| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/computer-science-class4-2018/homework/11880 |
| 这个作业的目标 | 编程作业 |
| 其他参考文献 | 博客园、CSDN、简书 |
1、Gitee项目地址
https://gitee.com/xu-do/project-java
2、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 500 | 935 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 90 | 180 |
| • Design Spec | • 生成设计文档 | 30 | 35 |
| • Design Review | • 设计复审 | 20 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| • Design | • 具体设计 | 40 | 100 |
| • Coding | • 具体编码 | 180 | 360 |
| • Code Review | • 代码复审 | 20 | 10 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30 | 60 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 510 | 935 |
3、解题思路描述
- 设计一个Lib类,在其中设计所需的方法,WordCount类有一个main()函数,调用Lib的方法实现功能。
- 代码运行流程和思路:
- 打开输入文件并读取内容:看到文件读写首先就在想要用哪种读写方式,后来选择使用BufferedReader,read()方法读取文件内容,并且不读取' '
- 统计字符数:因为不考虑中文字符,且任意ASCII码均算做一个字符,所以觉得只要读取读取内容的长度就可以了。
- 统计单词数:刚开始想到split()方法来分割单词,但还在犹豫分割的方式,后来在网上查询到了正则表达式,于是就利用正则表达式将内容分成单词数组并检验单词的合法性,统计数量。
- 统计非空行数:同样利用正则表达式的方法。
- 统计频率最高的单词:在统计单词数时将单词信息存放到Map<String, Integer>中,然后对Map内容进行排序。
- 将内容写入输出文件:使用BufferedWrite,write()方法,分别将所需内容写入文件。
4、代码规范制定链接
https://gitee.com/xu-do/project-java/blob/master/20188518/codestyle.md
5、设计与实现过程
类设计
- Lib类和WordCount类:
其中Lib封装了具体功能的实现方法,WordCount只有一个main函数,调用Lib类封装的方法。
Lib类主要属性和方法有:
private String inputFile;
private String outputFile;
private String content;
private int charsNum;
private int wordsNum;
private int linesNum;
private Map<String, Integer> wordsMap;
/**
* 读取文件内容
*/
public void readFile() throws IOException
/**
* 写入文件
*/
public void writeFile() throws IOException
/**
* 统计字符数
*/
public void countCharsNum()
/**
* 统计单词数,以及每个单词出现的次数
*/
public void countWordsNum()
/**
* 统计非空行数
*/
public void countLinesNum()
/**
* 根据单词频率进行排序
*/
public List<Map.Entry<String, Integer>> sortWordsMap()
函数关系图:
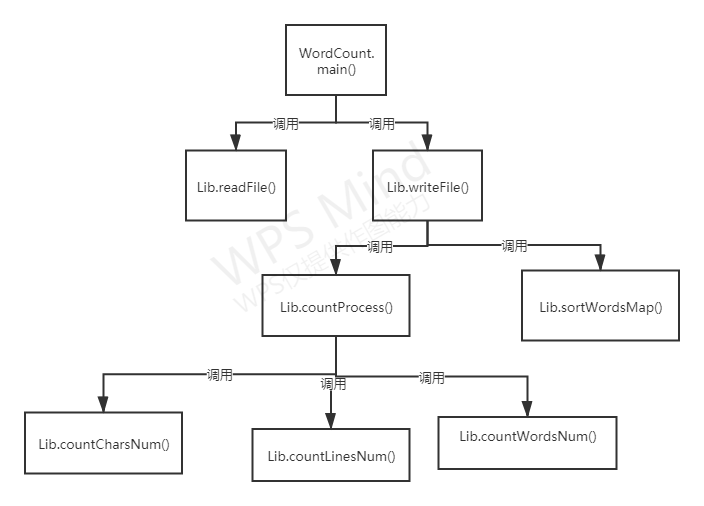
功能实现
-
统计字符数
由于不考虑中文字符,且任意ASCII码均算做一个字符,在文件读入时就除去了' ',所以直接获取字符串长度即可
charsNum = content.length(); -
统计单词数,在统计单词数的同时,可以一起记录单词以及出现的次数
使用正则表达式和split()方法,将读取的字符串内容以空格,非字母数字符号分割,且使用toLowerCase()全部转化为小写
String[] words = content.split("[^a-zA-Z0-9]+");使用正则表达式,来验证分割后的字符串是否符合单词的定义(至少以4个英文字母开头,跟上字母数字符号)
if (words[i].matches("[a-zA-Z]{4,}[a-zA-Z0-9]*")) { wordsNum++;使用Map<String, Interger>存放单词与次数
word = words[i].toLowerCase(); if (wordsMap.containsKey(word)){ num = wordsMap.get(word); num++; wordsMap.put(word, num); } else { wordsMap.put(word, 1); } -
统计有效行数
任何包含非空白字符的行,都需要统计,所以使用正则表达式来匹配
linesNum = 0; Pattern linePattern = Pattern.compile("(^| )\s*\S+"); Matcher matcher = linePattern.matcher(content); while (matcher.find()){ linesNum++; } -
因为结果要输出频率最高的10个单词,所以对单词Map进行排序
频率相同的单词,优先输出字典序靠前的单词。
List<Map.Entry<String, Integer>> wordsList = new ArrayList<Map.Entry<String, Integer>>(wordsMap.entrySet()); Collections.sort(wordsList, new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> word1, Map.Entry<String, Integer> word2) { if(word1.getValue().equals(word2.getValue())) { return word1.getKey().compareTo(word2.getKey()); } else { return word2.getValue() - word1.getValue(); } } }); -
读文件选择使用BufferedReader、read()方法,使用StringBuilder来合并每次读到的字符,提高性能,并且不读取' '
while ((num = reader.read()) != -1) { // UTF-8中' '对应编码int值为13 if (num != 13) { ch = (char) num; builder.append(ch); } }写文件选择了BUfferedWrite、write()方法
6、异常处理说明
- Lib中的异常都是I/O异常。
- WordCount类中,对文件传入参数个数进行了异常处理
if (args.length < 2){
System.out.println("Insufficient parameters");
}
else {
......
}
当传入参数不足时:

当传入的要读的文件不存在时:

当要写入的文件不存在时,会自动创建文件。
当程序运行成功时:

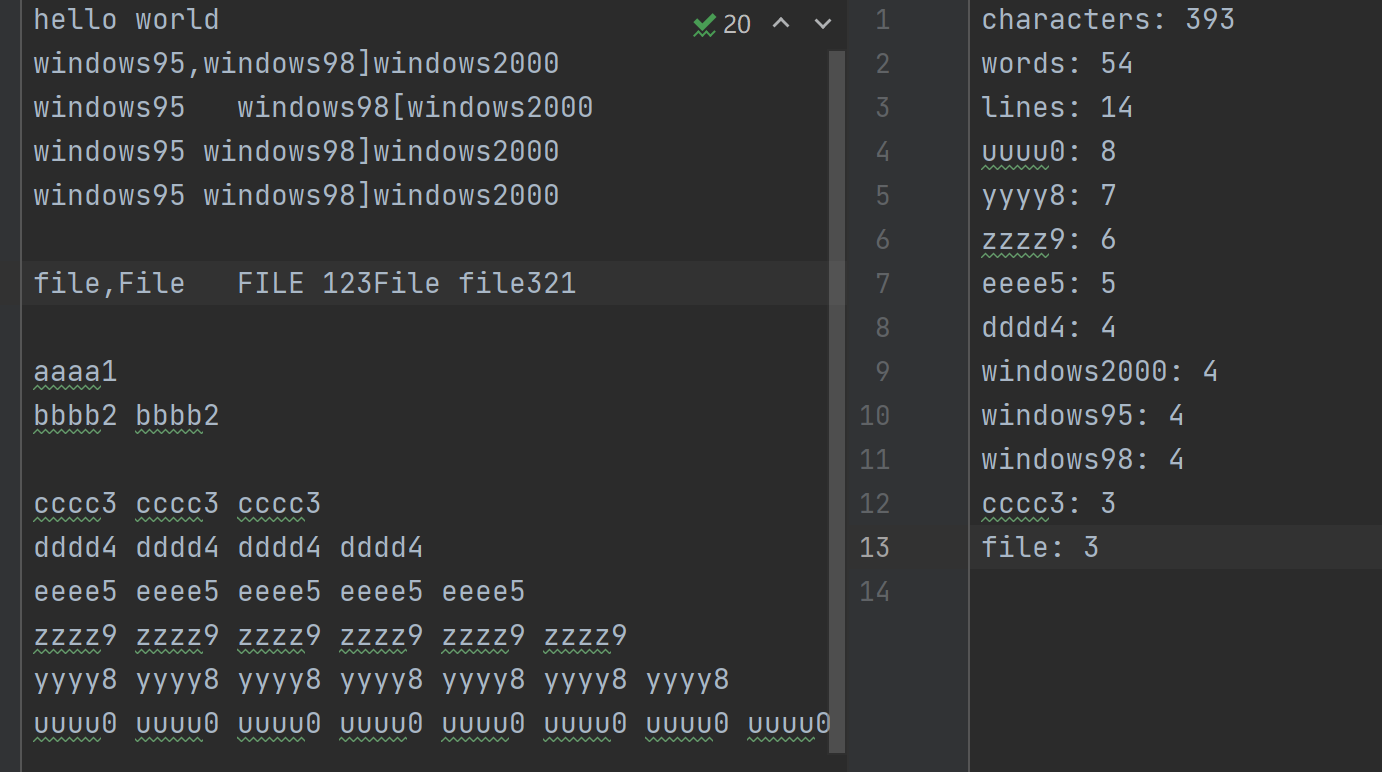
7、心路历程与收获
- 此次作业第一次接触使用了gitee,学习了如何使用,也感受到了用git工具管理代码的优越性。
- 初步学习了正则表达式,它的规则挺多的,而且也需要比较清晰的逻辑思维才可以使用好,还需要多加练习。
- 重温了文件读写的方法,以前虽然有学过,但是使用的比较少,这次使用也遇到了一些问题。比如BufferedWrite的使用中,没有及时flush()或是close(),有时候导致文件写入出了问题。
- PSP的使用。以前从来没有使用过PSP。第一次使用还是觉得有点不习惯,尤其是在预估耗时的方面。