原文:http://blog.csdn.net/Solstice/article/details/6406944
版权声明:本文为博主原创文章,未经博主允许不得转载。
陈硕 (giantchen_AT_gmail)
Blog.csdn.net/Solstice t.sina.com.cn/giantchen
陈硕关于分布式系统的系列文章:http://blog.csdn.net/Solstice/category/802325.aspx
本作品采用“Creative Commons 署名-非商业性使用-禁止演绎 3.0 Unported 许可协议(cc by-nc-nd)”进行许可。
http://creativecommons.org/licenses/by-nc-nd/3.0/
约定:本文只考虑 Linux 系统,文中涉及的“服务程序”是以 C++ 或 Java 编写,编译成二进制可执行文件(binary 或 jar),程序启动的时候一般会读取配置文件(或者以其他方式获得配置信息),同一个程序每个服务进程的配置文件可能略有不同。“服务器”这个词有多重含义,为避免混淆,本文以 host 指代服务器硬件,以“服务端程序/进程”指代服务器软件(或者具体说 Web Server 和 Sudoku Solver,这两个都是服务软件)。
在进入正题之前,先看一个虚构但典型的例子:Sudoku Solver。(Sudoku Solver 是个均质的无状态服务,分布式系统中进程的状态迁移不是本文的主题。)
假设你们公司的分布式系统中有一个专门求解数独(Sudoku)的服务程序,这个程序是你们团队开发并维护的。通常 Web Server 会使用这个 Sudoku Solver 提供的服务,用户通过 web 页面提交一个 Sudoku 谜题,web server 转而向 Sudoku Solver 寻求答案。每个 Web Server 会同时跟多个 Sudoku Solver 联系,以实现负载均衡。系统的消息结构大致如下,每个圆角矩形是一个进程,运行在各自的 host 上:
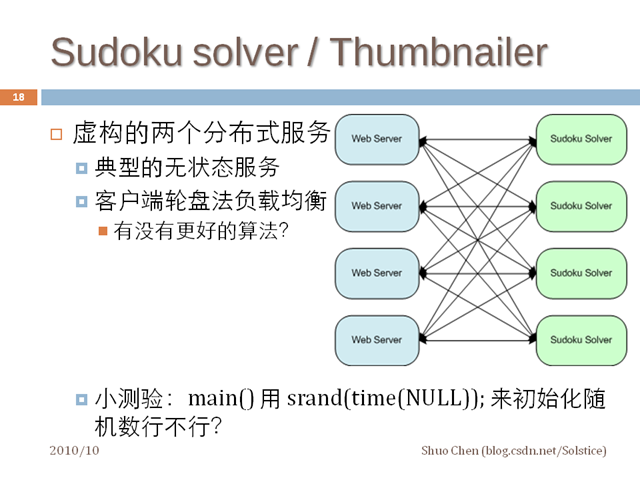
上图中的 Web Server 请不要简单理解为 httpd + cgi,它其实泛指一切客户端,本身可能是个 stateful 的服务程序。
当然,系统不是一开始就是这样,它经历了多步演化。
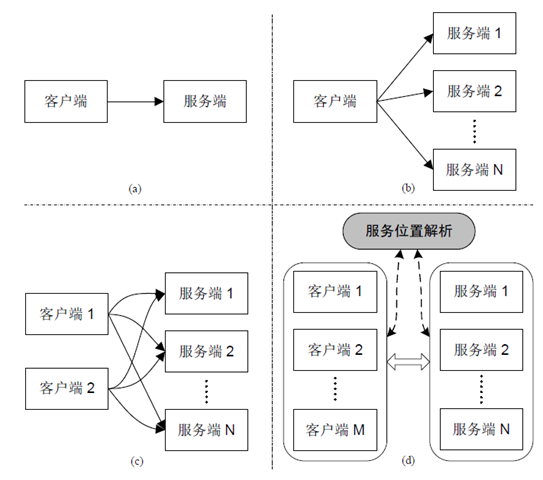
一开始 (a),只有一个 Sudoku Solver,也只有一台 Web Server,是个简单的一对一 (1:1) 的使用关系;
随后 (b),随着业务量增加,一台 host 不堪重负,于是又部署了几台 Sudoku Solver,变成了一对多 (1:n) 的使用关系;
再后来 (c),一台 Web Server 撑不住了,于是部署了几台 Web Server,形成了我们一开始看到的多对多 (m:n) 的使用关系;
(d) 中的情况留到文末再讲。
在分布式系统中部署并运行 Sudoku Solver,需要考虑以下几个问题:
- Sudoku Solver 如何部署到多台 host 上运行?是把可执行文件拷过去吗?程序用到的库怎么办?配置文件怎么办?
