条,带情感标注,包含 4 种情感,其中喜悦约 20 万条,愤怒、厌恶、低落各约 5 万条
0:喜悦 1:愤怒 2:厌恶 3:低落

4、完整代码
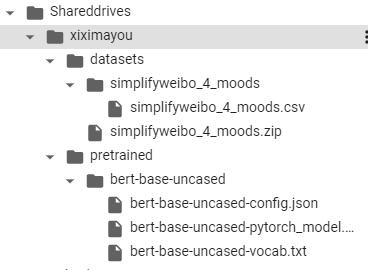
目录结构:谷歌colab中

import os import pprint import numpy as np import pandas as pd import random from transformers import BertTokenizer,BertConfig,BertForSequenceClassification,AdamW,AutoTokenizer,AutoModel from transformers import get_linear_schedule_with_warmup from sklearn.metrics import accuracy_score from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split import torch from torch.utils.data import TensorDataset, DataLoader class MyBertModel: def __init__(self, train, vocab_path, config_path, pretrain_Model_path, saveModel_path, learning_rate, n_class,epochs, batch_size, val_batch_size, max_len, gpu=True): self.n_class = n_class #类别数 self.max_len = max_len #句子最大长度 self.lr = learning_rate #学习率 self.epochs = epochs self.tokenizer = BertTokenizer.from_pretrained(vocab_path) #加载分词模型 text_list, labels = self.load_data(train) #加载训练数据集 train_x, val_x, train_y, val_y = self.split_train_val(text_list, labels) self.train = self.process_data(train_x, train_y) self.validation = self.process_data(val_x, val_y) self.batch_size = batch_size #训练集的batch_size self.val_batch_size = val_batch_size self.saveModel_path = saveModel_path #模型存储位置 self.gpu = gpu #是否使用gpu config = BertConfig.from_json_file(config_path) #加载bert模型配置信息 config.num_labels = n_class #设置分类模型的输出个数 self.model = BertForSequenceClassification.from_pretrained(pretrain_Model_path,config=config) #加载bert分类模型 if self.gpu: seed = 42 random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.deterministic = True self.device = torch.device('cuda') else: self.device = 'cpu' def encode_fn(self,text_list): #将text_list embedding成bert模型可用的输入形式 #text_list:['我爱你','猫不是狗'] tokenizer = self.tokenizer( text_list, padding = True, truncation = True, max_length = self.max_len, return_tensors='pt' # 返回的类型为pytorch tensor ) input_ids = tokenizer['input_ids'] token_type_ids = tokenizer['token_type_ids'] attention_mask = tokenizer['attention_mask'] return input_ids,token_type_ids,attention_mask def load_data(self,path): df = pd.read_csv(path) text_list = df['review'].to_list() labels = df['label'].to_list() return text_list, labels def process_data(self, text_list, labels): input_ids,token_type_ids,attention_mask = self.encode_fn(text_list) labels = torch.tensor(labels) data = TensorDataset(input_ids,token_type_ids,attention_mask,labels) return data def split_train_val(self, data, labels): train_x, val_x, train_y, val_y = train_test_split(data, labels, test_size = 0.2, random_state = 0) return train_x, val_x, train_y, val_y def flat_accuracy(self, preds, labels): """A function for calculating accuracy scores""" pred_flat = np.argmax(preds, axis=1).flatten() labels_flat = labels.flatten() return accuracy_score(labels_flat, pred_flat) def train_model(self): #训练模型 if self.gpu: self.model.cuda() optimizer = AdamW(self.model.parameters(), lr=self.lr) trainData = DataLoader(self.train, batch_size = self.batch_size, shuffle = True) #处理成多个batch的形式 valData = DataLoader(self.validation, batch_size = self.val_batch_size, shuffle = True) total_steps = len(trainData) * self.epochs scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps) for epoch in range(self.epochs): self.model.train() total_loss, total_val_loss = 0, 0 total_eval_accuracy = 0 print('epoch:' , epoch , ', step_number:' , len(trainData)) #训练 for step,batch in enumerate(trainData): outputs = self.model(input_ids = batch[0].to(self.device), token_type_ids=batch[1].to(self.device), attention_mask=batch[2].to(self.device), labels=batch[3].to(self.device) ) #输出loss 