一、缓存雪崩现象
由于集群中某个memcached服务器宕机的原因,造成集群中的服务器命中率下降。只能通过访问数据库得到数据,是的数据库的压力倍增,造成数据库服务器崩溃。重启数据库还是会崩溃,但是数据会缓存一部分,多次重启则缓冲建立完毕。或者缓冲周期性的失效,比如每6个小时失效一次,那么每6个小时会有一个“峰值”,严重的会造成数据库崩溃。
二、案例
一个门户网站做的一个缓存,6小时缓存失效一次,失效后两个小时内mysql负载很高,然后mysql服务器挂掉。
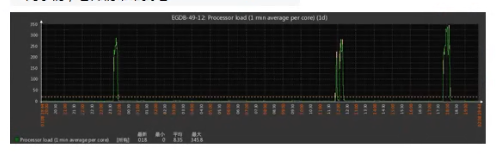
解决方案:
1.缓存失效时间设置为随机3到9小时失效,让读取mysql数据库的次数分散开,而非集中在一定时间。
2.将缓存时间调长,每天夜里刷新缓存数据。
三、缓存无底洞现象
memcached连接频率升高,效率下降,于是就增加memcache服务器,但是这种问题依然存在,这种现象称之为“无底洞现象”。出现这种现象是因为随着用户的增多,用户的信息会随机的存储在更多的memcache服务器上(一致性哈希算法),在获取某个用户的信息时,会导致连接服务器的频率增加。
解决方案:把某一组key,按共同前缀分布,比如:user表中的,user-133-name,user-133-age这2个key,在用分布式算法计算节点时,应该用“user-133”来计算,而不是用user-133-name/age来计算。2个关于个人信息的key都会落在一个服务器上,那么在访问的时候也只会在一个服务器上查询。