- 如何启动服务程序 Sudoku Solver ?如果每个 Solver 的配置文件稍有不同(比如每个 Solver 有自己的 service name),那么配置文件是自动生成吗?
- Sudoku Solver 的 listening port 如何配置?如何保证它不与其他服务程序重复?
- 如果程序 crash,谁来重启?能否自动重启?开发/运维人员能否及时收到 alert?
- 如果想主动重启 Sudoku Solver,要不要登录到那台 host 上去 kill ?还是能够远程控制?
- 如果要升级 Sudoku Solver 程序,如何重新部署?如何(尽量)做到不中断服务?
- Web Server 如何知道那些 Sudoku Solver 的地址?是不是静态写到 Web Server 的配置文件里?
- 如果 Sudoku Solver 所在的 host 发生硬件故障,管理人员是否能立刻得知这一状况?Web Server 能否自动 fail over 到其他 alive 的 Solver 上?
- 部署新的 Sudoku Solver 之后,Web Server 能否自动开始使用新的 Solver 而无需重启?(重启 Web Server 似乎不是大问题,这里我们进一步考虑 client 是个有状态的服务,应该尽量避免重启。)
- 程序可否安全地退役?比方说公司不再做求解 Sudoku 的业务,那么关闭全部 Sudoku Solver 会不会对其他业务造成影响?
这些问题可以大致归结为几个方面:部署(含升级)可执行文件与配置文件、监控进程状态、管理服务进程,合起来可称为运维 operation。
根据公司的规模和技术水平不同,分布式系统的运维分为几重境界,以下是我对各重境界的简要描述。
境界1:全手工操作
这个大概是高校实验室的水平,分布式系统的规模不大,可能十来台机器上下。分布式系统的实现者为在校学生。
系统完全是手工搭起来,host 的 IP 地址静态配置。
部署:编译之后手工把可执行文件拷贝到各台机器上,或者放到公用的 NFS 目录下。配置文件也手工修改并拷贝到各台机器上(或者放到每个 Sudoku Solver 自己单独的 NFS 目录下)。
管理:手工启动进程,手工在命令行指定配置文件的路径。重启进程的时候需要登陆到 host 上并 kill 进程。
升级:如果需要升级 Sudoku Solver,则需要手工登陆多台 hosts,可以拷贝新的可执行文件覆盖原来的,并重启。
配置:Web Server 的配置文件里写上 Sudoku Solver 的 ip:port。如果部署了新的 Sudoku Solver,多半要重启 Web Server 才能发挥作用。
监控:无。系统不是真实的商业应用,仅仅用作学习研究,发现哪儿不对劲了就登陆到那台 host 上去看看,手工解决问题。
这个级别可算是“过家家”,系统时零时不灵,可以跑跑测试,发发 paper。
境界2:使用零散的自动化脚本和第三方组件
这大概是刚起步的公司的水平,系统已经投入商业应用。公司的开发重心放在实现核心业务,添加新功能,暂时还顾不上高效的运维,或许系统的运维任务由开发人员或网管人员兼任。公司已经有了基本的开发流程,代码采用中心化的版本管理工具(比如 SVN),有比较正式的 QA sign-off 流程。
公司内网有 DNS,可以把 hostname 解析为 IP 地址,host 的 IP 地址由 DHCP 配置。公司内部的 host 的软硬件配置比较统一,比如硬件都是 x86-64 平台,操作系统统一使用 Ubuntu 10.04 LTS,每天机器上安装的 package 和第三方 library 也是完全一样的(版本号也相同),这样任何一个程序在任何一台 host 上都能启动,不需要单独的配置。
假设各台 host 已经配置好了 ssh authentication key 或者 GSSAPI,不需要手工输入密码。如果要在 host1, host2, host3, host4 上运行 md5sum 命令,看一下各台机器上的 SudokuSolver 可执行文件的内容是否相同,可以在本机执行:
for h in host1 host2 host3 host4; do ssh $h md5sum /path/to/SudokuSolver/version/bin/sudoku-solver ; done
公司的技术人员有能力配置使用 cron、at、logrotate、rrdtool 等标准的 linux 工具来将部分运维任务自动化。
部署:可执行文件必须经过 QA 签署放行才能部署到生产环境(如有必要,QA 要签署可执行文件的 md5)。为了可靠性,可能不会把可执行文件放到 NFS 上(如果 NFS 故障,整个系统就瘫痪了)。有可能采用 rsync 把可执行文件拷贝到本机目录(考虑到可执行文件比较大,估计不适合直接放到版本管理库里),并且用 md5sum 检查拷贝之后的文件是否与源文件相同。部署可执行文件这一步骤应该可以用脚本自动执行(比方说 ssh $host rsync /path/to/source/on/nfs /path/to/local/copy/)。为了让 C++ 可执行文件拷到 host 上就能用,那么通常采用静态链接,以避免 .so 版本不同造成故障。
Sudoku Solver 的配置文件会放到版本管理工具里,每个 Solver instance 可能有自己的 branch,每次修改都必须入库。程序启动的时候用的配置文件必须从 SVN 里 check-out,不能手工修改(减少人为错误)。
管理:第一次启动进程的时候,会从 SVN check-out 配置文件;以后重启进程的时候可以从本地 working copy 读取配置文件(以避免 SVN 服务器故障对系统造成影响),只在改过配置文件之后才要求 svn update。服务进程使用 daemon 方式管理 (/sbin/init 或 upright 工具),crash 之后会立刻自动重启(利用 respawn 功能)。服务进程一般会随 host 启动而启动(放到 /etc/init.d 里),如果要重启 hostA 上的服务进程,可以通过 ssh 远程操作(比如在本机运行 ssh hostA /etc/init.d/sudoku-solver restart )。进程管理是分散的,每台 host 运行哪些 service 完全由本机是的 /etc/init.d 目录决定。把一个 service 从一台 host 迁移到另一台 host,需要登录到这两台 host 上去做一些手工配置。
升级:可执行文件也有一套版本管理(不一定通过 SVN),发布新版本的时候严禁覆盖已有的可执行文件。比方说,现在运行的是
/path/to/SudokuSolver/1.0.0/bin/sudoku-solver
那么新版本的 Sudoku Solver 会发布到
/path/to/SudokuSolver/1.1.0/bin/sudoku-solver
这么做的原因是,对于 C++ 服务程序,如果在程序运行的时候覆盖了原有的可执行文件,那么可能会在一段时间之后出现 bus error,程序因 SIGBUS 而 crash。另外,如果程序发生 core dump,那么验尸 (post mortem) 的时候必须用“产生 core dump 的可执行文件”配合 core 文件。如果覆盖了原来的可执行文件,post mortem 无法进行。
配置:Web Server 的配置文件里写上 Sudoku Solver 的 host:port (比 境界1 有所提高,这里依赖 DNS,通常 DNS 有一主一备,可靠性足够高)。不过 Web Server 的配置文件和 Sudoku Solver 的配置文件是独立的,如果新增了 Sudoku Solver 或者迁移了 host,除了修改 Sudoku Solver 的配置文件,还有修改所有用到它的 Web Server 的配置文件。这在系统规模比较小的时候尚且可行,系统规模一大,这种服务之间的依赖关系会变得隐晦。如果关闭了某个服务程序,可能一不小心造成其他组的某个服务失灵。如孟岩在《通过一个真实故事理解SOA监管》举的那个例子一样。
