老韩头的开发日常 ☞ 【好书学习】系列
通过odoo框架,我们可以开发大型且复杂的应用。良好的性能是实现这一目标的基础。本章,我们将探讨如何提高应用性能。同时,我们也会讲解找出影响性能的因素。
本章包含以下内容:
- 记录集的预读取模式
- 将数据在内存中缓存
- 生成不同尺寸的图片
- 访问组数据
- 一次性创建或写多条数据
- 通过数据库查询访问数据
- 优化python代码
记录集的预读取模式
当我们访问数据时,内部其实是执行了SQL查询。如果我们在一个多条数据的数据集读取数据时,由于内部执行了多条SQL语句,这可能导致系统响应会比较慢。本节,我们将探讨如何通过预读取的方式优化效率。通过如下预读取模式,我们可以减少SQL查询的数量,进而优化系统性能。
步骤
下面的代码是计算函数。在这个方法中,self是包含多条数据的数据集。当我们直接在数据集进行迭代查询的时候,预取可以完美地工作:
# Correct prefetching
def compute_method(self):
for rec in self:
print(rec.name)
但是在某些场景下,预加载将变得十分复杂。比如,当通过browse方法获取数据的时候。在下面的例子中,我们通过for循环一个个的获取数据。这时将执行多次的SQL查询,效率就比较低了:
# Incorrect prefetching
def some_action(self):
record_ids = []
self.env.cr.execute("some query to fetch record id")
for rec in self.env.cr.fetchall():
record = self.env['res.partner'].browse(rec[0])
print(record.name)
通过将ID的列表传给browse方法,我们可以创建一个包含多条数据的数据集。如下代码,预加载将工作的非常完美:
# Correct prefetching
def some_action(self):
record_ids = []
self.env.cr.execute("some query to fetch record id")
record_ids = [rec[0] for rec in self.env.cr.fetchall()]
recordset = self.env["res.partner"].browse(record_ids)
for record_id in recordset:
print(record.name)
这种方式,将在一个SQL查询的情况下实现预加载。
原理
当我们操作多数据集的时候,通过预加载可以减少SQL查询的数量。它可以通过一次性获取所有的数据。通常,预加载是odoo内部自动实现的,但是在某些场景下将失去此特性。比如,我们像如下方式分割数据:
recs = [r for r in recordset r.id not in [1,2,4,10]]
由于我们将数据集拆分成几部分,因此odoo内部将无法实现一次性预加载。
通过正确的预加载可以大幅提高对象-关系映射(Object-Relational Mapping,ORM)的性能。当我们通过for循环迭代数据集的时候,在第一次迭代访问字段值的时候,预加载将发挥其魔力。预加载将加载数据集所有的数据。后续,我们再迭代的时候将直接通过从缓存读取。这可以将SQL查询的复杂的由O(n)降至O(1)。
我们假设数据集有10条数据。当我们在第一次循环中获取name字段的值,他将获取10条数据。并不只是name字段,而是10条数据的所有字段。后续迭代的数据将直接从缓存获取。复杂度将由10降至1。
for record in recordset: # recordset with 10 records
record.name # Prefetch data of all 10 records in the first
loop
record.email # data of email will be served from the cache.
预加载可以获取除*2many字段以外的字段的值。即便某些字段在循环体内并未使用。因为加载多余的字段所带来的性能影响远小于额外的查询。
小贴士
有时,预加载会降低性能。这时,我们可以通过recordset.with_context(prefetch_fields=Flase)禁用预加载。
预加载机制使用的是环境内存存储和检索记录值。这就意味着,一旦数据从数据库检索出来,后续所有的数据都将从缓存查询。我们可以通过env.cache获取环境缓存。我们可以使用invalidate_cache()函数禁用缓存。
更多
如果我们分隔了数据集,ORM将重新生成带有新的预加载上下文的数据集。这时,这些数据集将仅加载其自身代表的数据的内容。如果我们打算在预加载后加载所有的数据,我们可以使用with_pretetch()函数。在下面的例子中,我们将数据集分割为两部分。我们在两个记录集中都传递了一个通用的预取上下文,所以当你从其中一个记录中获取数据时,ORM会为另一个获取数据并将数据放入缓存中以备将来使用:
recordset = ... # assume recordset has 10 records.
