关于MMU,以下几篇文章写得通俗易懂:
这里总结MMU三大作用:
1.虚拟地址到物理地址的转换
2.Cache缓存控制
3.内存访问权限保护
Linux内核使用了三级页表PGD、PMD和PTE,对于许多体系结构而言,PMD这一级只有一个入口。
CPU访问内存时的硬件操作顺序
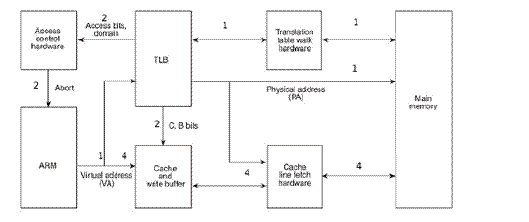
CPU访问内存时的硬件操作顺序,各步骤在图中有对应的标号:
1 CPU内核(图中的ARM)发出VA请求读数据,TLB(translation lookaside buffer)接收到该地址,那为什么是TLB先接收到该地址呢?因为TLB是MMU中的一块高速缓存(也是一种cache,是CPU内核和物理内存之间的cache),它缓存最近查找过的VA对应的页表项,如果TLB里缓存了当前VA的页表项就不必做translation table walk了,否则就去物理内存中读出页表项保存在TLB中,TLB缓存可以减少访问物理内存的次数。
2 页表项中不仅保存着物理页面的基地址,还保存着权限和是否允许cache的标志。MMU首先检查权限位,如果没有访问权限,就引发一个异常给CPU内核。然后检查是否允许cache,如果允许cache就启动cache和CPU内核互操作。
3 如果不允许cache,那直接发出PA从物理内存中读取数据到CPU内核。
4 如果允许cache,则以VA为索引到cache中查找是否缓存了要读取的数据,如果cache中已经缓存了该数据(称为cache hit)则直接返回给CPU内核,如果cache中没有缓存该数据(称为cache miss),则发出PA从物理内存中读取数据并缓存到cache中,同时返回给CPU内核。但是cache并不是只去CPU内核所需要的数据,而是把相邻的数据都去上来缓存,这称为一个cache line。ARM920T的cache line是32个字节,例如CPU内核要读取地址0x30000134~0x3000137的4个字节数据,cache会把地址0x30000120~0x3000137(对齐到32字节地址边界)的32字节都取上来缓存。
以下全文转载s3c6410_MMU地址映射过程详述
参考:
1)《ARM1176 JZF-S Technical Reference Manual》:
Chapter 3 System Control Coprocessor
Chapter 6 Memory Management Unit
2)u-boot源码:
u-boot-x.x.x/cpu/s3c64xx/start.S
u-boot-x.x.x/board/samsung/smdk6410/lowlevel_init.S
1. ARMv6 MMU简述
1)MMU由协处理器CP15控制;
2)MMU功能:地址映射(VA->PA),内存访问权限控制;
3)虚拟地址到物理地址的转换过程:Micro TLB->Main TLB->Page Table Walk
参考《ARM1176 JZF-S Technical Reference Manual》6.3节,Memory access sequence
摘录参考手册中的一段描述:

When the processor generates a memory access, the MMU: 1. Performs a lookup for a mapping for the requested virtual address and current ASID and current world, Secure or Non-secure, in the relevant Instruction or Data MicroTLB. 2. If step 1 misses then a lookup for a mapping for the requested virtual address and current ASID and current world, Secure or Non-secure, in the main TLB is performed.
If no global mapping, or mapping for the currently selected ASID, or no matching NSTID, for the virtual address can be found in the TLBs then a translation table walk is automatically performed by hardware, unless Page Table Walks are disabled by the PD0 or PD1 bits in the TTB Control register, that cause the processor to return a Section Translation fault. See Hardware page table translation on page 6-36.
If a matching TLB entry is found then the information it contains is used as follows: 1. The access permission bits and the domain are used to determine if the access is permitted. If the access is not permitted the MMU signals a memory abort, otherwise the access is enabled to proceed. Memory access control on page 6-11 describes how this is done. 2. The memory region attributes control the cache and write buffer, and determine if the access is Secure or Non-secure cached, uncached, or device, and if it is shared, as Memory region attributes on page 6-14 describes. 3. The physical address is used for any access to external or tightly coupled memory to perform Tag matching for cache entries.