监控:公司会使用一些开源的监控工具(以下以 Monit 为例)来监控每台 host 的资源使用情况(内存、CPU、磁盘空间、网络带宽等等)。必要的话可以写一些插件,使之能监控我们自己写的服务程序 (Sudoku Solver)。但是这些监控工具通常只是观察者,它们与进程管理工具是独立的,只能看,不能动。这些监控工具有自己的配置文件,这些配置需要与 Sudoku Solver 的配置同步修改。Monit 可以管理进程,但是它判断服务进程是否能正常工作是通过定时轮询,不一定能立刻(几秒钟)发现问题。
在这个境界,分布式系统已经基本可用了,但也有一些隐患。
配置零散
每个服务程序有自己独立的配置,但是整个系统没有全局的部署配置文件(比方说哪个服务程序应该运行在哪些 hosts 上)。
服务程序的配置文件和用到此服务的客户端程序的配置是独立的,如果把 Sudoku Solver 迁移到另一台 host,那么不仅要修改 Sudoku Solver 的配置,还要修改用到 Sudoku Solver 的 Web Server 的配置,以及监控 Sudoku Solver 的 Monit 的配置。如果忘记修改其中一处,就会造成系统故障。
分布式系统中服务程序的依赖关系是个令人头疼的问题,“依赖”还好办(程序的作者知道我这个服务程序会依赖哪些其他服务),“被依赖”则比较棘手(如何才能知道停掉我这个程序会不会让公司其他系统崩溃?)。这也从一个侧面证明使用 TCP 协议作为唯一的 IPC 手段的必要性,如果采用 TCP 通讯,为了查出有哪些程序用到了我的 Sudoku Solver (假设 listening port 是 9981),那么我只要运行 netstat -tpn |grep 9981 就能找到现在的客户;或者让 Sudoku Solver 自己打印 accept(2) log,连续检查一周或这一个月就能知道有哪些程序用到了 Sudoku Solver。
进程管理分散
如果 hostA 发生硬件故障,如何能快速地用一台备用服务器硬件顶替它?能否先把它上面原来运行的 Sudoku Solver 迁移到空闲的 hostB 上,然后通知 Web Server 用 hostB 上的 Sudoku Solver?“通知 Web Server”这一步要不要重启 Web Server?
境界3:自制机群管理系统,集中化配置
这可能是比较成熟的大公司的水平。
境界 2 中的分散式进程管理已经不能满足业务灵活性方面的需求,公司开始整合现有的运维工具,开发一套自己的机群管理软件。我还没有找到一个开源的符合我的要求的机群管理软件,以下虚构一套名为 Zurg (名字取自科幻电影《第五元素》,拼写稍有不同;Zurg 也是《玩具总动员》中的一个反派角色。)的分布式系统管理软件。
Zurg 的架构很简单,典型的 master slave 结构,见陈硕在《多线程服务器的适用场合》中对“管理 Linux 服务器机群”的描述。

在《分布式系统的工程化开发方法》中谈到了 Zurg 的功能需求:

到了这一境界,日常的管理运维工作已经不再需要反复执行 ssh,常见任务都可以通过 Zurg 来完成。
部署:只需要向 master 发一条指令,master 会命令 slaves 从指定的地点 rsync 新的可执行文件到本地目录。
进程管理与监控:Zurg 的主要功能就是进程管理和监控,比起一般的开源工具,Zurg 更具备一些优势。由于 Sudoku Solver 是由 Zurg Slave fork() 而得,那么当 Sudoku Solver crash 的时候,Zueg Slave 会立刻收到 SIGCHLD,从而能立刻向管理员报告状态并重启。这比 munit 的轮询要迅速得多。(还可以在 fork() 之前做一些手脚,让 Zueg Slave 能更方便地获得 Sudoku Solver 的存活状态。)
