Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下)
- 自动使用cookie的方法,告别手动拷贝cookie
- http模块包含一些关于cookie的模块,通过他们我们可以自动的使用cookie
- CookieJar- 管理存储Cookie,向传出的http请求添加cookie
- 这里Cookie存储在内存中,CookieJar实例回收后cookie将消失
- FileCookieJar(filename, delayload=None, policy=None)
- 使用文件管理cookie
- filename是保存cookie的文件
- MozillaCookieJar(filename, delayload=None, policy=None)
- 创建Mocilla浏览器cookie.txt兼容的FileCookieJar实例
-
- 火狐Firefox浏览器需要单独处理
- LwpCookieJar(filename, delayload=None, policy=None)
- 创建于libww-per标准兼容的Set-Cookie3格式的FileCookieJar
- 它们之间的关系: CookieJar-->FileCookieJar-->MozillaCookieJar & LwpCookieJar
利用CookieJar访问人人网
- 自动使用cookie登录,使用步骤:
- 1.打开登录页面后自动通过用户名密码登录
- 2.自动提取反馈回来的cookie
- 3.利用提取的cookie登录个人信息页面
- 创建cookiejar实例
- 生成cookie的管理器
- 创建http请求管理器
- 创建https请求的管理器
- 创建请求管理器
- 通过输入用户名和密码,获取cookie
- 案例13cookiejar文件:https://xpwi.github.io/py/py爬虫/py13cookiejar.py
# 使用cookiejar完整代码
from urllib import request,parse
from http import cookiejar
# 创建cookiejar的实例
cookie = cookiejar.CookieJar()
# 常见cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求的管理器
http_handler = request.HTTPHandler()
# 生成https管理器
https_handler = request.HTTPSHandler()
# 创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
def login():
# 负责首次登录,输入用户名和密码,用来获取cookie
url = 'http://www.renren.com/PLogin.do'
id = input('请输入用户名:')
pw = input('请输入密码:')
data = {
# 从input标签的name获取参数的key,value由输入获取
"email": id,
"password": pw
}
# 把数据进行编码
data = parse.urlencode(data)
# 创建一个请求对象
req = request.Request(url,data=data.encode('utf-8'))
# 使用opener发起请求
rsp = opener.open(req)
# 以上代码就可以进一步获取cookie了,cookie在哪呢?cookie在opener里
def getHomePage():
# 地址是用在浏览器登录后的个人信息页地址
url = "http://www.renren.com/967487029/profile"
# 如果已经执行login函数,则opener自动已经包含cookie
rsp = opener.open(url)
html = rsp.read().decode()
with open("rsp1.html", "w", encoding="utf-8")as f:
# 将爬取的页面
print(html)
f.write(html)
if __name__ == '__main__':
login()
getHomePage()
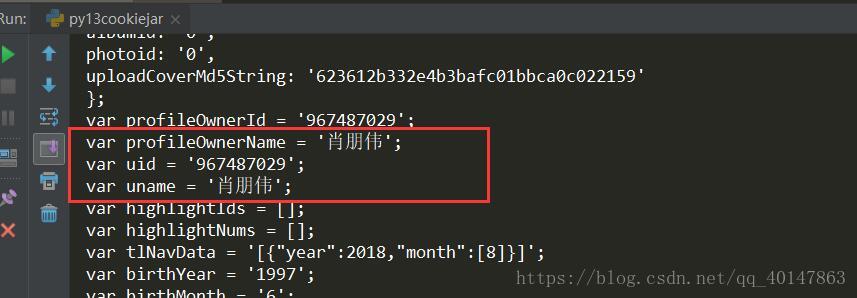
运行结果
看到自己的个人信息就是说明登录成功了
补充:在爬虫代码输入用户名和密码的使用方法
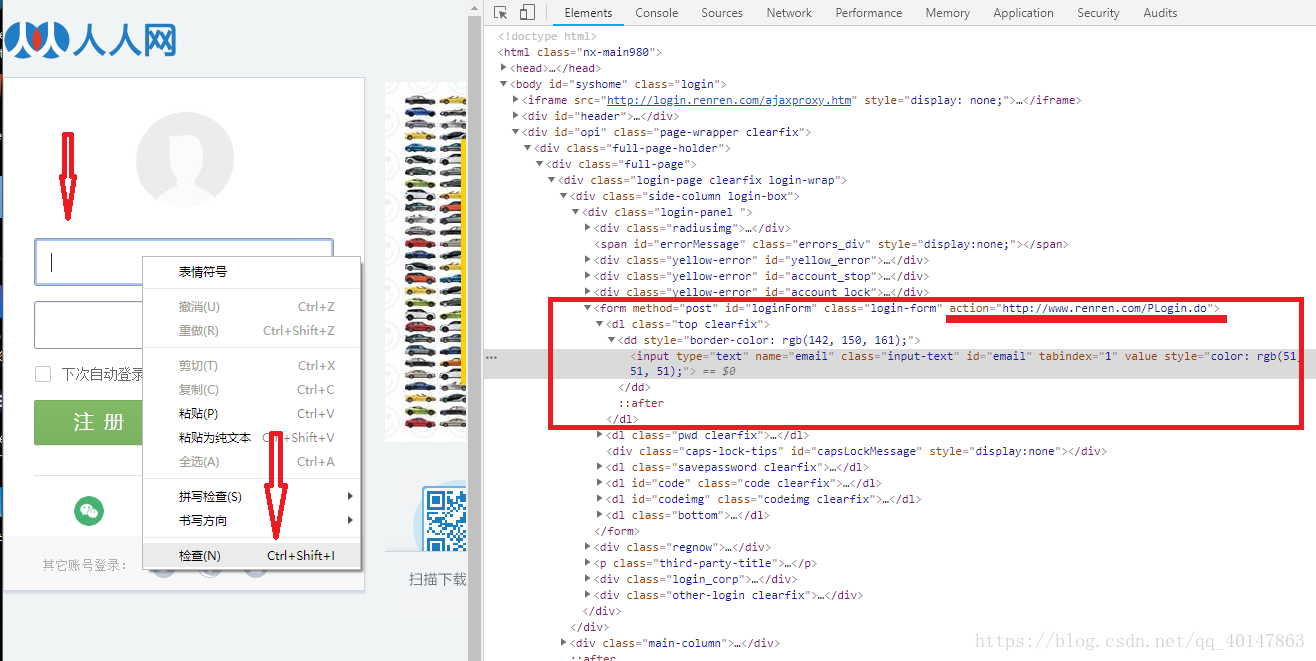
- 1.打开网站首页,登录表单页面
- 2.在输入用户名和密码的地方,【右键检查】,或者查看源代码
- 3.找到登录表单【form标签的action属性】,拷贝地址
- 4.提示:如果不能直接拷贝,【双击】地址,Ctrl+C
- 操作截图:
- 5.找到用户名和密码的【input标签的name属性】,构建参数时使用
- 6.然后在代码中,构建data参数,模拟post请求
# 代码片段
url = 'http://www.renren.com/PLogin.do'
data = {
# 参数使用正确的用户名密码
"email": "18322295195",
"password": "oaix51607991"
}
# 把数据进行编码
data = parse.urlencode(data)
爬虫使用cookie,自动获取cookie解介绍到这里了
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载