在MapReduce过程中,每一个Job都会被分成若干个task,然后再进行处理。那么Hadoop是怎么将Job分成若干个task,并对其进行跟踪处理的呢?今天我们来看一个*Context类——TaskInputOutputContext。
先来看看TaskInputOutputContext的类图:
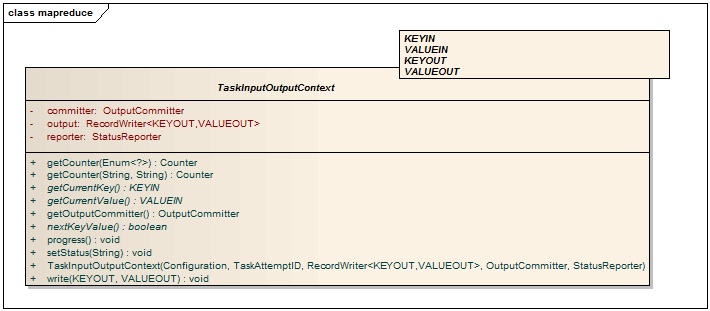
Figure1:TaskInputOutputContext类图
从类图中可以看到,TaskInputOutputContext有3个成员变量和10个成员函数。成员变量中有一个OutputCommitter对象,一个RecordWriter对象和一个StatusReporter对象。OutputCommitter到底是做什么的呢?来看看它的类图:

Figure2:OutputCommitter类图
其实OutputCommitter类中方法以将它的功能描述得很清楚:
setupJob:Hadoop初始化时设置job的输出;
commitJob:当job完成时,清除job的输出,这个方法在反馈回来的job状态为SUCCEEDED时调用;
cleanupJob:job结束后清除job的输出;
abortJob:当job的返回状态是FAILED或KILLED时,执行该函数,用于终止作业的输出;
setupTask:设置task的输出;
needsTaskCommit:检测task是否需要提交;
commitTask:将task的输出移到作业的输出目录;
abortTask:取消task的输出;
outputCommitter类的作用就是提供Job和Task的临时文件管理功能,setupJob在系统初始化时在输出路径下创建一个临时目录,MapReduce过程中产生的临时文件会被放在这里,等Job完成后,系统会调用cleanupJob删除这个目录。
再来看看下一个类——RecordWriter。RecordWriter的功能很简单,它提供一个write方法来输出<key, value>对,一个close方法来关闭输出。它有一个对应的类——RecordReader,我们在《Hadoop -- MapReduce过程》中分析过。RecordReader将输入的数据切片并转化成<key, value>对,该<key, value>对作为Mapper的输入。
StatusReporter类我们《Hadoop -- MapReduce过程(2)》中已分析过,这里就不多讲了。
我们回到TaskInputOutputContext类上来,从类图中的方法我们可以看出,TaskInputOutputContext主要是用于获取key,value的值和输出<key, value>对。什么操作需要用到key/value呢?当然是Mapper和Reducer。因此TaskInputOutputContext是作为一个父类,被MapContext和ReduceContext继承。我们再来看看它们之间的关系:

MapContext读取输入数据并将其分片,输出<key, value>对,ReduceContext读取map输出,迭代计数,最后输出<key, value>对。