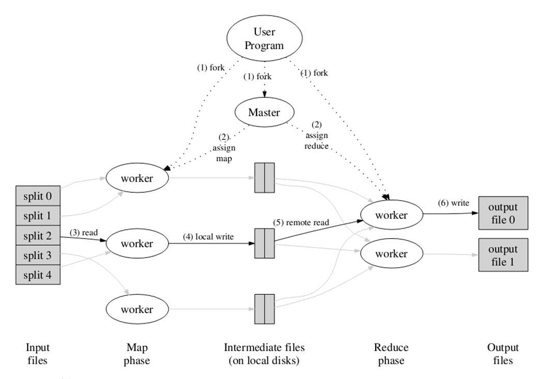
一.MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。分别有:
"Map(映射)"和"Reduce(归约)"
Map的作用是过滤一些原始数据,Reduce则是处理这些数据,得到我们想要的结果,
二.mapreduce实现图的BFS图示
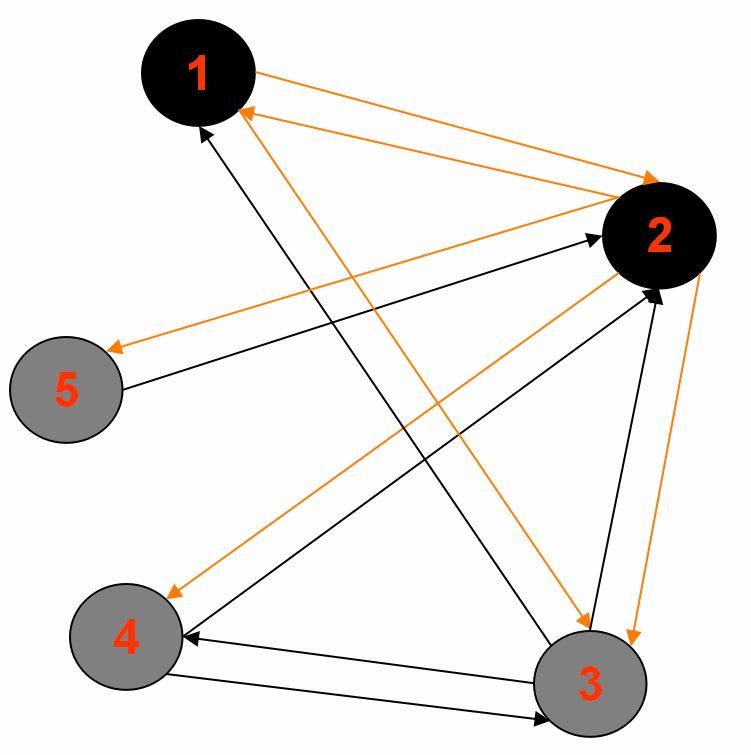
要遍历的图:
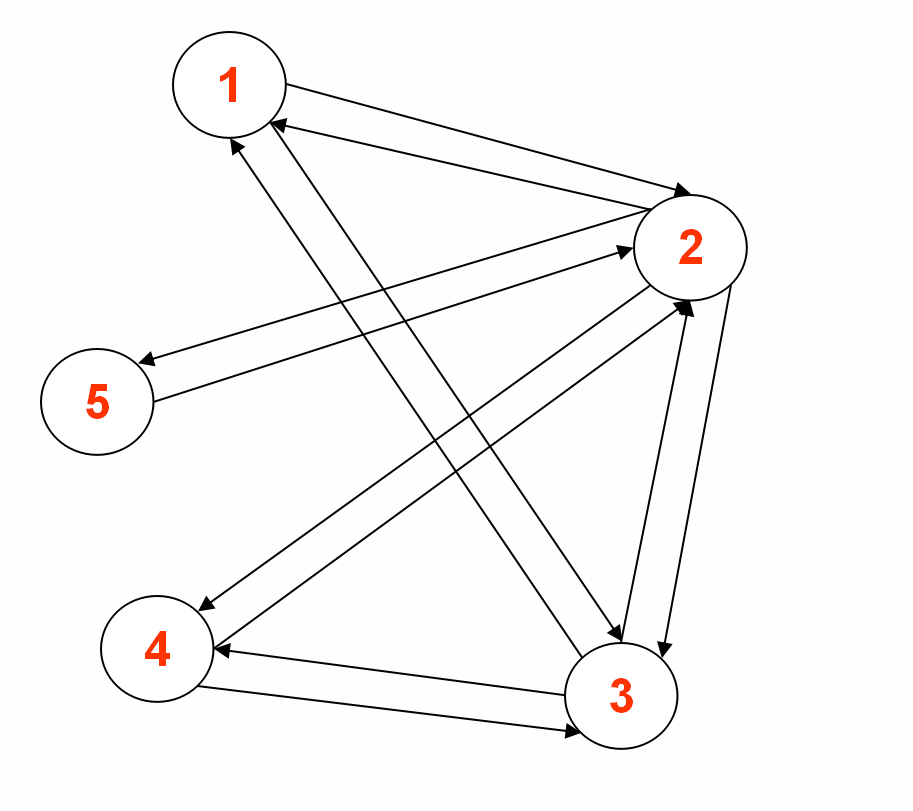
输入样例:
1<tab>2,3|0|GRAY|source
2<tab>1,3,4,5|Integer.MAX_VALUE|WHITE|null
3<tab>1,4,2|Integer.MAX_VALUE|WHITE|null
4<tab>2,3|Integer.MAX_VALUE|WHITE|null
5<tab>2|Integer.MAX_VALUE|WHITE|null
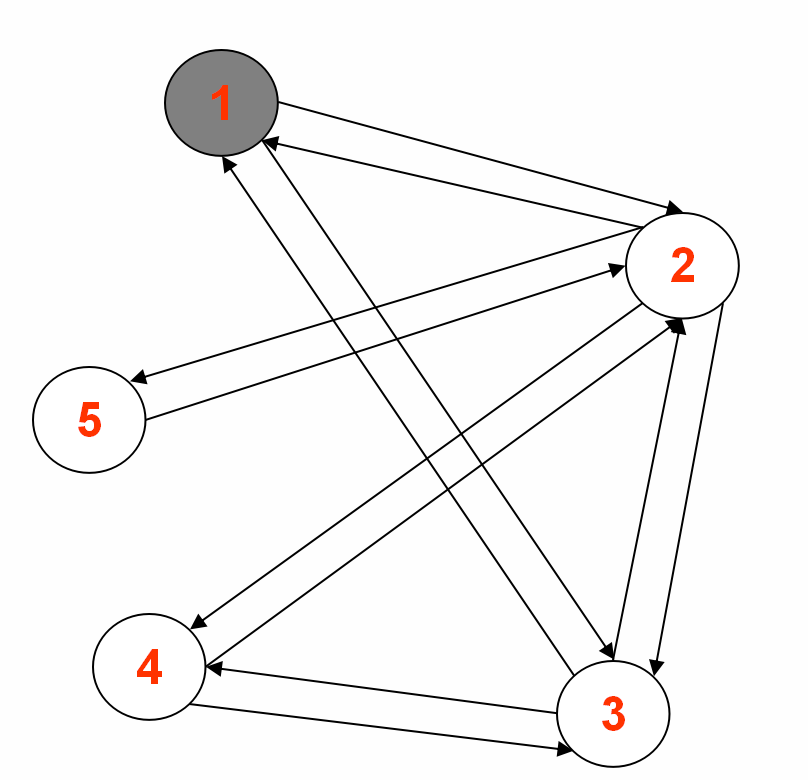
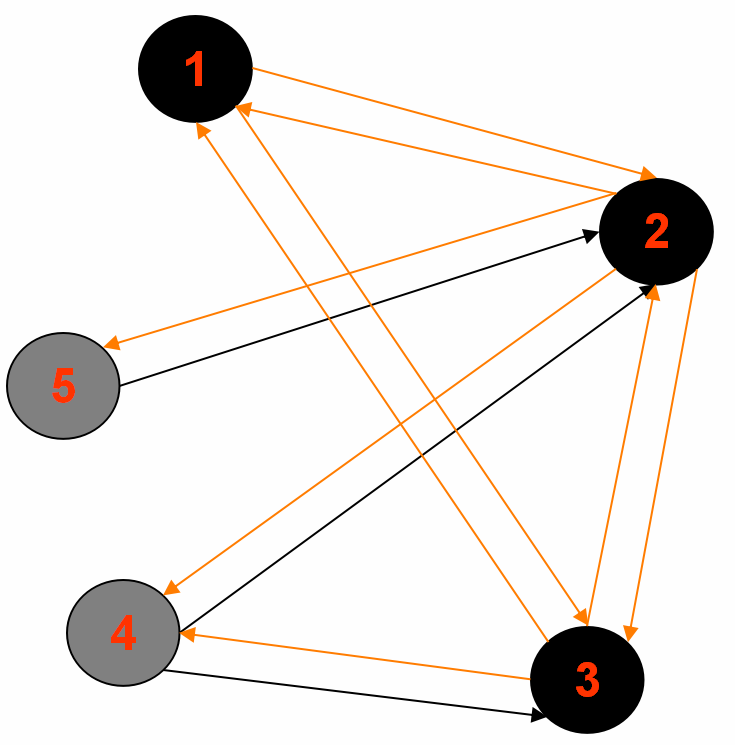
1.中间输出1:
Reducer 1: (part-r-00000)
2<tab>1,3,4,5,|1|GRAY|1
5<tab>2,|Integer.MAX_VALUE|WHITE|null
Reducer 2: (part-r-00001)
3<tab>1,4,2,|1|GRAY|1
Reducer 3: (part-r-00002)
1<tab>2,3,|0|BLACK|source
4<tab>2,3,|Integer.MAX_VALUE|WHITE|null
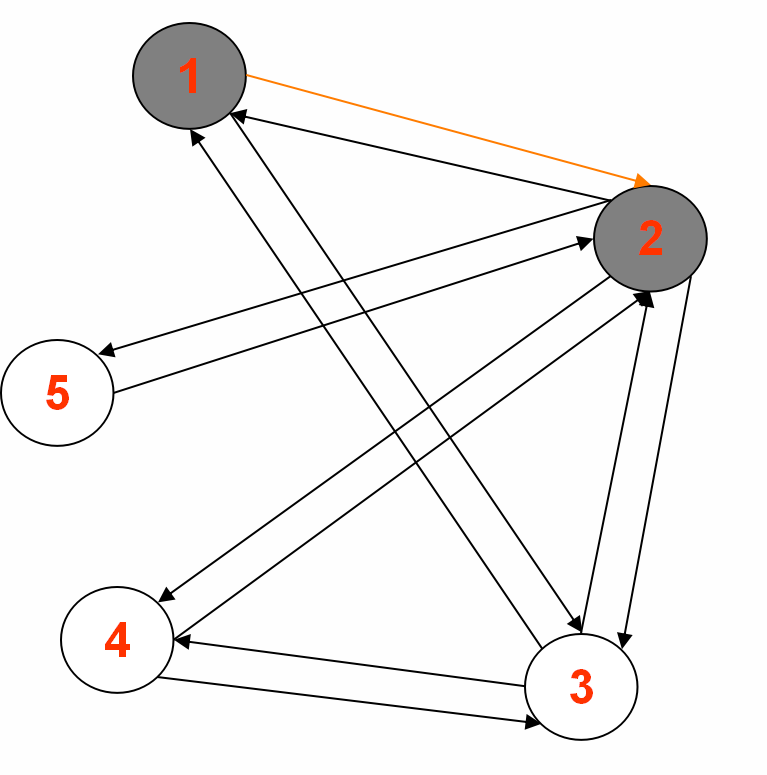
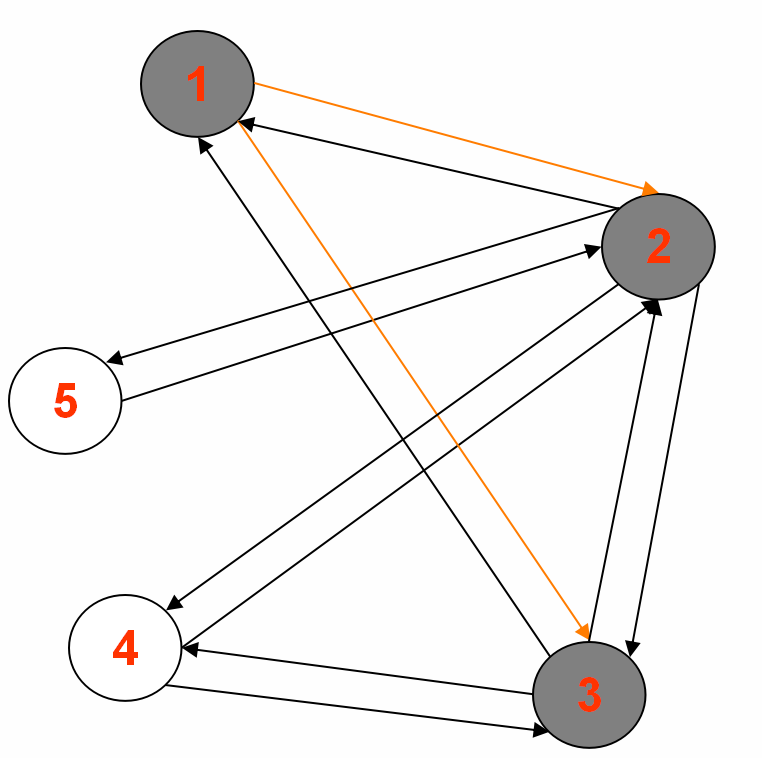
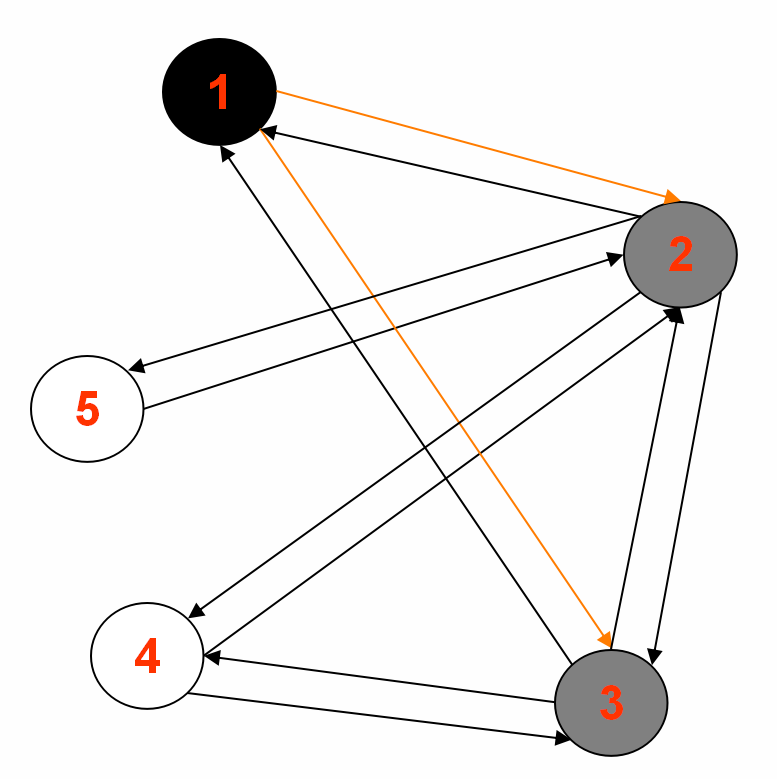