recordset1 = recordset[:5].with_prefetch(recordset._ids)
recordset2 = recordset[5:].with_prefetch(recordset._ids)
预取上下文不限于拆分记录集。您也可以使用with_ prefetch()方法在多个记录集之间拥有一个公共的预取上下文。这意味着当您从一条记录中获取数据时,它也会为所有其他记录集获取数据。
将数据在内存中缓存
odoo框架提供了ormcache装饰器管理内存缓存。本节,我们将探讨如何管理缓存。
步骤
ORM缓存类定义在/odoo/tools/cache.py中。
引入文件:
from odoo import tools
ormcache
这是最常用的缓存装饰器。您需要传递方法输出所依赖的参数名。下面是一个带有ormcache装饰器的示例方法:
@tools.ormcache('mode')
def fetch_mode_data(self, mode):
# some calculations
return result
当我们首次调用该函数的时候,将会返回计算值。ormcache将会存储mode的值及result的值。如果我们再次调用该函数,且mode的值为之前存在的值时,将直接返回result的值。
有时,我们的函数依赖于环境属性。比如:
@tools.ormcache('self.env.uid', 'mode')
def fetch_data(self, mode):
# some calculations
return result
该函数将根据当前用户及mode的值存储result的值。
ormcache_context
该装饰器与ormcache类似,不同的是它依赖于参数和上下文中的值。我们需要传入参数名称及上线文键的列表。例如,我们的输出依赖于上下文的lang及website_id,如下:
@tools.ormcache_context('mode', keys=('website_id', 'lang'))
def fetch_data(self, mode):
# some calculations
return result
该缓存将依赖于mode及context中的值
ormcache_multi
有些方法对多个记录或id执行操作。如果你想在这些方法上添加缓存,你可以使用ormcache_multi装饰器。您需要传递multi参数,在方法调用期间,ORM将通过迭代该参数生成缓存键。在这个方法中,您将需要以字典格式返回结果,并以multi参数的元素作为键。看看下面的例子:
@tools.ormcache_multi('mode', multi='ids')
def fetch_data(self, mode, ids):
result = {}
for i in ids:
data = ... # some calculation based on ids
result[i] = data
return result
假设我们用[1,2,3]作为id调用前面的方法。该方法将返回一个结果{1:…2:…3:…}格式。ORM将基于这些键缓存结果。如果你用[1,2,3,4,5]作为ID进行另一个调用,你的方法将接收[4,5]作为ID参数,所以方法将执行4和5个ID的操作,其余的结果将从缓存中提供。
原理
ORM缓存以字典的形式保存缓存(缓存查找)。该缓存的键将基于装饰方法的签名生成,结果将是值。简单地说,当您使用x, y参数调用方法时,方法的结果是x+y,缓存查找将是{(x, y): x+y}。这意味着下次使用相同的参数调用该方法时,结果将直接从该缓存中提供。这节省了计算时间,使响应更快。
ORM缓存是一个内存缓存,所以它被存储在RAM中并占用内存。不要使用ormcache来提供大型数据,例如图像或文件。
警告
使用此装饰器的方法永远不应返回记录集。如果您这样做,它们将生成psycopg2.OperationalError,因为记录集的基础游标已关闭。
你应该在纯函数上使用ORM缓存。纯函数是指对于相同的参数总是返回相同结果的方法。这些方法的输出仅取决于参数,因此它们返回相同的结果。如果不是这种情况,则需要在执行使缓存状态无效的操作时手动清除缓存。要清除缓存,调用clear_cache()方法:
self.env[model_name].clear_caches()
一旦清除了缓存,下一个对方法的调用将执行该方法并将结果存储在缓存中,所有具有相同参数的后续方法调用都将从缓存中提供服务。
更多
ORM缓存是Least Recently