和 每个分类对应的输出,softmax后才是预测是对应分类的概率 loss, logits = outputs.loss, outputs.logits total_loss += loss.item() loss.backward() torch.nn.utils.clip_grad_norm_(self.model.parameters(), 1.0) optimizer.step() scheduler.step() if step % 10 == 0 and step > 0: #每10步输出一下训练的结果,flat_accuracy()会对logits进行softmax self.model.eval() logits = logits.detach().cpu().numpy() label_ids = batch[3].cuda().data.cpu().numpy() avg_val_accuracy = self.flat_accuracy(logits, label_ids) print('step:' , step) print(f'Accuracy: {avg_val_accuracy:.4f}') print(' ') #每个epoch结束,就使用validation数据集评估一次模型 self.model.eval() print('testing ....') for i, batch in enumerate(valData): with torch.no_grad(): loss, logits = self.model(input_ids=batch[0].to(self.device), token_type_ids=batch[1].to(self.device), attention_mask=batch[2].to(self.device), labels=batch[3].to(self.device) ) total_val_loss += loss.item() logits = logits.detach().cpu().numpy() label_ids = batch[3].cuda().data.cpu().numpy() total_eval_accuracy += self.flat_accuracy(logits, label_ids) avg_train_loss = total_loss / len(trainData) avg_val_loss = total_val_loss / len(valData) avg_val_accuracy = total_eval_accuracy / len(valData) print(f'Train loss : {avg_train_loss}') print(f'Validation loss: {avg_val_loss}') print(f'Accuracy: {avg_val_accuracy:.4f}') print(' ') self.save_model(self.saveModel_path + '-' + str(epoch)) def save_model(self , path): #保存分词模型和分类模型 self.model.save_pretrained(path) self.tokenizer.save_pretrained(path) def load_model(self,path): #加载分词模型和分类模型 tokenizer = AutoTokenizer.from_pretrained(path) model = BertForSequenceClassification.from_pretrained(path) return tokenizer,model def eval_model(self,Tokenizer, model,text_list,y_true): #输出模型的召回率、准确率、f1-score preds = self.predict_batch(Tokenizer, model, text_list) print(classification_report(y_true,preds)) def predict_batch(self, Tokenizer, model, text_list): tokenizer = Tokenizer( text_list, padding = True, truncation = True, max_length = self.max_len, return_tensors='pt' # 返回的类型为pytorch tensor ) input_ids = tokenizer['input_ids'] token_type_ids = tokenizer['token_type_ids'] attention_mask = tokenizer['attention_mask'] pred_data = TensorDataset(input_ids,token_type_ids,attention_mask) pred_dataloader = DataLoader(pred_data, batch_size=self.batch_size, shuffle=False) model = model.to(self.device) model.eval() preds = [] for i, batch in enumerate(pred_dataloader): with torch.no_grad(): outputs = model(input_ids=batch[0].to(self.device), token_type_ids=batch[1].to(self.device), attention_mask=batch[2].to(self.device) ) logits = outputs[0] logits = logits.detach().cpu().numpy() preds += list(np.argmax(logits, axis=1)) return preds if __name__ == '__main__': epoch = 3 pretrained_path = "/content/drive/Shareddrives/xiximayou/pretrained/bert-base-uncased" dataset_path = "/content/drive/Shareddrives/xiximayou/datasets" save_path = "/content/drive/MyDrive/test_hugging face/checkpoint" train_path = os.path.join(dataset_path, "simplifyweibo_4_moods/simplifyweibo_4_moods.csv") save_model_path = os.path.join(dataset_path, "pt/bert-base-uncased") bert_tokenizer_path = os.path.join(pretrained_path, "bert-base-uncased-vocab.txt") bert_config_path = os.path.join(pretrained_path, "bert-base-uncased-config.json") bert_model_path = os.path.join(pretrained_path, "bert-base-uncased-pytorch_model.bin") model_name = "bert_weibo" myBertModel = MyBertModel( train = train_path, vocab_path = bert_tokenizer_path, config_path = bert_config_path, pretrain_Model_path = bert_model_path, saveModel_path = os.path.join(save_model_path, model_name), learning_rate = 2e-5, n_class = 4, epochs = epoch, batch_size = 4, val_batch_size = 4, max_len = 100 , gpu = True ) myBertModel.train_model() Tokenizer, model = myBertModel.load_model(myBertModel.saveModel_path + '-'+ str(epoch-1)) #text_list, y_true = myBertModel.load_data_predict('xxx.csv') #myBertModel.eval_model(Tokenizer, model,text_list,y_true)
使用模型得到的输出是:
SequenceClassifierOutput(loss=tensor(1.2209, device='cuda:0', grad_fn=<NllLossBackward>), logits=tensor([[-0.0275, -0.2090, -0.1251, -0.2942], [ 0.0310, -0.2028, -0.1399, -0.3605], [-0.0671, -0.3543, -0.1225, -0.4625], [ 0.1389, -0.1244, -0.2310, -0.3664]], device='cuda:0', grad_fn=<AddmmBackward>), hidden_states=None, attentions=None)
因此我们使用outputs.loss和outputs.logits来获得相关的值。
其余的代码也没什么特别的地方,主要关注下:
- tokenizer的输入和输出;
- warm up的使用;
- 使用的模型接口是BertForSequenceClassification,我们只需要修改类别数为自己的类别就行了,这里的类别是4,
相关的函数可以去查一下文档:
关于更多的模型可以去以下地方找到其对应的名字以及预训练的模型:
在使用各种模型的时候,我们要注意他们的输入和输出是什么,然后套用相应的框架就可以了。
处理输入数据时,我们也可以使用这种方式:
from transformers import ( DataProcessor, InputExample, BertConfig, BertTokenizer, BertForSequenceClassification, glue_convert_examples_to_features, ) import torch.nn as nn import torch
class Processor(DataProcessor): def __init__(self): super(DataProcessor,self).__init__() """实体链接数据处理""" def get_train_examples(self, inputexample): return self._create_examples( lines, labels, set_type='train', ) def get_test_examples(self, inputexample): return self._create_examples( lines, labels, set_type='test', ) def get_labels(self): return [0, 1] def _create_examples(self, lines, labels,set_type):# 将 document_examples=[] for i, document in enumerate(lines): sentence_examples = [] for j,sentence in enumerate(document): guid = f'{set_type}-{i}-{j}' text_a = sentence label = labels[i][j] sentence_examples.append(InputExample( guid=guid, text_a=text_a, label=label, )) document_examples.append(sentence_examples) return document_examples def _create_features(self,document_examples): features = [] for document_example in document_examples: examples = document_example document_features = glue_convert_examples_to_features( examples, tokenizer, max_length=30, label_list=get_labels(), output_mode= 'classification' ) features.append(document_features) return features def creat_train_dataloader(self,train_features): dataloader =[] for document_features in train_features: input_ids = torch.LongTensor([f.input_ids for f in document_features]) attention_mask = torch.LongTensor([f.attention_mask for f in document_features]) token_type_ids = torch.LongTensor([f.token_type_ids for f in document_features]) labels = torch.LongTensor([f.label for f in document_features]) batch = [input_ids,attention_mask,token_type_ids,labels] dataloader.append(batch) return dataloader
def generate_dataloader(self,data): train_dataloader = self.creat_train_dataloader(self._create_features((self._create_examples(data[0],data[1],'train')))) valid_dataloader = self.creat_train_dataloader(self._create_features((self._create_examples(data[2],data[3],'valid')))) test_dataloader = self.creat_train_dataloader(self._create_features((self._create_examples(data[4],data[5],'test')))) return train_dataloader,valid_dataloader,test_dataloader
继承DataProcessor类
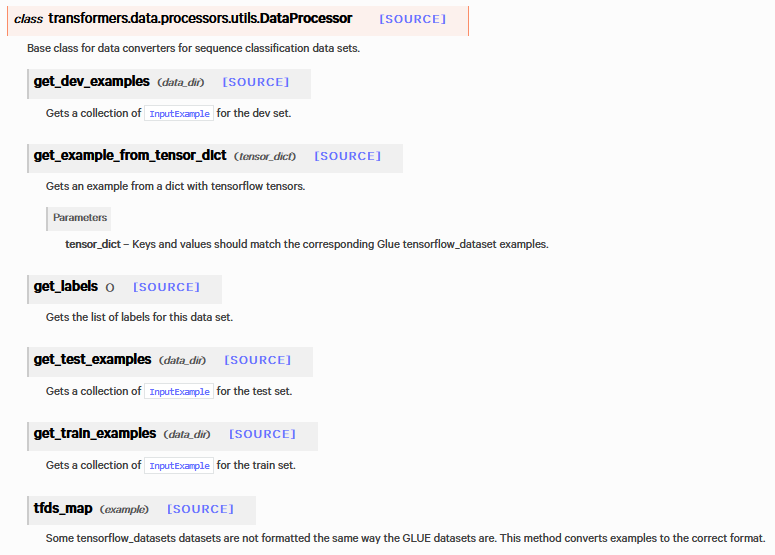
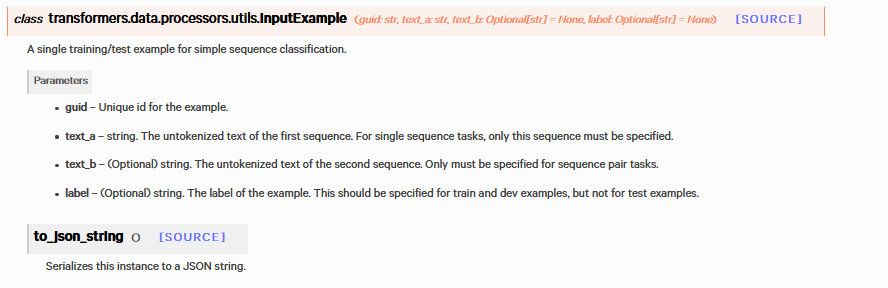
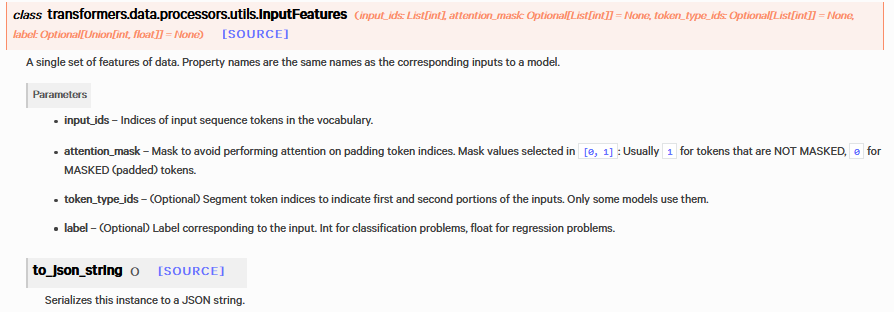
参考:
https://blog.csdn.net/weixin_38471579/article/details/108239629
https://blog.csdn.net/qq_43645301/article/details/108811403