文件基本操作
r,以读模式打开, r+=r+w,
w, 写模式(清空原来的内容), w+=w+r,
a , 追加模式, a+=a+r,
rb, wb, ab, b表示以二进制文件打开
想在一段文字的中间添加内容, 则用 r+
文件函数:
f.read(), 读取全部; f.read(size)表示size个字节的数据 , 返回字符串
f.write(), 没有writeline函数
f.readline()读取一行,
f.readlines() 读取多行, 形成一个list
f.writelines()
f.close()
f.seek() 控制指针, seek(offset, whence=0)
whence=0 文件头部, 1表示当前位置, 2表示文件尾部; 默认为0
f.seek(50,1) 表示指针往后移动50个字节
实例1:
txt的原文如下:
12345678
I cant
I am home.
# f=open(r'C:UsersxuyinDesktop estwordcnt.txt','r') 这种也对 f=open('C:\Users\xuyin\Desktop\test\wordcnt.txt','r') print(f.read()) # 全部读取 f.seek(0,0) # 回到初始位置 print(f.read(4)) # 读前4个字符, 包括标点 1234 print(f.readline()) # 上一行代码结果接下去这一行 5678 print(f.tell()) #10 当前的位置 也算入的 f.close() # 关闭文件
上述f=open() 的方法少用, 一般常用with open() as f: 用了这个不用写f.close()了
实例2: 读取文件内容/增加文件内容
现在桌面上有个txt 内容如下

with open(r'C:UsersxuyinDesktop estaaa.txt','r')as f: x1=f.read() #得到一个字符串 print(type(x1)) print(x1) f.seek(0,0) print(1) x2=f.readline()#得到第一行,形成字符串 print(type(x2)) print(x2) # f.seek(0,0),没有这行则读取剩下的全部行 print(f.readlines()) #得到一个列表,每行作为一个元素
得到
<class 'str'>
what do you like?
both123
thank you
1
<class 'str'>
what do you like?
['both123 ', 'thank yousee you!']
with open(r'C:UsersxuyinDesktop estaaa.txt','w+')as f: f.write('what do you like? both')#清空原来的重新写 f.writelines('123 ')#接着写, f.writelines('thank you') f.seek(0,0) print(1) print(f.read())
1
what do you like?
both123
thank you
#从末尾开始写: with open(r'C:UsersxuyinDesktop estaaa.txt','a+')as f: f.write('see you!') f.seek(0,0) print(f.read())
what do you like?
both123
thank yousee you!
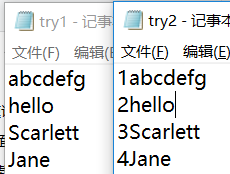
实例3:将文件try1 中的字符串加上序号1,2,3写道try2中
代码
with open(r'C:Usersxuying_fallDesktop est ry1.txt','r') as f1: str1=f1.readlines() for i in range(0,len(str1)): str1[i]=str(i+1)+''+str1[i] # str()函数把数值转为字符串! with open(r'C:Usersxuying_fallDesktop est ry2.txt','w') as f2: f2.writelines(str1)
注意事项:
with open(r'C:Usersxuying_fallDesktop est ry2.txt','r+') as f3: f3.write('winter')
winter 覆盖了原来的文件头部, 不是插入!
实例4: 合并文件内容已知桌面的两个文件 tell.txt 和mail.txt, 现在需要合并他们, 新建一个txt ,有三列数据!!
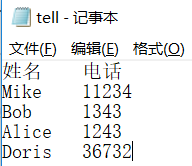

f1=open(r'C:UsersxuyinDesktop est ell.txt','r') f1.readline() # 跳过第一行 line1=f1.readlines() f2=open(r'C:UsersxuyinDesktop estmail.txt','r') f2.readline() # 跳过第一行 line2 = f2.readlines() name1=[] # 新列表 用于存储 tel1=[] name2=[] mail2=[] for line in line1: elements=line.split() name1.append(str(elements[0])) tel1.append(str(elements[1])) for line in line2: elements=line.split() name2.append(str(elements[0])) mail2.append(str(elements[1])) lines=[] # 生成新数据 lines.append('姓名 telephone mailbox ') for i in range(len(name1)): s='' if name1[i] in name2: j=name2.index(name1[i]) # name1[i]在name2中的下标 s=' '.join([name1[i],tel1[i],mail2[j]]) s=s+' ' else: s=' '.join([name1[i],tel1[i],str('---')]) s = s + ' ' lines.append(s) print(1) # 处理name2 中剩下的信息不全的(没有) for i in range(len(name2)): s='' if name2[i] not in name1: s = ' '.join([name2[i], str('---'), mail2[i]]) s = s + ' ' lines.append(s) # 写入新文件中 f3=open(r'C:UsersxuyinDesktop estinfo_telmail.txt', 'w') f3.writelines(lines) f1.close() f2.close() f3.close()
结果