Used(LRU),这意味着如果一个键在缓存中不经常使用,它将被删除。如果你没有正确地使用ORM缓存,它可能弊大于利。例如,如果在方法中参数总是不同的,那么每次Odoo都会先在缓存中查找,然后调用方法来计算。如果你想了解你的缓存是如何执行的,你可以把SIGUSR1信号传递给Odoo进程:
kill -SIGUSER1 496
其中,496为进程号。执行命令后,可以在日志中看到ORM缓存的状态。
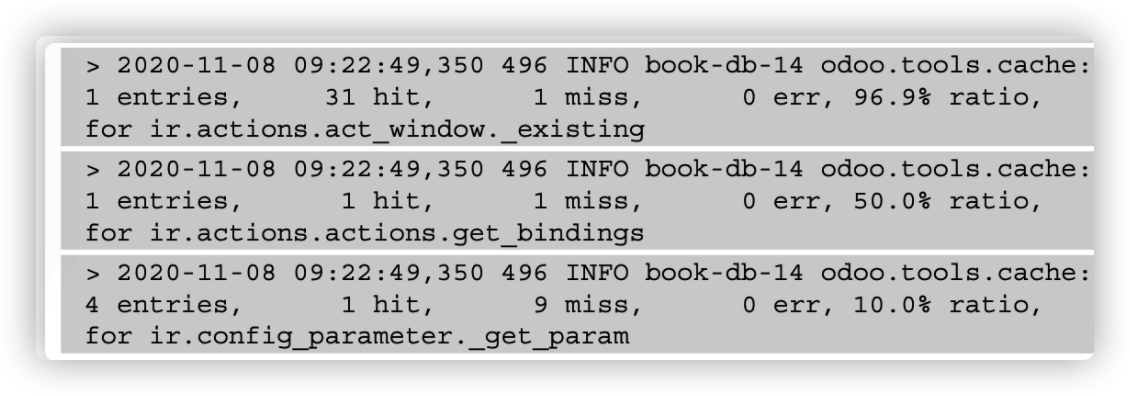
缓存中的百分比是命中率。它是在缓存中找到结果的成功率。如果缓存的命中率太低,你应该从方法中删除ORM缓存。
生成不同尺寸的图片
大图片对任何网站来说都是麻烦的。它们增加了网页的大小,结果使网页变慢。这就导致了不好的SEO排名和访问者流失。本节,我们将探索如何创建不同大小的图像;通过使用正确的图像,您可以减少网页大小和改善页面加载时间。
步骤
您将需要继承image.mixin。如下:
class LibraryBook(models.Model):
_name = 'library.book'
_description = 'Library Book'
_inherit = ['image.mixin']
mixin模型将自动添加5个字段,用于存储不同大小的图片。
步骤
image.mixin实例将自动向模型添加5个新的二进制字段。每个字段存储具有不同分辨率的图像。以下是这些领域及其解决方案的列表:
- image_1920: 1,920x1,920
- image_1024: 1,024x1,024
- image_512: 512x1,512
- image_256: 256x256
- image_128: 128x128
在这里给出的所有字段中,只有image_1920是可编辑的。其他图像字段是只读的,当您更改image_1920字段时,它们会自动更新。因此,在模型的后端表单视图中,您需要使用image_1920字段来允许用户上传图像。但这样做,我们在表单视图中加载大image_1920图像。但是,有一种方法可以提高性能,即在form视图中使用image_1920图像,但是显示较小的图像。例如,我们可以使用image_1920字段,但显示image_128字段。要做到这一点,你可以使用以下语法:
<field name="image_1920" widget="image" options="{'preview_image': 'image_128'}" />
将图像保存到字段后,Odoo会自动调整图像的大小并将其存储到相应的字段中。form视图将显示转换后的image_128,因为我们使用它作为preview_image。
小贴士
image.mixin模型是AbstractModel,所以它的表不在数据库中。为了使用它,您需要在模型中继承它。
image.mixin,您可以存储的图像的最大分辨率为1920 × 1920。如果您保存的图像分辨率高于1920 x1920, Odoo会将其降低为1920 x1920。在这样做的同时,Odoo还将保留图像的分辨率,避免任何失真。例如,如果您上传的图像分辨率为2,400x1,600,那么image_1920字段的分辨率将为1,920x1,280。
更多
image.mixin,你可以获得特定分辨率的图像,但是如果你想使用另一种分辨率的图像呢?为此,您可以使用二进制包装字段图像,如下面的示例所示:
image_1500 = fields.Image("Image 1500", max_width=1500, max_ height=1500)
这将创建一个新的image_1500字段,存储图像将把它的分辨率调整为1500 x1500。注意,这不是image.mixin的一部分。它只是将图像缩小为1,500x1,500,因此需要在form视图中添加该字段;编辑它不会改变image.mixin中的其他图像字段。如果您想将其与现有的图像链接。在字段定义中添加related="image_1920"属性。
访问组数据
当需要用于统计的数据时,通常需要以分组的形式提供数据,例如月度销售报告,或者显示每个客户销售额的报告。手动搜索记录并将它们分组是很耗时的。在这篇文章中,我们将探讨如何使用read_group()方法访问分组数据。
步骤
小贴士
read_group()方法广泛用于统计和智能统计按钮。
- 让我们假设您想要在合作伙伴表单上显示销售订单的数量。这可以通过搜索客户的销售订单,然后计算长度来实现:
# in res.partner model
so_count = fields.Integer(compute='_compute_so_count', string='Sale order count')
def _compute_so_count(self):