为了安全起见,Zurg Slave 在启动可执行文件的时候可以验证其 md5,这样避免错误版本的服务程序运行在生产环境。
Zurg Master 可以提供一个 Web 页面以供查看本机群内各个服务程序是否正常运行。并且提供一个接口(可以是 HTTP)让我们能编写脚本来控制 Zurg master。
升级:如果要主动重启 Sudoku Solver,可以向 Zurg master 发出指令,不需要用 ssh & kill。Zurg 会保存每台 host 上服务进程的启动记录,以便事后分析。如果用境界 2 中的手动 /etc/init.d 管理方式,需要到每台机器上收集 log 才知道 Sudoku Solver 什么时候重启过。
另外也可以单独开发 GUI 程序,运行在运维人员的桌面上,重启多台 host 上的 Sudoku Solver 只需要点几下鼠标。
配置:零散的配置文件被集中的 Zurg 配置文件取代。
Zurg 配置文件会制定哪些 service 会在哪些 host 上运行,Zurg Master 读取配置文件,然后命令各个 Zurg Slave 启动相应的服务程序。比方说配置文件指定 Sudoku Solver 运行在 host1、host2、host3 上,那么 Zurg 会通知在 host1、host2、host3 上的 Zurg Slave 启动 Sudoku Solver。(当然,每台 host 上的 Zurg Slave 需要由 /etc/init.d 启动,其他的服务程序都由它负责启动。)
更重要的是,服务程序之间的依赖关系在 Zurg 配置文件里直接体现出来。比方说,在 Zurg 配置文件里指明 Web Server 依赖 Sudoku Solver,Web Server 的配置文件由 Zurg master 生成(可能会用到模板引擎,读入一个 Web Server 的配置模板),其中出现的 Sudoku Solver 的 host:port 由 Zurg master 自动填上,这样如果把 Sudoku Solver 从 hostA 迁移到 hostB,只需要改一处地方(Zurg 的配置),而 Sudoku Solver 和 Web Solver 的配置都由 Zurg master 自动生成。这样大大降低了犯错误的机会。
到了这一境界,分布式系统日常管理已经基本成熟,但在容错与负载均衡方面有较大的提升空间。
目前最大在障碍是 DNS,它限制了快速 Failover。比方说,如果 hostA 发生硬件故障,Zurg Master 固然可以在 hostB 上立刻启动 Sudoku Solver,但是如何通知 Web Server 到 hostB 上享用服务呢?修改 DNS entry 的话(把 hostA 的域名解析到 hostB 的 IP),可能要好几分钟才能完成更新,因为 DNS 没有推送机制。
如果思路受限制于 host:port,那么会采取一些看似高级,实则笨拙的高可用 (high availability) 解决方案。比方说在内核里做做手脚,设法让两台机器共享同一个 IP,然后通过专门的心跳连线来控制哪台 host 对外提供服务,哪台是备用机。如果那台“主机”发生故障,可以快速(几秒钟)切换到备用机,因为 hostname 和 IP 地址是相同的,客户端不用重新配置或重启,只要重新连接 TCP 就能完成 failover。如果在错误的道路上走得更远一点,可能还会设法把 TCP 连接一同迁移到备用机,这样客户端都不需要断开并重连。
Load balance 也受限于 DNS。
如果发现现有的 4 个 Sudoku Solver 不堪重负,又部署了 4 台 Sudoku Solver,如何通知各个 Web Server 把新的 Sudoku Solver 加到连接池里?