实例6: 利用字典实现wordcnt.txt文件中的词频统计, 文件内容如下
hello. do you like holiday?
you can do it.
you will join me later.
需要统计文件中的每个单词出现频数
# (三)利用字典实现词频统计 def process(line,wordcnt): line=replacepunctuations(line) # 用空格代替标点 words=line.split() for i in words: # 从每一行获取每一个字母 if i in wordcnt: wordcnt[i]+=1 else: wordcnt[i]=1 # 新增一项该词汇 def replacepunctuations(line): for ch in line: # 遍历每一个单词 if ch in '~?@#$,.[]{}'"": line=line.replace(ch,' ') return line f=open(r'C:Usersxuying_fallDesktop estwordcnt.txt','r') # 只读模式打开文件 wordcnt={} # 新建一个字典 for line in f: #遍历每一个行 process(line.lower(),wordcnt) # 全部小写, 不区分大小写了 pairs=list(wordcnt.items()) # 列表化 print(pairs) items=[(x,y) for (y,x) in pairs] # 交换下顺序 items.sort() # 根据单词次数从小到大排列 print(items) #[(1, 'can'), (1, 'hello'), (1, 'holiday'), (1, 'it'), (1, 'join'), (1, 'later'),
# (1, 'like'), (1, 'me'), (1, 'will'), (2, 'do'), (3, 'you')]
(二)os module 应用
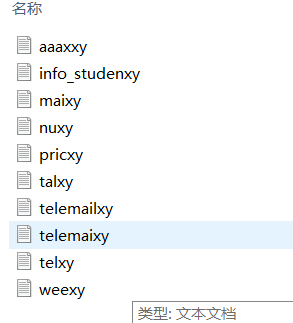
#改变某个文件下的所有文件的文件名 import os import time #用于计算运行时间 #'连接符'.join(list) 将列表组成字符串 def change_name(path): global i #用于统计处理的文件个数 if not os.path.isdir(path) and not os.path.isfile(path): #检查给出的路径是否为一个文件或者目录 return False if os.path.isfile(path): print(222) file_path = os.path.split(path) #分割出目录名与文件名 lists = file_path[1].split('.') #分割出文件名称与文件的扩展名 file_ext = lists[-1] #取出后缀名(列表切片操作) # print file_ext txt1=['txt','doc'] if file_ext in txt1: #rename(old,new) os.rename(path,file_path[0]+'/'+lists[0]+'_xy.'+file_ext) new_name=lists[0] print(new_name) # aaa print(type(new_name)) # <class 'str'> print(len(new_name)) #3 new_name=new_name[0:len(new_name)-1]#删除名字的最后一个字母 new_name=new_name+'xy' # 新增两个字符 print (new_name) # aaaxy os.rename(path,file_path[0]+'/'+new_name+'.'+file_ext) # print type(lists[0]) # os.rename(path,file_path[0]+'/'+lists[0]+'_xy.'+file_ext) i+=1 #统计文件个数 elif os.path.isdir(path): print(111) for x in os.listdir(path):#返回该目录下的所有文件与目录名 print(x) change_name(os.path.join(path,x)) #os.path.join()在路径处理上很有用,用于合并目录 txt_dir = 'C:\Users\xuyin\Desktop\test\aaa.txt' txt_dir = txt_dir.replace('\','/') start = time.time() i = 0 change_name(txt_dir) c = time.time() - start print('程序运行耗时:%0.2f'%(c)) print('总共处理了 %s 个文件'%(i))
上述txt_dir = 'C:\Users\xuyin\Desktop\test\aaa.txt' 是一个文件, 因此 print(222) 运行
若修改为txt_dir = 'C:\Users\xuyin\Desktop\test' 则是一个文件夹 , 因此 print(111) 运行
结果:
程序运行耗时:0.12
总共处理了 10 个文件
文件批量重命名结果如下:
归纳os 常用函数:
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
返回一个路径的目录名和文件名:os.path.split()
os.path.split('/home/swaroop/byte/code/poem.txt')
结果:('/home/swaroop/byte/code', 'poem.txt')
分离扩展名:os.path.splitext()
os.path.splitext('C:\Users\xuyin\Desktop\test\aaa.txt') ('C:\Users\xuyin\Desktop\test\aaa', '.txt')
获取路径名:os.path.dirname()
获取文件名:os.path.basename()
os.path.dirname('C:\Users\xuyin\Desktop\test\aaa.txt') 'C:\Users\xuyin\Desktop\test' os.path.basename('C:\Users\xuyin\Desktop\test\aaa.txt') 'aaa.txt'
重命名:os.rename(old, new)(上例中已经有了)
os.path.join(x1,x2) :灰常有用!!!
os.path.join('d','dd') ans: 'd\dd'
os.mkdir("file") 创建目录
os.mkdir('haha'):表示创建一个haha文件夹(在当前目录下)
创建多级目录:os.makedirs(r“c:python est”)
os.makedirs('C:\Users\xuyin\Desktop\hahaa'):在桌面创建hahaa文件夹
复制文件:
import shutil
shutil.copyfile("oldfile","newfile") oldfile和newfile都只能是文件
shutil.copyfile('C:\Users\xuyin\Desktop\test\aaa.txt','C:\Users\xuyin\Desktop\hahaa\bbb.txt')
#上述操作复制并且rename了
复制文件夹:
shutil.copytree("olddir","newdir") olddir和newdir都只能是目录,且newdir必须不存在
shutil.copytree('C:\Users\xuyin\Desktop\hahaa','C:\Users\xuyin\Desktop\test1')
#复制hahaa文件夹为test1文件夹
重命名文件(目录)
os.rename("oldname","newname") 文件或目录都是使用这条命令
移动文件(目录)
shutil.move("oldpos","newpos")
删除文件
os.remove("file")
删除目录
os.rmdir("dir")只能删除空目录
shutil.rmtree("dir") 空目录、有内容的目录都可以删
获取文件大小:os.path.getsize(filename)