sale_orders = self.env['sale.order'].search(domain=[('partner_id', 'in', self.ids)])
for partner in self:
partner.so_count = len(sale_orders.filtered(lambda so: so.partner_id.id == partner.id))
前面的示例可以工作,但不是最优的。当您在树视图上显示so_count字段时,它将获取并过滤列表中所有合作伙伴的销售订单。对于这样少量的数据,read_group()方法不会产生太大的影响,但随着数据量的增长,它可能会成为一个问题。要修复这个问题,可以使用read_ group方法。
- 下面的示例与前面的示例相同,但它只使用一个SQL查询,即使是大型数据集:
# in res.partner model
so_count = fields.Integer(compute='_compute_so_count', string='Sale order count')
def _compute_so_count(self):
sale_data = self.env['sale.order'].read_group(domain=[('partner_id', 'in', self.ids)],fields=['partner_id'], groupby=['partner_id'])
mapped_data = dict([(m['partner_id'][0], m['partner_id_count']) for m in sale_data])
for partner in self:
partner.so_count = mapped_data[partner.id]
前面的代码片段是优化的,因为它直接通过SQL的group BYfeature获取销售订单计数。
原理
read_group()方法在内部使用SQL的GROUP BY特性。这使得read_group方法更快,即使你有大的数据集。在内部,Odoo web客户端在图表和分组树视图中使用这种方法。您可以通过使用不同的参数来调整read_group方法的行为。
让我们来研究read_group方法:
def read_group(self, domain, fields, groupby, offset=0, limit=None, orderby=False, lazy=True):
read_group方法可用的不同参数如下:
- domain: 这用于过滤记录。这将是read_group方法的搜索条件。
- fields: 这是要在分组中获取的字段列表。注意,这里提到的字段应该在groupby参数中,除非您使用一些聚合函数。read_group方法支持SQL聚合函数。假设您想要得到每个客户的平均订单量。在这种情况下,可以使用read_group,如下所示:
self.env['sale.order'].read_group([], ['partner_id', 'amount_total:avg'], ['partner_id'])
如果您想两次访问同一个字段,但使用不同的聚合函数,则语法略有不同。您需要将字段名作为别alias:agg(field_ name)。这个例子会给你每个客户的总订单数和平均订单数:
self.env['sale.order'].read_group([], ['partner_id',
'total:sum(amount_total)', 'avg_total:avg(amount_ total)'], ['partner_id'])
- groupby: 该参数将是记录分组的字段列表。它允许您基于多个字段对记录进行分组。为此,您需要传递一个字段列表。例如,如果您想按客户和订单状态对销售订单进行分组,可以在此参数中传递['partner_id ', 'state']。
- offset: 此参数用于分页。如果要跳过几条记录,可以使用此参数。
- limit: 此参数用于分页;它表示可以获取的最大记录数。
- lazy: 这个参数接受布尔值。缺省值为True。如果该参数为真,则只根据groupby参数中的第一个字段对结果进行分组。您将在__context中获得剩余的groupby参数和域,并在结果中获得__domain键。如果该参数的值设置为False,它将根据groupby参数中的所有字段对数据进行分组。
更多
根据日期字段进行分组可能比较复杂,因为可以根据天、周、季度、月或年对记录进行分组。您可以通过在groupby参数的:后面传递groupby_function来更改date字段的分组行为。如果你想把每月的销售订单总数分组,你可以使用read_group方法:
日期分组的可能选项有日、周、月、季和年。
参考
如果您想了解更多关于PostgreSQL聚合函数的信息,请参考文档:https://www.postgresql.org/docs/current/functions-aggregate.html 。
一次性创建或写多条数据
如果您是Odoo开发新手,您可能会执行多个查询来编写或创建多个记录。本节,我们将了解如何批量创建和写入记录。
步骤
创建多个记录并在多个记录上写入数据对于每个记录的工作原理是不同的。让我们逐个看一下这些记录。
创建多数据
Odoo支持批量创建记录。如果要创建单个记录,只需传递一个包含字段值的字典。要在批处理中创建记录,您只需要传递这些字典的列表,而不是单个字典。下面的示例在一个create调用中创建三条图书记录:
vals = [
{
"name": "Book1",
"date_release": "2018/12/12",
},
{
"name": "Book2",
"date_release": "2018/12/12",
},
{
"name": "Book3",
"date_release": "2018/12/12",
},
]
self.env["library.book"].create(vals)
写多条数据
如果您正在处理Odoo的多个版本,那么您应该意识到write方法在底层是如何工作的。在版本13中,Odoo写方式有所不同。它使用一种延迟的更新方法,这意味着它不会立即将数据写入数据库。Odoo只在必要时或调用flush()时才将数据写入数据库。
如下:
# Example 1
data = {...}
for record in recordset:
record.write(data)
# Example 2
data = {...}
recordset.write(data)
如果您使用的是Odoo v13或以上版本,那么就不会有任何性能方面的问题。但是,如果您使用的是较旧的版本,则第二个示例将比第一个示例快得多,因为第一个示例将在每次迭代中执行一个SQL查询。
原理
为了在批处理中创建多个记录,您需要以列表的形式传递值字典来创建新记录。这将自动管理批量创建记录。当您在批处理中创建记录时,在内部这样做将为每个记录插入一个查询。这意味着在批处理中创建记录不是在单个查询中完成的。然而,这并不意味着批量创建记录不能提高性能。通过批量计算获得性能增益。
write方法的工作方式有所不同。大多数事情都由框架自动处理。例如,如果在所有记录上写入相同的数据,则只需要一个UPDATE查询就可以更新数据库。如果你在同一个事务中一次又一次地更新相同的记录,框架甚至会处理它,如下所示:
recordset.name= 'Admin'
recordset.email= 'admin@example.com'
recordset.name= 'Administrator'
recordset.email= 'admin-2@example.com'
在前面的代码片段中,对于write只执行一个查询,其最终值为name=Administrator和email=admin-2@example.com。这不会对性能造成不好的影响,因为分配的值在缓存中,稍后会在单个查询中写入。
如果在两者之间使用flush()方法,情况就不一样了,如下面的示例所示:
recordset.name= 'Admin'
recordset.email= 'admin@example.com'
recordset.flush()
recordset.name= 'Administrator'
recordset.email= 'admin-2@example.com'
flush()方法的作用是:将缓存中的值更新到数据库。因此,在前面的示例中,将执行两个更新查询;一个查询在刷新之前有数据,第二个查询在刷新之后有数据。
更多
延迟的更新仅适用于Odoo版本13,如果您使用的是较旧的版本,那么写入单个值将立即执行更新查询。检查以下示例来探索老版本Odoo的写操作的正确用法:
# incorrect usage
recordset.name= 'Admin' recordset.email= 'admin@example.com'
# correct usage
recordset.write({'name': 'Admin', 'email'= 'admin@example. com'})
在第一个示例中,我们有两个UPDATE查询,而第二个示例只有一个更新查询。
通过数据库查询访问数据
Odoo ORM的方法有限,有时很难从ORM中获取某些数据。在这种情况下,您可以按照需要的格式获取数据,并且需要对数据进行操作才能得到特定的结果。因此,它会变慢。为了处理这些特殊情况,您可以在数据库中执行SQL查询。在这个食谱中,我们将探索如何从Odoo运行SQL查询。
步骤
使用self._cr.execute方法
- 添加代码
self.flush()
self._cr.execute("SELECT id, name, date_release FROM library_book WHERE name ilike %s", ('%odoo%',))
data = self._cr.fetchall()
print(data)
Output:
[(7, 'Odoo basics', datetime.date(2018, 2, 15)), (8, 'Odoo 11 Development Cookbook', datetime.date(2018, 2, 15)), (1, 'Odoo 12 Development Cookbook', datetime. date(2019, 2, 13))]
- 查询的结果将以元组列表的形式出现。元组中的数据与查询中的字段的顺序相同。如果你想获取字典格式的数据,你可以使用dictfetchall()方法。看看下面的例子:
self.flush()
self._cr.execute("SELECT id, name, date_release FROM library_book WHERE name ilike %s", ('%odoo%',))
data = self._cr.dictfetchall()
print(data)
Output:
[{'id': 7, 'name': 'Odoo basics', 'date_release': datetime.date(2018, 2, 15)}, {'id': 8, 'name': 'Odoo 11 Development Cookbook', 'date_release': datetime. date(2018, 2, 15)}, {'id': 1, 'name': 'Odoo 12 Development Cookbook', 'date_release': datetime. date(2019, 2, 13)}]
如果你只想获取一条记录,你可以使用fetchone()和dictfetchone()方法。这些方法的工作原理类似于fetchall()和dictfetchall(),但它们只返回一条记录,如果您想获取多条记录,则需要多次调用fetchone()和dictfetchone()方法。
原理
有两种方法可以从记录集访问数据库游标:一种是从记录集本身,如self._cr,另一个来自环境,特别是self.env.cr。此游标用于执行数据库查询。在前面的示例中,我们看到了如何通过原始查询获取数据。表名是替换后的型号名称。用_表示库。图书模型变成了library_book。
如果你注意到了,我们在执行查询之前使用了self.flush()。这背后的原因是Odoo过度使用缓存,数据库可能没有正确的值。self.flush()会将所有延迟的更新推送到数据库,并执行所有相关的计算,这样你就会从数据库中获得正确的值。flush()方法还支持一些参数,这些参数可以帮助您控制数据库中正在刷新的内容。参数说明如下:
- fname: 要刷新到数据库的字段列表。
- records: 要刷新到数据库的数据集。
如果您正在执行INSERT或UPDATE查询,您还需要在执行查询之后执行flush(),因为ORM可能不知道您所做的更改,而且它可能已经缓存了记录。
在执行原始查询之前,需要考虑一些事情。只有在别无选择时才使用原始查询。通过执行原始查询,您绕过了ORM层。因此,您也绕过了安全规则和ORM的性能优势。有时,错误构建的查询可能会引入SQL注入漏洞。考虑以下示例,其中查询可能允许攻击者执行SQL注入:
# very bad, SQL injection possible
self.env.cr.execute('SELECT id, name FROM library_book WHERE name ilike + search_keyword + ';')
# good
self.env.cr.execute('SELECT id, name FROM library_book WHERE name ilike %s ';', (search_keyword,))
也不要使用字符串格式函数;它还允许攻击者执行SQL注入。使用SQL查询会使其他开发人员难以阅读和理解您的代码,所以尽可能避免使用它们。
信息
许多Odoo开发人员认为,执行SQL查询可以使操作更快,因为它绕过了ORM层。然而,这并不完全正确;这要看具体情况。在大多数操作中,ORM比原始查询执行得更好更快,因为数据是从记录集缓存中提供的。
