1. re.findall():会以第一个参数作为正则规则,将第二个参数待匹配字符串中满足前面正则规则的结果返回到列表中;
import re ret=re.findall('a','sa123dkfj34akjdjfk1a') #只匹配单个字符‘a’ print(ret)
运行结果:

在借用之前的正则规则,匹配小写字母:
import re ret=re.findall('[a-z]+','abc123def456ghjk678kljmn') print(ret)
运行结果:

findall()函数还有一个特性就是当使用分组时,会优先匹配分组内的内容,把匹配的结果返回成一个列表:
import re ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com') #这里使用分组,会优先匹配分组中的内容,并且findall的结果会返回一个列表 print(ret)
运行结果:
所以在这里总结一下 ?在正则中用法(在不同的位置具有不同的功能):
1.用在字符之后,当作量词使用表示前面的字符重复0-1次(相当于可以重复匹配前面的字符0-1次)
2.用在量词之后,表示非贪婪匹配,就是惰性匹配,尽可能少的匹配;
3. .*?x表示尽可能少的匹配任意字符,直到遇到一个x就立马停止;
4. 在分组中使用,比如findall()函数中使用分组,会优先匹配分组内的,如果想要取消优先分组就需要在分组内?: 来取消;
如果想要取消优先匹配分组,则可以使用?:
import re ret=re.findall('www.(?:baidu|oldboy).com','www.baidu.com') #findall()会优先匹配分组内容,如果想取消,可以在分组内使用?:取消优先分组 print(ret)
运行结果:

2. re.search():会查找满足正则规则的第一个结果,返回的是一个对象,可以使用.group()方法获得,但是如果遍历到最后都没有找到满足正则规则的结果,会返回一个None,就不能调用.group()方法:
import re ret=re.search('a','eval,hello,my dear') print(ret) #search()方法返回的是一个对象,一旦找到满足正则规则的结果就立刻返回,可以使用.group()方法获得 print(ret.group()) #只会返回满足正则规则的第一个结果,所以后续会返回一个值
运行结果:

import re ret=re.search('hello','haha,helloxuan,helloxuanxuan') #只会匹配第一个 print(ret) print(ret.group())
运行结果:

但是如果,后面带匹配的字符串都不满足前面的正则规则呢,那就是找不到,此时的ret结果会返回一个None,此时再调用group()方法就会报错:
import re ret=re.search('hello!','haha,helloxuan,helloxuanxuan') #只会匹配第一个 print(ret) print(ret.group())
运行结果:

re.search()函数中第一个参数表示正则规则,如果里面使用分组,则可以单独打印分组内的内容:
比如之前匹配15或者18位的身份证号码:
import re ret=re.search('^[1-9]d{14}(d{2}[0-9x])?$','574546748912543216') print(ret.group()) print(ret.group(0)) print(ret.group(1)) #这个就是分组中的内容(d{2}[0-9x])这三位数
运行结果:

如果再使用一个分组,你猜结果会是怎样的~
import re ret=re.search('^[1-9](d{14})(d{2}[0-9x])?$','475789453762107842') print(ret.group()) print(ret.group(1)) #打印第一个分组的内容 也就是第一个括号,十四位 print(ret.group(2)) #打印第二个分组的内容,也就是第二个括号,后三位
运行结果:

3. re.math():匹配后面的字符串,必须开头是前面的正则规则,返回一个对象,必须使用.group()方法取值,如果找不到,返回None
import re ret=re.match('[he]+','hello,xuanxuan') print(ret) #mathch返回的也是一个对象,必须使用.group()方法取值 print(ret.group())
运行结果:

如果后面带匹配的字符串开头不满足正则规则,mathch()方法返回None,就不能调用group()
import re ret=re.match('[el]','hello,xuanxuan') #表示以e或者l 进行匹配一位 print(ret) #mathch返回的也是一个对象,必须使用.group()方法取值 print(ret.group())
运行结果:

4. re.split(),以前面给定的正则规则进行切分,将切分结果返回成一个列表
import re ret=re.split('a','abcaegahk') print(ret)
运行结果:

这里需注意,前面的正则规则是没有保留的(这一点跟str.split()方法类似)
如果前面的正则规则是类似下面这样:,就变成先按'a'切一遍,再对切分的结果再按照'b'切一遍
import re ret=re.split('[ab]','abcaebgahk') print(ret)
运行结果:

还有另外一种情况,就是分组,切割的时候,是会保留前面正则规则中的条件:
import re ret=re.split('(a)','ajdfjkadlfla') print(ret)
运行结果:

再比如:
import re ret=re.split('(ab)','ajdfjkabdlfla') #这里以‘ab’作为一个整体切割,但是分组会保留'ab' print(ret)
运行结果:

再比如:
import re ret=re.split('([ab])','ajdfjkabdlfla') #先按照a切一遍,,再把切割的结果按照b再切一遍 print(ret)
运行结果:

5.re.sub(): 进行替换,把第一个参数中正则规则中的字符替换为后面新的字符,然后返回这个字符串
import re ret=re.sub('a','A','hi,xuanxuan') #正则规则就是‘a’用来匹配后面的字符串,匹配到的替换成'A' print(ret)
运行结果:

其实这个有点类似于字符串的replace()方法实现某个字符的替换,当然如果只进行上面单个字符的替换,那简直对sub有点大材小用啦,其实还可以这样:
import re ret=re.sub('d','哈','jsdj81290390lkdlfkl8923830') #待匹配的字符串凡是出现数字的都匹配成'哈' print(ret)
运行结果:
这样就不再是单一的一对一替换了,这里显然是多对一替换,,,
re.subn(): 跟上面的re.sub()方法类似,也是实行替换,但是这个方法会返回一个元组,第一个元素就是替换后的字符串,第二个结果就是替换了多少次(也就是正则规则匹配了多少个满足条件的)
import re ret=re.subn('d','哈','hello1,xuan2,xuan3') print(ret)
运行结果:

6.re.complie():就是将正则表达式变为正则表达式对象,代表了匹配的规则
import re obj=re.compile('d{2}') #查找带有连续的两个数字的 ret=obj.findall('3asj1b123sldl940-30-') print(ret)
运行结果:

再比如:
import re obj=re.compile('[a-z]+') #把正则表达式变为正则表达式对象,并且制定的正则规则为:匹配小写字母,一次或任意多次,当然是贪婪匹配,匹配尽可能多的小写字母 ret=obj.search('123abcdefghijklm456b789c') #这个search是仅找到一个就停止了,接下来不在匹配 print(ret.group())
运行结果:

7.re.finditer():返回一个迭代器,也是匹配前面的正则规则,只不过把匹配的结果存在迭代器,需要使用for循环或者next()函数(.__next__())取值,但是别忘了最后.group()取值!!
import re generator=re.finditer('[a-z]','123alsldfjk34') # 正则规则是匹配小写字母 只匹配一个位置(也就是一次),所以多个字母其实是换行分开打印的,不在一行显示~ print(generator) print(generator.__next__().group()) print('********') print(next(generator).group()) print("*********") for i in generator: print(i.group())
运行结果: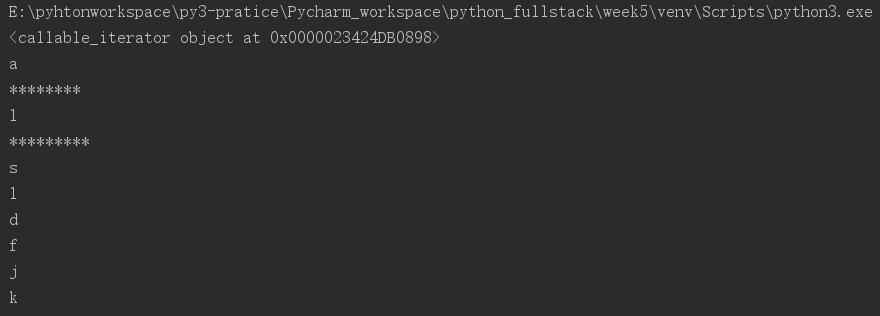
如果想在一行显示,其实也就是匹配多个小写字母:
import re generator=re.finditer('[a-z]+','12sdlfkdflkla123434jkdlfkldfl') #可以匹配小写字母一次到任意多次,如果中间被打断了比如这里是数字,那么就重新开始匹配,对应的是换行打印: for i in generator: print(i.group())
运行结果:
