1.JVM
一个java程序运行后过程如下:(注:多个进程启动就会实例化多个虚拟机实例,进程退出或者关闭,虚拟机实例消亡,多个虚拟机实例之间不能共享数据)
java程序->编译器编译.class->JVM编译成机器码->机器码调用操作系统
再参考参考之前的记录https://www.cnblogs.com/yangj-Blog/p/12956247.html
JVM允许一个进程同时并发执行多个线程,
https://snailclimb.gitee.io/javaguide/#/docs/java/jvm/Java%E5%86%85%E5%AD%98%E5%8C%BA%E5%9F%9F
相关问题:
JVM内存结构介绍下?
答:
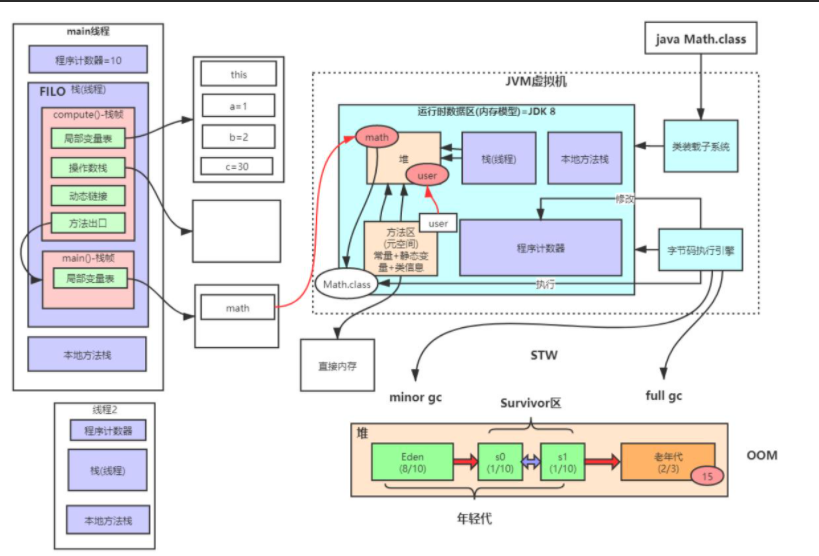
jvm的内存结构主要分为3大块:堆内存,方法区和栈,
细分的话还有什么程序计数器(唯一一个不会out of memory的)执行引擎(包括GC)
方法区是存储类的信息,常量和静态变量,线程共享的,为了和堆内存区分,称为Non-Heap(非堆)。
栈分为java虚拟机栈和本地方法栈,用于方法的执行;每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
堆内存是jvm中最大的一块由年轻代和老年代组成。
控制参数
-Xms设置堆的最小空间大小。
-Xmx设置堆的最大空间大小。
-Xmn设置年轻代的空间的大小
-XX:NewSize设置新生代最小空间大小。
-XX:MaxNewSize设置新生代最大空间大小。
-XX:PermSize设置永久代最小空间大小。
-XX:MaxPermSize设置永久代最大空间大小。
-Xss设置每个线程的堆栈大小。
JDK1.8和1.7的JVM内存结构有啥区别,有啥改进(虚拟机栈和本地方法栈合并)、为啥合并?
答:
将永久代设置为元空间,整个永久代有一个 JVM 本身设置固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,
但是比原来出现的几率会更小。你可以使用 -XX:MaxMetaspaceSize 标志设置最大元空间大小。
为啥合并;可能是因为如果 Java 虚拟机不支持 natvie 方法,并且自己也不依赖传统栈的话,可以无需支持本地方法栈。
毕竟本地方法栈就是服务natvie。
请你说说Jvm 垃圾回收细说一下?