更多
在一个事务中完成的操作只在事务结束时提交。如果ORM中发生错误,事务将回滚。如果你已经做了一个插入或更新查询,并且你想让它永久存在,你可以使用self._cr.commit()来提交更改。
小贴士
注意,使用commit()可能是危险的,因为它可能将记录置于不一致的状态。ORM中的错误可能会导致不完全回滚,所以只有在你完全确定自己在做什么时才使用commit()。
如果使用了commit()方法,那么之后就不需要使用flush()。commit()方法在内部刷新环境。
优化python代码
有时,你将无法查明问题的原因。在性能问题上尤其如此。Odoo提供了一些内置的分析工具,可以帮助您找到问题的真正原因。
步骤
- odoo的分析器可以在Odoo /tools/profiler.py上找到。为了在你的代码中使用profiler,请将它导入文件:
from odoo.tools.profiler import profiler
- 导入之后,您可以在这些方法上使用概要文件装饰器。要对一个特定的方法进行概要分析,您需要向它添加概要分析装饰器。看一下下面的例子。我们把概要文件装饰器放在make_available方法中:
@profile
def make_available(self):
if self.state != 'lost':
self.write({'state': 'available'})
return True
- 当这个方法被调用时,它将在日志中打印完整的统计信息:
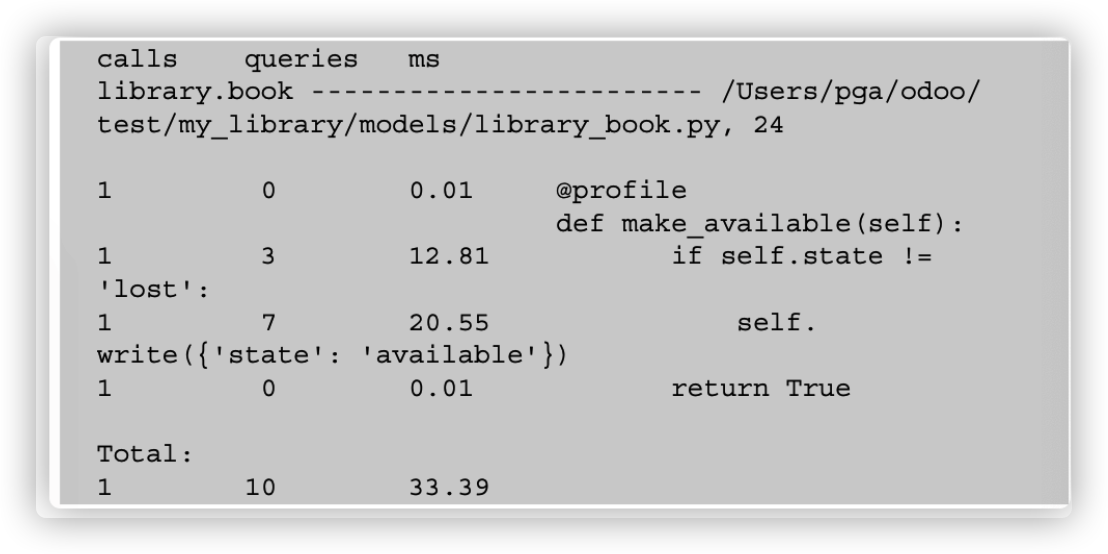
原理
在方法上添加profile装饰器之后,当您调用该方法时,Odoo将在日志中打印完整的统计信息,如前面的示例所示。它将以三列的形式打印统计数据。第一列将包含调用的次数或执行一行的次数。(当该行处于for循环中或方法是递归的时候,这个数字会增加。)第二列表示用给定行触发的查询的数量。最后一列是给定行所花费的时间,以毫秒为单位。注意,此列中显示的时间是相对的;当分析器关闭时,它会更快。
分析器装饰器接受一些可选参数,这些参数可以帮助您获得该方法的详细统计信息。下面是profiler装饰器的定义:
def profile(method=None, whitelist=None, blacklist=(None,), files=None, minimum_time=0, minimum_queries=0):
下面是profile()方法支持的参数列表:
- whiltelist: 在日志中显示的模型名称列表。
- files: 要显示的文件名列表。
- blacklist: 不希望在日志中显示的模型名称列表。
- minimum_time: 这将接受一个整数值(以毫秒为单位)。它将隐藏总时间小于给定时间的日志。
- minimum_queries: 这将接受查询数的整数值。它将隐藏查询总数小于给定数量的日志。
更多
Odoo中还有一种类型的分析器可以为执行的方法生成图表。这个分析器可以在misc包中找到,所以您需要从那里导入它。它将生成一个带有统计数据的文件,该数据将生成一个图形文件。要使用这个分析器,您需要将文件路径作为参数传递。当这个函数被调用时,它将在给定的位置生成一个文件。看一下下面的示例,它生成make_available.prof文件:
from odoo.tools.misc import profile
...
@profile('/Users/parth/Desktop/make_available.profile')
def make_available(self):
if self.state != 'lost':
self.write({'state': 'available'})
self.env['res.partner'].create({'name': 'test', 'email': 'test@ada.asd'})
return True
当调用make_available方法时,它将在桌面上生成一个文件。要将此数据转换为图形数据,您需要安装gprof2dot工具,然后执行以下命令生成图形:
gprof2dot -f pstats -o /Users/parth/Desktop/prof.xdot /Users/ parth/Desktop/make_available.profile
这个命令将在桌面上生成prof.xdot文件。然后,您可以使用以下命令用xdot显示图形:
xdot /Users/parth/Desktop/prof.xdot
使用上述xdot命令将生成如下图所示的图形:
