爬虫的应用:
# 1.通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 1)搜索引擎如何抓取互联网上的网站数据? a)门户网站主动向搜索引擎公司提供其网站的url b)搜索引擎公司与DNS服务商合作,获取网站的url c)门户网站主动挂靠在一些知名网站的友情链接中 # 2.聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。 例如: 获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
爬虫的基本流程:
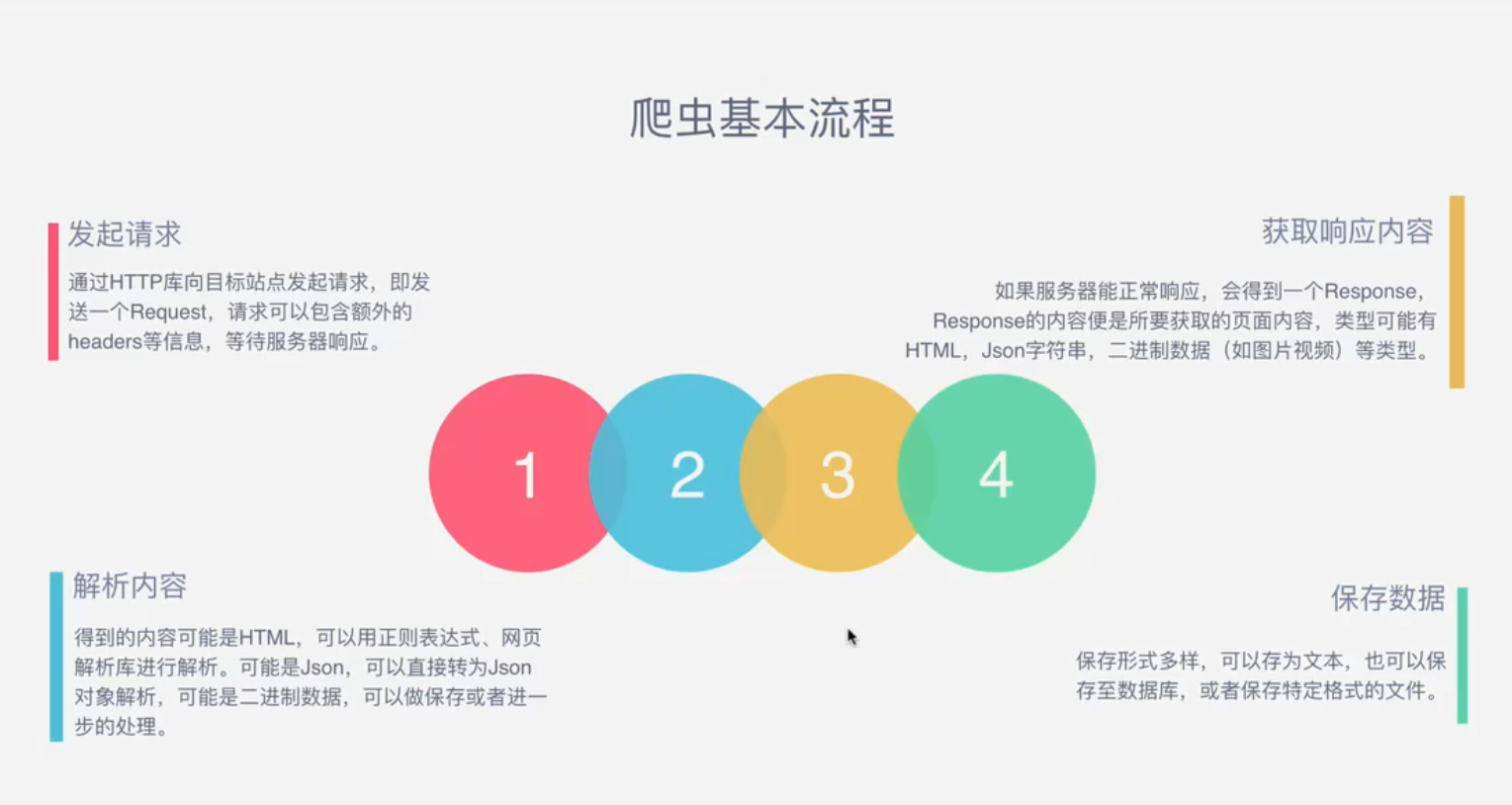
request:
#1、请求方式: 常用的请求方式: GET,POST 其他请求方式: HEAD,PUT,DELETE,OPTHONS ps:用浏览器演示get与post的区别,(用登录演示post) post与get请求最终都会拼接成这种形式: k1=xxx&k2=yyy&k3=zzz post请求的参数放在请求体内: 可用浏览器查看,存放于form data内 get请求的参数直接放在url后 #2、请求url url全称统一资源定位符,如一个网页文档,一张图片 一个视频等都可以用url唯一来确定 url编码: https://www.baidu.com/s?wd=图片 图片会被编码(看示例代码) 网页的加载过程是: 加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求。 #3、请求头 User-agent: 请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户。 Cookies: cookie用来保存登录信息。 Referer: 浏览器上次访问的网页url 一般做爬虫都会加上请求头 #4、请求体 如果是get方式,请求体没有内容 如果是post方式,请求体是format data ps: 1、登录窗口,文件上传等,信息都会被附加到请求体内 2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
response:
爬取校花网:


# pip3 install requests import requests import re # 爬虫三部曲 # 一 发送请求 def get_page(url): print() index_res = requests.get(url) return index_res.text # 二 解析数据 # 解析主页 def parse_index(index_page): detail_urls = re.findall('<div class="items">.*?href="(.*?)"', index_page, re.S) # print(detail_urls) for detail_url in detail_urls: if not detail_url.startswith('http'): detail_url = 'http://www.xiaohuar.com' + detail_url yield detail_url # 解析详情页 def parse_detail(detail_page): video_urls = re.findall('id="media".*?src="(.