答:
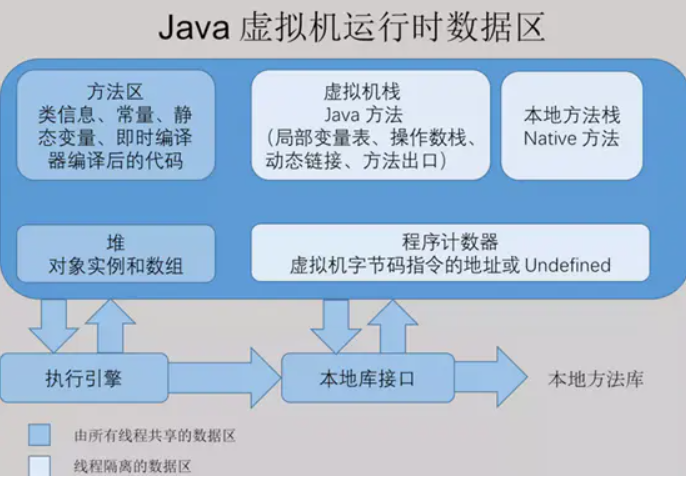
堆是存储时的单位,对于绝大多数应用来说,这块区域是 JVM 所管理的内存中最大的一块。线程共享,主要是存放对象实例和数组。
2.java容器集合
参考我之前的博客 :https://www.cnblogs.com/yangj-Blog/p/13192053.html
在ArrayList如何放不同的对象?
答:
首先明确Object下的肯定是可以存放,关系是这样的Object->collection->List->ArrayList
所以还能List<Person> personList = new ArrayList<Person>();
但是要求放几个不同的对象在一起需要如下:
第一种,通过自定义类(我们在类中封装数据)
Notice notice=new Notice(3,"好好学习,天天向上","校长",new Date()); //往列表中添加公告对象 ArrayList list=new ArrayList(); list.add(notice);
第二种,通过泛型
List<T>类是 ArrayList 类的泛型等效类。
ArrayList解决线程不安全问题?
答:
1改成线程安全的vector数组.这样当然效率很低. 或者上锁.最好的情况还是保证单一线程的修改
2 Collections.synchronizedLList(new ArrayList<><>());
3 写时复制CopyOnWriteArrayList
CopyOnWriteArrayList的解决方案如下:
读读并行不做任何处理;
写写并行通过对写操作进行上锁来解决(使用锁机制ReentrantLock来串行化所有写操作)
读写并行通过对写方式的改造来解决(所有写操作完成,替换整个array内容)
如果让你设计一个 HashMap 如何设计?
答:
这个问题我觉得可以从 HashMap 的一些关键点入手,例如 hash函数、如何处理冲突、如何扩容。
可以先说下你对 HashMap 的理解。
比如:HashMap 无非就是一个存储 <key,value> 格式的集合,用于通过 key 就能快速查找到 value。
基本原理就是将 key 经过 hash 函数进行散列得到散列值,然后通过散列值对数组取模找到对应的 index 。
所以 hash 函数很关键,不仅运算要快,还需要分布均匀,减少 hash 碰撞。
而因为输入值是无限的,而数组的大小是有限的所以肯定会有碰撞,因此可以采用拉链法来处理冲突。
为了避免恶意的 hash 攻击,当拉链超过一定长度之后可以转为红黑树结构。
当然超过一定的结点还是需要扩容的,不然碰撞就太严重了。
而普通的扩容会导致某次 put 延时较大,特别是 HashMap 存储的数据比较多的时候,所以可以考虑和 redis 那样搞两个 table 延迟移动,一次可以只移动一部分。
基本上这样答下来差不多了,HashMap 几个关键要素都包含了,接下来就看面试官怎么问了。
可能会延伸到线程安全之类的问题,反正就照着 currentHashMap 的设计答。
hashmap线程不安全原因?
答:
put的时候导致的多线程数据不一致
另外一个比较明显的线程不安全的问题是扩容时可能因为resize而引起死循环
3.java并发
四种创建方式:https://blog.csdn.net/baihualindesu/article/details/89523837
什么是共享变量?
