data compression可以使数据占用更少的空间,并且能使算法提速
什么是dimensionality reduction(维数约简)

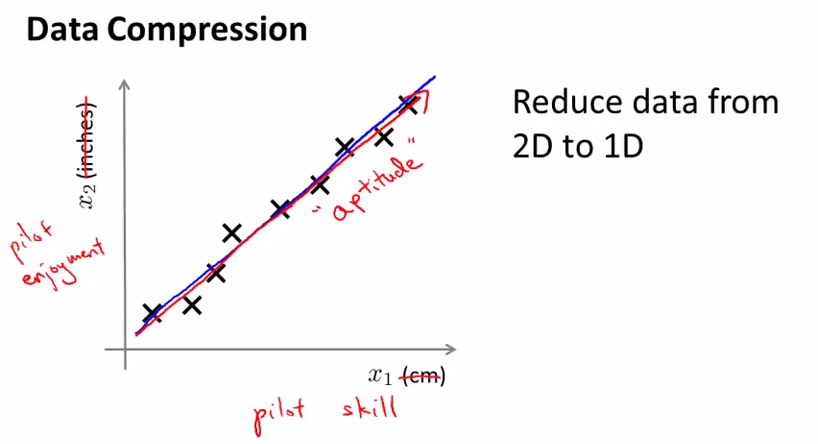
例1:比如说我们有一些数据,它有很多很多的features,取其中的两个features,如上图所示,一个为物体的长度用cm来度量的,一个也是物体的长度是用inches来度量的,显然这两上features是相关的,画到上图中,近似于一条直线,之所以点不在一条直线上,是因为我们在对物体测量长度是会取整(对cm进行取整,对inches进行取整),这样的就会产生误差。
在实际生活中这种情况很容易发生,如一个工程队给了你500个features,另一个工程队给了你300个features,第三个工程队给了你200个features,这样你就有1000个features,你很难知道这些features都是些什么,所以里面如果有相关的features你也不会知道,这样就会造成大量的冗余。
例2:右图的例子是关于飞行员的,如我们想对飞行员进行测试,一个feature x1是飞行员的飞行技术,一个feature x2是飞行员的工作愉快程度,这两个features是相关的,我们可以用一个feature(aptitude 资质 : 对角的那条直线)而不是两个features来表示,从而将数据从二维降到了一维
将二维数据约简到一维

如果我们的数据近似地在一条直线上,将数据投影到这条直线上,这样原来每个数据要用一个二维向量(x)表示它的位置,现在只需要一个实数(z)就能表示它的位置了
将3维数据降到2维
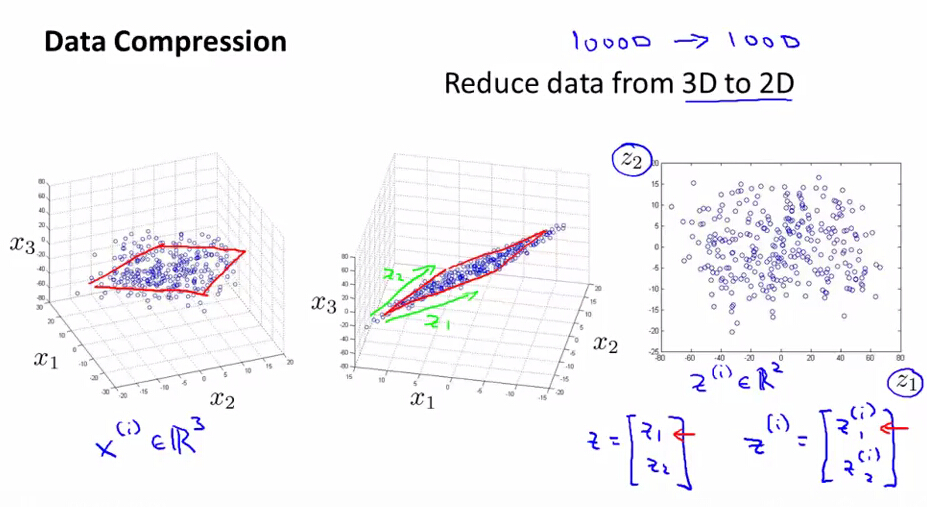
更多例子,是将1000维降到100维,这里从3维到2维只是举例,为了方便画图说明。
所有的点大致会落在一个平面上(或距某个平面不远),将所有数据投影到一个二维平面上,这样表示一个点从原来的需要三个数字变为后来的只需要二个数字
总结
data compression可以使数据占用更少的空间,并且能使算法提速