导读:推荐系统技术,总体而言,与 NLP 和图像领域比,发展速度不算太快。不过最近两年,由于深度学习等一些新技术的引入,总体还是表现出了一些比较明显的技术发展趋势。这篇文章试图从推荐系统几个环节,以及不同的技术角度,来对目前推荐技术的比较彰显的技术趋势做个归纳。个人判断较多,偏颇难免,所以还请谨慎参考。
在写技术趋势前,照例还是对推荐系统的宏观架构做个简单说明,以免读者迷失在技术细节中。
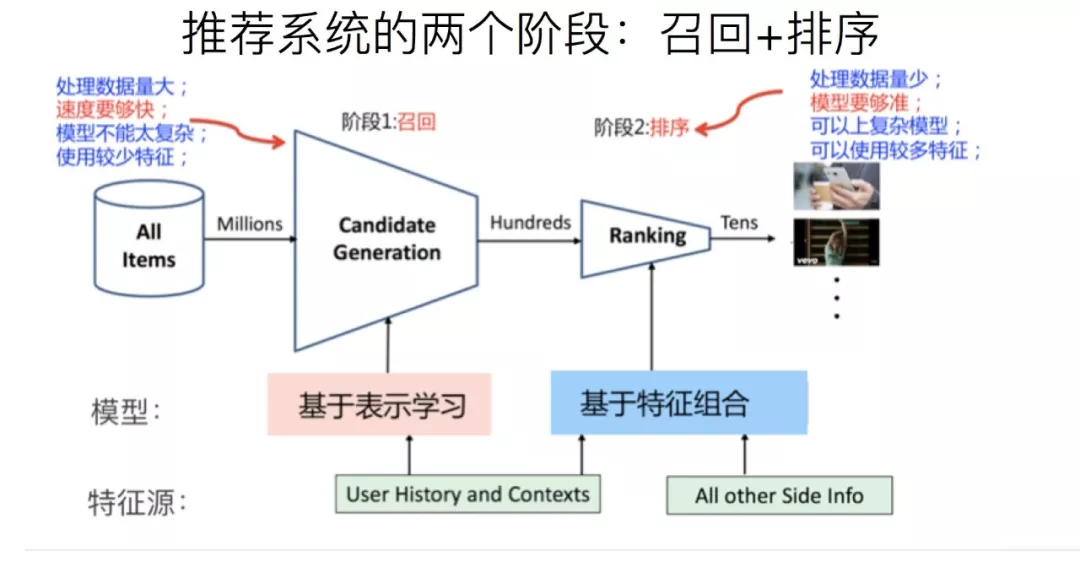
实际的工业推荐系统,如果粗分的化,经常讲的有两个阶段。首先是召回,主要根据用户部分特征,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品,然后交给排序环节,排序环节可以融入较多特征,使用复杂模型,来精准地做个性化推荐。召回强调快,排序强调准。当然,这是传统角度看推荐这个事情。
但是,如果我们更细致地看实用的推荐系统,一般会有四个环节,--召回---粗排--精排--重排
实际的工业推荐系统,如果粗分的化,经常讲的有两个阶段。首先是召回,主要根据用户部分特征,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品,然后交给排序环节,排序环节可以融入较多特征,使用复杂模型,来精准地做个性化推荐。召回强调快,排序强调准。当然,这是传统角度看推荐这个事情。