*?)"', detail_page, re.S) if video_urls: video_urls = video_urls[0] if video_urls.endswith('.mp4'): yield video_urls # print(video_urls) # 三 保存数据 import uuid def save_video(video_url): try: res = requests.get(video_url) with open(r'D: ankday01movies\%s.mp4' % uuid.uuid4(), 'wb') as f: f.write(res.content) f.flush() except Exception: pass if __name__ == '__main__': base_url = 'http://www.xiaohuar.com/list-3-{}.html' for line in range(5): index_url = base_url.format(line) index_page = get_page(index_url) detail_urls = parse_index(index_page) for detail_url in detail_urls: detail_page = get_page(detail_url) video_urls = parse_detail(detail_page) for video_url in video_urls: save_video(video_url)
import requests import re from concurrent.futures import ThreadPoolExecutor pool = ThreadPoolExecutor(50) # 爬虫三部曲 # 一 发送请求 def get_page(url): print('%s GET start ...' % url) index_res = requests.get(url) return index_res.text # 二 解析数据 # 解析主页 def parse_index(index_page): # 拿到主页的返回结果 res = index_page.result() detail_urls = re.findall('<div class="items">.*?href="(.*?)"', res, re.S) # print(detail_urls) for detail_url in detail_urls: if not detail_url.startswith('http'): detail_url = 'http://www.xiaohuar.com' + detail_url pool.submit(get_page, detail_url).add_done_callback(parse_detail) # yield detail_url # 解析详情页 def parse_detail(detail_page): res = detail_page.result() video_urls = re.findall('id="media".*?src="(.*?)"', res, re.S) if video_urls: video_urls = video_urls[0] if video_urls.endswith('.mp4'): pool.submit(save_video, video_urls) # print(video_urls) # 三 保存数据 import uuid def save_video(video_url): try: res = requests.get(video_url) with open(r'D: ankday01movies\%s.mp4' % uuid.uuid4(), 'wb') as f: f.write(res.content) f.flush() print('%s done ...' % video_url) except Exception: pass if __name__ == '__main__': base_url = 'http://www.xiaohuar.com/list-3-{}.html' for line in range(5): index_url = base_url.format(line) pool.submit(get_page, index_url).add_done_callback(parse_index)
查询出来的页面要返回content
yeild使用的缩进