有一些 ad hoc 的手段,比方说每个 Web Server 有一个管理接口,可以透过这个接口向它动态地增减 Sudoku Solver 的地址。借助这个管理接口,我们也可以做一些计划中的联机迁移。比方说要主动把某个 Sudoku Solver 从 hostA 迁移到 hostB,我们可以先在 hostB 上启动 Sudoku Solver,然后透过 Web Server 的管理接口把 hostB:9981 添加到 Web Server 的连接池中,再把 hostA:9981 从连接池中删掉,最后停掉 hostA 上的 Sudoku Solver。这对计划中的 Sudoku Solver 升级是可行的,能做到避免中断 Web Server 服务。对于 failover,这种做法似乎稍显不够方便,因为要让 Zurg Master 理解 Web Server 的管理接口,会给系统带来循环依赖。(正常情况下,Zurg Master 不应该知道/访问它管理的服务程序的接口细节,这样 Sudoku Solver 升级的时候不用升级 Zurg Master。)
这种做法要求 Web Server 在开发的时候留下适当的维修探查通道,见陈硕《构建易于维护的分布式程序》中的推荐做法。
另外一种 ad hoc 的手段,每个 Sudoku Solver 在启动的时候自己主动往某个数据库表里 insert 或 update 本程序的 host:port。Web Server 的配置里写的不是 host:port,而是一条 SELECT 语句,用于找出它依赖的 Sudoku Solver 的 host:port,Web Server 还可以通过数据库触发器来及时获知 Sudoku Solver address list 的变化。这样增加或减少 Sudoku Server 的话,Web Server 几乎可以立刻应对,也不需要透过管理接口来手工增减 Sudoku Solver 地址。数据库在这里扮演了 naming service 的角色,它的可用性直接影响了整个系统的可用性。
境界 3 是黎明前的黑暗,只要统一引入 naming service,抛开 DNS,容错和负载均衡的问题迎刃而解。
境界4:机群管理与 naming service 结合
这是业内领先的公司的水平。
前面分析到,使用 Zurg 机群管理软件能大大简化分布式系统的日常运维,但是它也有很大的缺陷——不能实现快速 failover。如果系统规模大到一定程度,机器出故障的频率会显著增加,这时候自动化的快速 failover 是必备的,否则运维人员疲于奔命救火。
实现简单而快速的 failover 不需要特殊的编程技巧,也不需要对 kernel 动手脚,只要抛弃传统的 DNS 观念,摆脱 host:port 的束缚,采用为分布式系统特制的 naming service 代替 DNS 即可。

naming service 的功能是把一个 service_name 解析成 list of ip:port。比方说,查询 "sudoku_solver",返回 host1:9981、host2:9981、host3:9981。
naming service 与 DNS 最大的不同在于它能把新的地址信息推送给客户端。比方说,Web Server 订阅了 "sudoku_solver",每当 sudoku_solver 发生变化,Web Server 就会立刻收到更新。Web Server 不需要轮询,而是等候通知。
naming service 谁负责更新?
在境界 2 中,Sudoku Solver 会自己主动去 naming server 注册。到了境界 3,由于 Sudoku Solver 是有 Zurg 负责启动,那么 Zurg 知道 Sudoku Solver 运行在哪些 hosts 上,它会主动更新 naming service,不需要 Sudoku Solver 自己动手。
naming service 的可用性(availability)和一致性如何保证?
毫无疑问,一旦采用这种方案,naming service 是系统正常运转的关键,它的可用性决定了系统的可用性。naming service 绝对不能只 run 在一台服务器上,为了可靠性,应该用一组(通常是 5 台)服务器同时提供服务,当然,这需要解决一致性问题。目前实现高可用 naming service 的公认办法是 Paxos 算法,也有了一些开源的实现(ZooKeeper、KeySpace、Doozer)。
对程序设计的影响?
如果公司的网络库在设计的时候就考虑了 naming service,那么对程序设计来说是透明的。配置文件里写的不再是 host:port,而是 service_name,交给网络库去解析成 ip:port 地址列表。
为什么 muduo 网络库没有封装 DNS 解析?
一方面因为 gethostbyname() 和 getaddrinfo() 做 DNS 解析是阻塞的,我一时没有时间写一个非阻塞的 DNS 库;另一方面,因为在大规模分布式系统中 DNS 的作用不大,我宁愿花时间实现一个 naming service,并且为它编写 name resolve library。
在境界 3 中,每个项目组有自己的 hosts,只运行本项目中的服务程序,每个服务程序的 TCP 端口可以静态分配(比如 Sudoku Solver 固定使用 9981 端口),不担心端口冲突。如果公司规模继续扩大,迟早会把 16-bit 的 port 命名空间用完,这时候给新项目分配端口号将成为问题。
到了境界 4,这一限制将被打破,服务程序可以 run 在公司内任何一台 host 上,也不用担心端口冲突,因为 Zurg 会选择当前 host 的空闲端口来启动 Sudoku Solver,并且把选中的端口保存在 naming service 中。这样一来,TCP port 也实现了动态配置,Web Server 完全能自动适应 run 在不同 port 的 Sudoku Solver。