答:
共享变量的意思就是每个线程都可以访问到的变量,共享变量比较典型的就是指类的成员变量,在类中定义了很多方法对成员变量的使用,如果是单实例,当有多个线程同时来调用这些方法,方法又没加控制,那么这些方法对成员变量的操作就会使得该成员变量的值变得不准确了。最典型的i++。现在选用开发框架一般都会选择Spring,或是类似Spring这样的东西,而代码中经常用到的依赖注入的Bean如果没做处理一般都会是单例模式。试想一下,按下面这个方式引用Service或其它类似的Bean,在UserService中又不小心用到了共享变量,同时没有处理它的共享可见性,即同步,那将会产生意想不到的结果。不光Service是单例的,Spring MVC中的Controller也是单例的,所以编写代码的时候一定要注意共享变量的问题。 所以我们要尽可能的不使用共享变量,避开它,因为处理好共享变量可见性不是一个很简单的问题。如果有非用不可的理由,请使用java.util.concurrent.atomic包下面的原子类来代替常用变量类型。比如用AtomicInteger代替int,AtomicLong代替long等等
@Autowired private UserService userService;
多线程主要就是在于通信和同步,所以共享内存出来解决这两个问题https://blog.csdn.net/suifeng3051/article/details/52611310
4.计算机网络
三次握手?
TCP作为一种可靠传输控制协议,其核心思想:既要保证数据可靠传输,又要提高传输的效率!
所以三次刚好,不多不少。
TCP的精髓在于:TCP连接的一方A,由操作系统动态随机选取一个32位的序列号,假设A的初始序列号为1000,以该序列号为原点,对自己将要发送的每个字节的数据进行编号,
1001,1002,1003…,并把自己的初始序列号ISN告诉B,让B知道什么样编号的数据是合法的,什么编号是非法的,比如编号900就是非法的,同时B还可以对A每一个编号的字节数据进行确认,
如果A收到B确认编号为2001,则意味着字节编号为1001-2000,共1000个字节已经安全到达。
所以握手握的是双方数据原点的序列号seq。
所以A客户端发送seq和同步SYN到B服务器后,B收到A然后返回ACK确认,并且加上B的seq,方便A辨别,然后A回一个ACK即可建立可靠的连接。
三次举例:
譬如发起请求遇到类似这样的情况:客户端发出去的第一个连接请求由于某些原因在网络节点中滞留了导致延迟,直到连接释放的某个时间点才到达服务端,这是一个早已失效的报文,但是此时服务端仍然认为这是客户端的建立连接请求第一次握手,于是服务端回应了客户端,第二次握手。如果只有两次握手,那么到这里,连接就建立了,但是此时客户端并没有任何数据要发送,而服务端还在傻傻的等候佳音,造成很大的资源浪费。所以需要第三次握手,只有客户端再次回应一下,就可以避免这种情况。
四次挥手?
为什么四次挥手,有了上面的基础我们知道tcp是可靠的全双功协议,第一次A到服务器B发送seq 最后的序列号和fin后,B给A ack就只是达到一个A给B发送通知,我发送完数据了,没有数据可发送了,但是问题就在于全双功,A不能发,但还没关,A可以接受B发送的数据,所以B需要向A发送一个fin,请求关闭,A再回复ack,这样b服务器收到了两次客户端A就可以关闭了,但是A还需要等待2msl(最长报文段寿命)才关闭,因为
1、为了保证客户端发送的最后一个ACK报文段能够到达服务器。因为这个ACK有可能丢失,从而导致处在LAST-ACK状态的服务器收不到对FIN-ACK的确认报文。服务器会超时重传这个FIN-ACK,接着客户端再重传一次确认,重新启动时间等待计时器。最后客户端和服务器都能正常的关闭。假设客户端不等待2MSL,而是在发送完ACK之后直接释放关闭,一但这个ACK丢失的话,服务器就无法正常的进入关闭连接状态。
2、他还可以防止已失效的报文段。客户端在发送最后一个ACK之后,再经过经过2MSL,就可以使本链接持续时间内所产生的所有报文段都从网络中消失。从保证在关闭连接后不会有还在网络中滞留的报文段去骚扰服务器。