但是,如果我们更细致地看实用的推荐系统,一般会有四个环节,如下图所示:

:
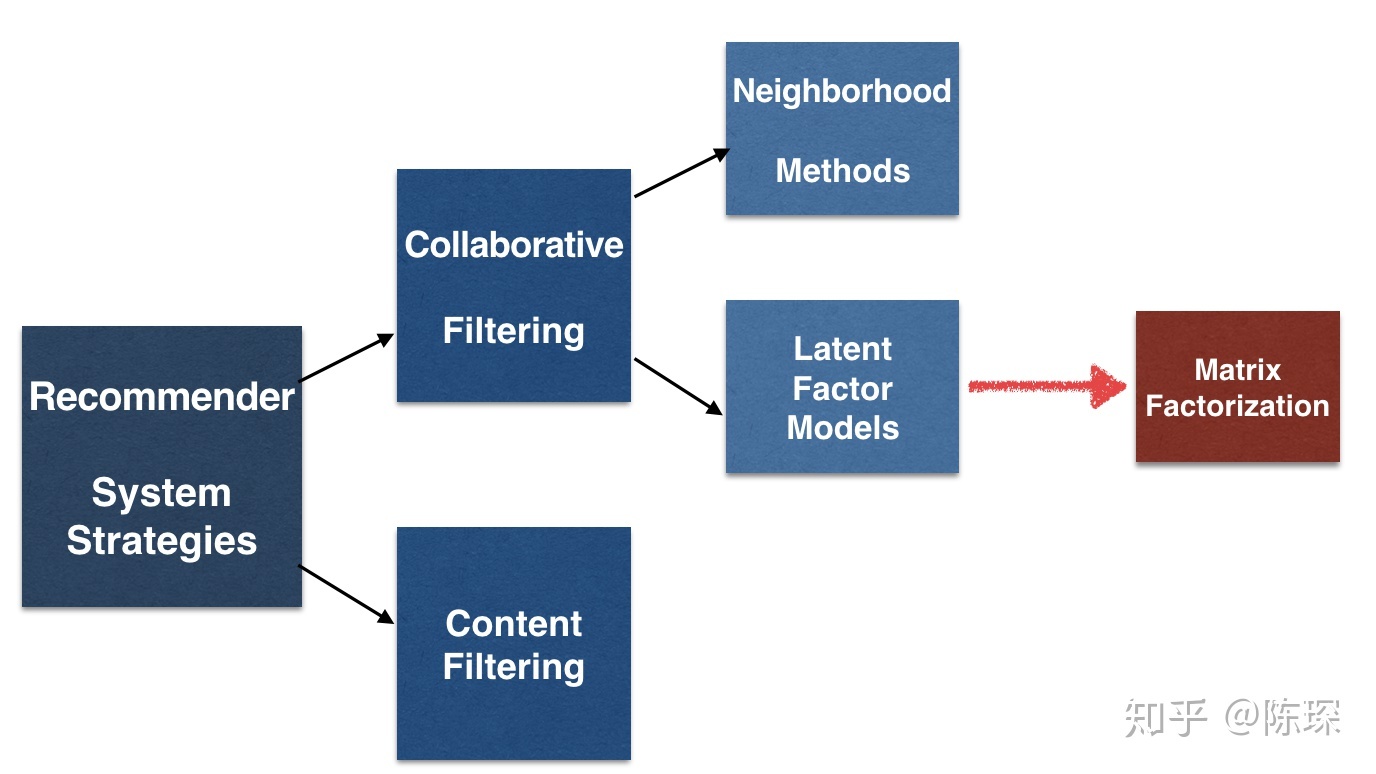
传统的标准召回结构一般是多路召回,如上图所示。如果我们根据召回路是否有用户个性化因素存在来划分,可以分成两大类:一类是无个性化因素的召回路,比如热门商品或者热门文章或者历史点击率高的物料的召回;另外一类是包含个性化因素的召回路,比如用户兴趣标签召回。我们应该怎么看待包含个性化因素的召回路呢?其实吧,你可以这么看,可以把某个召回路看作是:单特征模型排序的排序结果。意思是,可以把某路召回,看成是某个排序模型的排序结果,只不过,这个排序模型,在用户侧和物品侧只用了一个特征。比如说,标签召回,其实就是用用户兴趣标签和物品标签进行排序的单特征排序结果;再比如协同召回,可以看成是只包含 UID 和 ItemID 的两个特征的排序结果….诸如此类。我们应该统一从排序的角度来看待推荐系统的各个环节,这样可能会更好理解本文所讲述的一些技术。
如果我们换做上面的角度看待有个性化因素召回路,那么在召回阶段引入模型,就是自然而然的一个拓展结果:无非是把单特征排序,拓展成多特征排序的模型而已;而多路召回,则可以通过引入多特征,被融入到独立的召回模型中,找到它的替代品。如此而已。所以,随着技术的发展,在 embedding 基础上的模型化召回,必然是个符合技术发展潮流的方向。