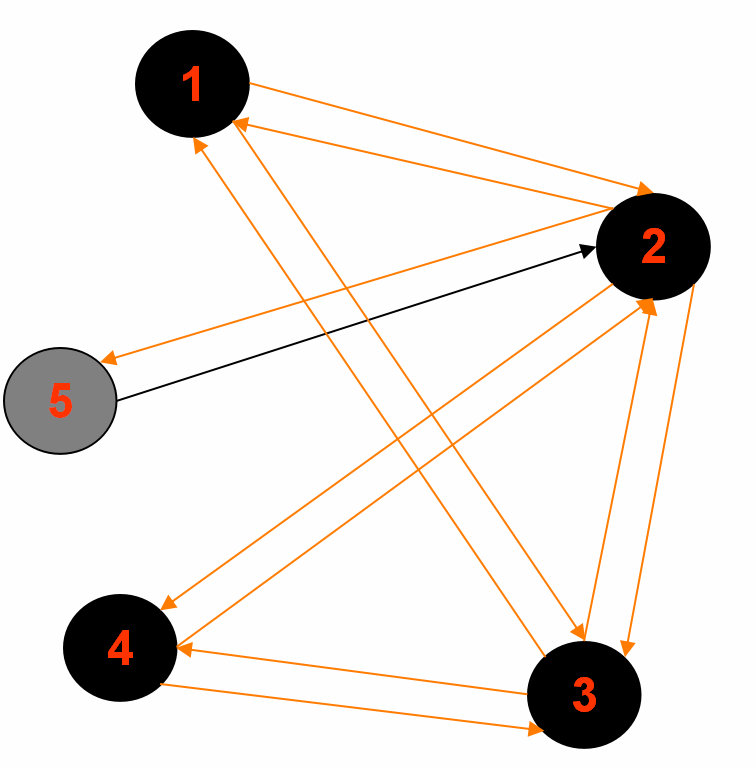
2.中间输出2:
Reducer 1: (part-r-00000)
2<tab>1,3,4,5,|1|BLACK|1
5<tab>2,|2|GRAY|2
Reducer 2: (part-r-00001)
3<tab>1,4,2,|1|BLACK|1
Reducer 3: (part-r-00002)
1<tab>2,3,|0|BLACK|source
4<tab>2,3,|2|GRAY|2
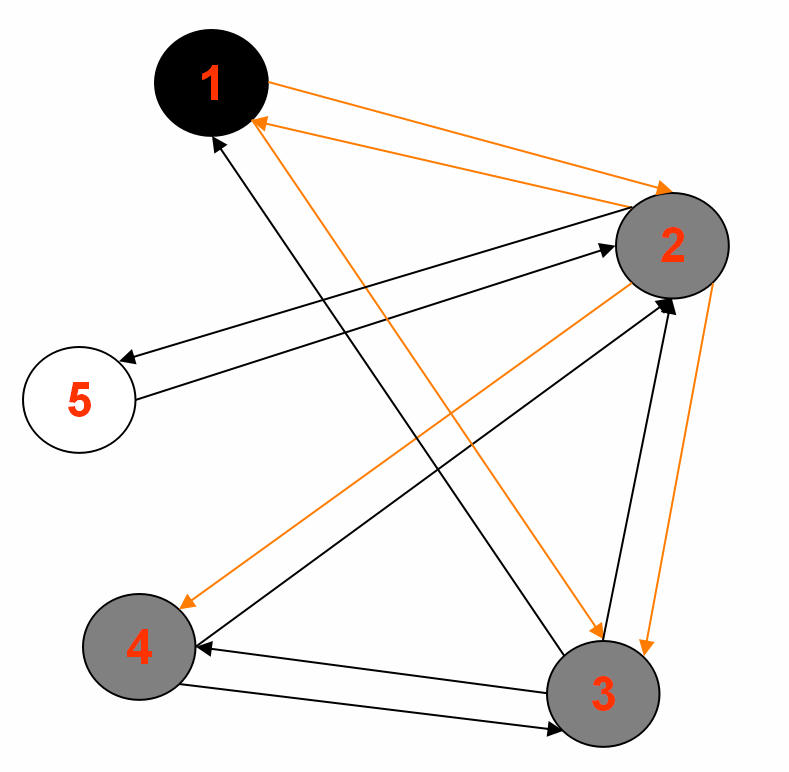
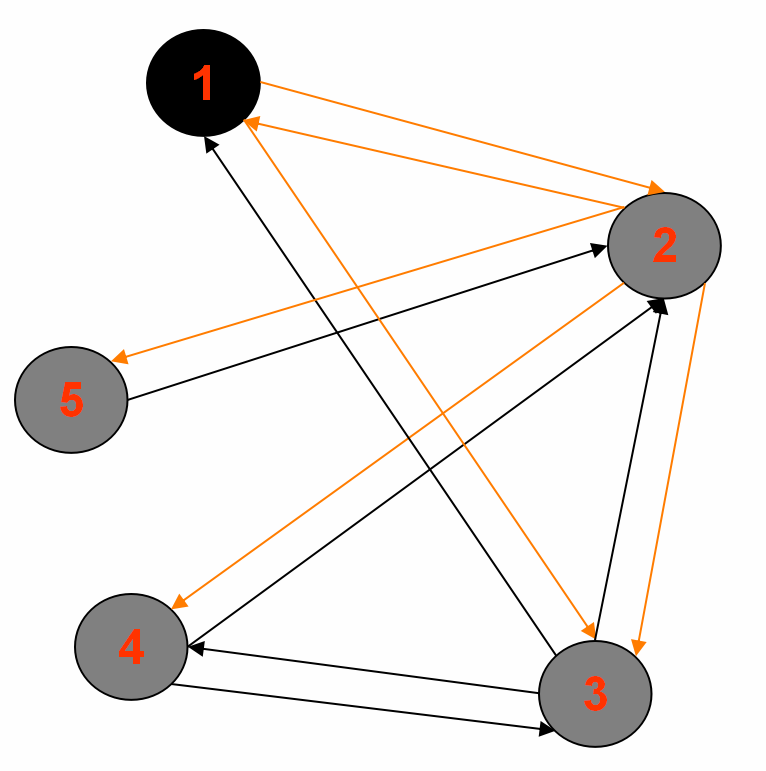
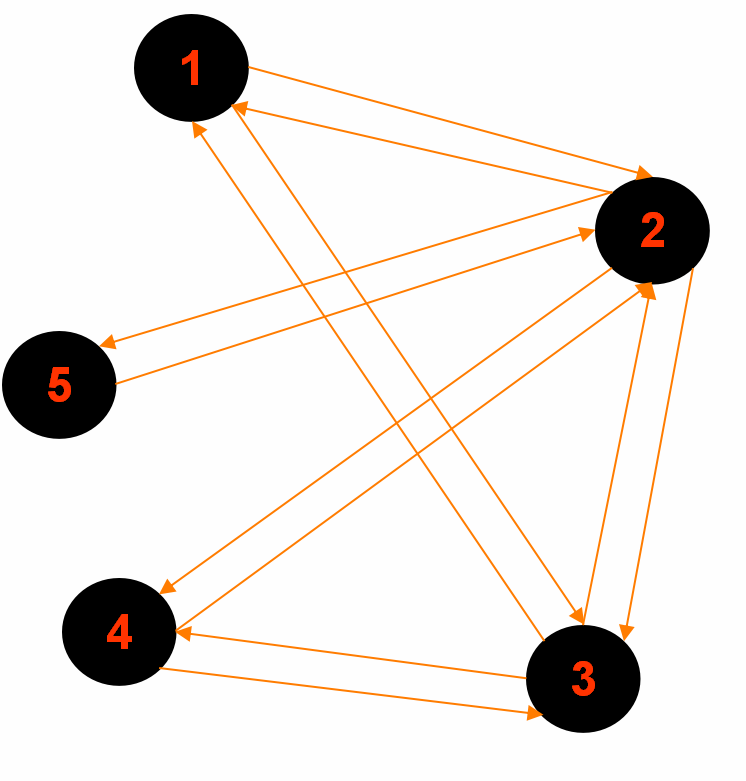
3.最终输出:
Reducer 1: (part-r-00000)
2<tab>1,3,4,5,|1|BLACK|1
5<tab>2,|2|BLACK|2
Reducer 2: (part-r-00001)
3<tab>1,4,2,|1|BLACK|1
Reducer 3: (part-r-00002)
1<tab>2,3,|0|BLACK|source
4<tab>2,3,|2|BLACK|2
三.mapreduce实现图的BFS代码
import java.util.*;
import org.apache.hadoop.io.Text;
public class Node {
// 标识节点是第几次访问
public static enum Color {
WHITE, GRAY, BLACK
};
private String id;
private int distance; // 到出发点的距离
private List<String> edges = new ArrayList<String>(); // 边集
private Color color = Color.WHITE;
private String parent; //父节点
public Node() {
edges = new ArrayList<String>();
distance = Integer.MAX_VALUE;
color = Color.WHITE;
parent = null;
}
public Node(String nodeInfo) {
String[] inputLine = nodeInfo.split(" ");
String key = "", value = "";
try {
key = inputLine[0]; // 节点id
value = inputLine[1]; //邻节点list
} catch (Exception e) {
e.printStackTrace();
System.exit(1);
}
String[] tokens = value.split("\|"); // /tokens[0] = 邻节点list, tokens[1]= 距离, tokens[2]= 颜色, tokens[3]= 父节点
this.id = key;
//设置边节点
for (String s : tokens[0].split(",")) {
if (s.length() > 0) {
edges.add(s);
}
}
// 设置距离
if (tokens[1].equals("Integer.MAX_VALUE")) {
this.distance = Integer.MAX_VALUE;
} else {
this.distance = Integer.parseInt(tokens[1]);
}
// 设置颜色
this.color = Color.valueOf(tokens[2]);
// 设置父节点
this.parent = tokens[3];
}
public Text getNodeInfo() {
StringBuffer s = new StringBuffer();
try {
for (String v : edges) {
s.append(v).append(",");
}
} catch (NullPointerException e) {
e.printStackTrace();
System.exit(1);
}
s.append("|");
if (this.distance < Integer.MAX_VALUE) {
s.append(this.distance).append("|");
} else {
s.append("Integer.MAX_VALUE").append("|");
}
s.append(color.toString()).append("|");
s.append(getParent());
return new Text(s.toString());
}
}
2.SearchMapper
import java.io.IOException;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
public class SearchMapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context, Node inNode)
throws IOException, InterruptedException {
if (inNode.getColor() == Node.Color.GRAY) {
for (String neighbor : inNode.getEdges()) {
Node adjacentNode = new Node();
adjacentNode.setId(neighbor);
adjacentNode.setDistance(inNode.getDistance() + 1);
context.write(new Text(adjacentNode.getId()), adjacentNode.getNodeInfo());
}
inNode.setColor(Node.Color.BLACK);
}
context.write(new Text(inNode.getId()), inNode.getNodeInfo());
}
}
3.SearchReducer
public class SearchReducer extends Reducer<Text, Text, Text, Text> { public Node reduce(Text key, Iterable<Text> values, Context context, Node outNode) throws IOException, InterruptedException { outNode.setId(key.toString()); for (Text value : values) { Node inNode = new Node(key.toString() + " " + value.toString()); if (inNode.getEdges().size() > 0) { outNode.setEdges(inNode.getEdges()); } if (inNode.getDistance() < outNode.getDistance()) { outNode.setDistance(inNode.getDistance()); outNode.setParent(inNode.getParent()); } if (inNode.getColor().ordinal() > outNode.getColor().ordinal()) { outNode.setColor(inNode.getColor()); } } context.write(key, new Text(outNode.getNodeInfo())); return outNode; } }
4.SearchMapperSSSP.java
public static class SearchMapperSSSP extends SearchMapper { public void map(Object key, Text value, Context context) throws IOException, InterruptedException { Node inNode = new Node(value.toString()); super.map(key, value, context, inNode); } }
5.SearchReducerSSSP.java
public static class SearchReducerSSSP extends SearchReducer{ public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { Node outNode = new Node(); outNode = super.reduce(key, values, context, outNode); if (outNode.getColor() == Node.Color.GRAY) context.getCounter(MoreIterations.numberOfIterations).increment(1L); } }
6.BaseJob.java
private Job getJobConf(String[] args) throws Exception { JobInfo jobInfo = new JobInfo() { @Override public Class<? extends Reducer> getCombinerClass() { return null; } @Override public Class<?> getJarByClass() { return SSSPJob.class; } @Override public Class<? extends Mapper> getMapperClass() { return SearchMapper.class; } @Override public Class<?> getOutputKeyClass() { return Text.class; } @Override public Class<?> getOutputValueClass() { return Text.class; } @Override public Class<? extends Reducer> getReducerClass() { return SearchReducer.class; } }; return setupJob("ssspjob", jobInfo); } public int run(String[] args) throws Exception { int iterationCount = 0; Job job; long terminationValue =1; while( terminationValue >0){ job = getJobConf(args); if (iterationCount == 0) input = args[0]; else input = args[1] + iterationCount; output = args[1] + (iterationCount + 1); FileInputFormat.setInputPaths(job, new Path(input)); FileOutputFormat.setOutputPath(job, new Path(output)); job.waitForCompletion(true); Counters jobCntrs = job.getCounters(); terminationValue = jobCntrs.findCounter(MoreIterations.numberOfIterations).getValue(); iterationCount++; } return 0; } public static void main(String[] args) throws Exception { int res = ToolRunner.run(new Configuration(), new SSSPJob(), args); if(args.length != 2){ System.err.println("Usage: <in> <output name> "); } System.exit(res); }