2. 址映射过程详述
参考《ARM1176 JZF-S Technical Reference Manual》6.11节,Hardware page table translation
关于页表:ARMv6的MMU进行地址映射时涉及到两种页表,一级页表(first level page table)和二级页表(coarse page table)。
关于映射方式:映射方式有两种,段映射和页映射。段映射只用到一级页表,页映射用到一级页表和二级页表。
关于映射粒度:段映射的映射粒度有两种,1M section和16M supersection;页映射的映射粒度也有两种,4K small page和64K large page。
硬件在做地址转换时,如何知道当前是什么映射方式以及映射粒度是多少呢?
这些信息可以从页表的入口描述符中获得。
一级页表的入口描述符(first-level descriptor)格式如下:
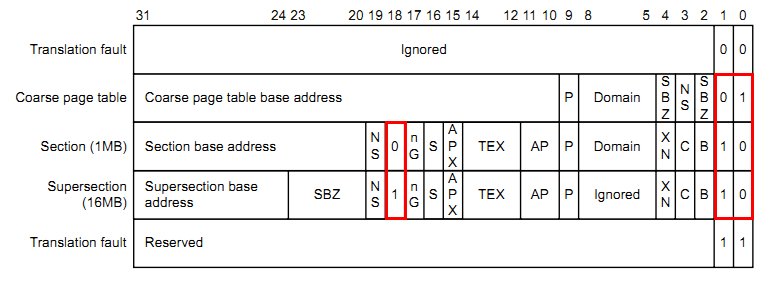
第[1:0]位决定映射方式:
[1:0]=10b时,是段映射,此时只需作一级映射,描述符的最高12或8位存放的是段基址;
[1:0]=01b时,是页映射,此时虚拟地址转换为物理地址需要经历二级映射,描述符的最高22位存放的是二级页表的物理地址;
第[18]位决定段映射的粒度:
[18]=0b时,映射粒度为1M,描述符的最高12位存放段基址;
[18]=1b时,映射粒度为16M,描述符的最高8位存放段基址;
当映射方式为页映射时,我们用到二级页表,二级页表的入口描述符(second-level descriptor)格式如下:
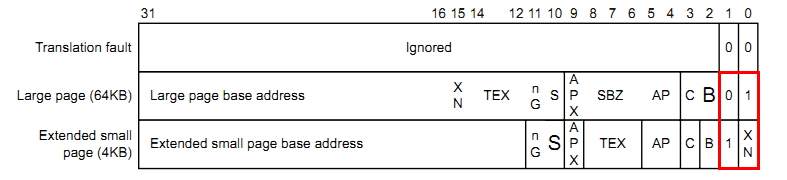
第[1:0]位决定页映射的映射粒度:
[1:0]=10b或11b时,映射粒度为4KB,描述符的最高20位为页基址;
[1:0]=01b时,映射粒度为64KB,描述符的最高16位为页基址;
下面分4种情况对地址映射过程做详细描述:
1)段映射,映射粒度为1M
2)段映射,映射粒度为16M
3)页映射,映射粒度为4K
4)页映射,映射粒度为64K
2.1段映射,映射粒度为1M
当映射方式为段映射,且映射粒度为1M时,映射图如下:
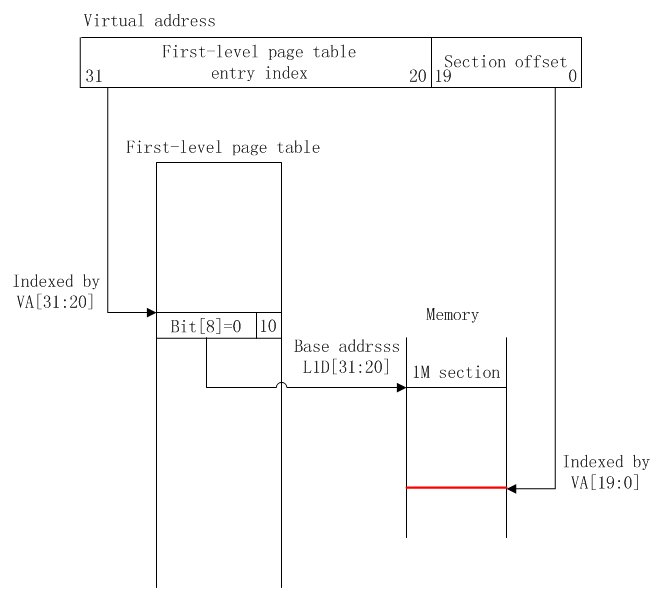
虚拟地址到物理地址的映射过程如下:
-
虚拟地址的[31:20]位存放一级页表的入口index,[19:0]位存放段偏移;
-
从TTBR(translation table base register,协处理器CP15中的一个寄存器,用于存放一级页表的基址)寄存器中获取一级页表的基址;
-
一级页表基址+ VA[31:20] = 该虚拟地址对应的页表描述符的入口地址;
-
页表描述符的[31:20]位为该虚拟地址对应的物理段基址;
-
物理段基址+ VA[19:0]段偏移= 物理地址
由映射图可知,一个虚拟地址可以索引2^12个一级页表入口,每个入口映射2^20大小的内存,故虚拟地址可以映射的最大物理内存为:2^12 * 2^20,即4G。
2.2 段映射,映射粒度为16M
当映射方式为段映射,且映射粒度为16M时,映射图如下:
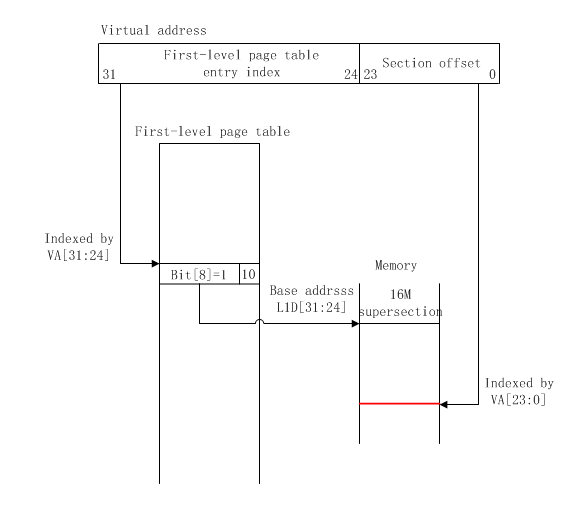
虚拟地址到物理地址的映射过程如下:
-
虚拟地址的[31:24]位存放一级页表的入口index,[23:0]位存放段偏移;
-
从TTBR(translation table base register,协处理器CP15中的一个寄存器,用于存放一级页表的基址)寄存器中获取一级页表的基址;
-
一级页表基址+ VA[31:24] = 该虚拟地址对应的页表描述符的入口地址;
-
页表描述符的[31:24]位为该虚拟地址对应的物理段基址;
-
物理段基址+ VA[23:0]段偏移= 物理地址
由映射图可知,一个虚拟地址可以索引2^8个一级页表入口,每个入口映射2^24大小的内存,故虚拟地址可以映射的最大物理内存为:2^8 * 2^24,即4G。
2.3 页映射,映射粒度为4K
当映射方式为页映射,且映射粒度为4K时,映射图如下:
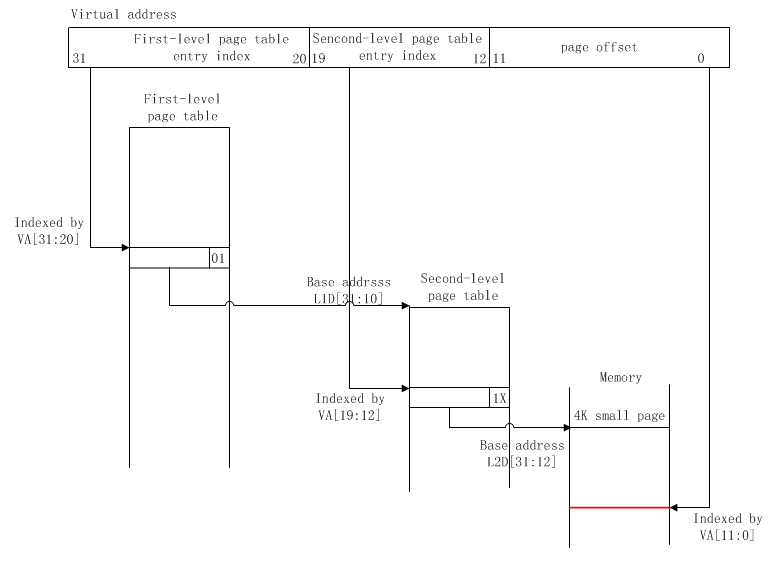
虚拟地址到物理地址的映射过程如下:
-
虚拟地址的[31:20]位存放一级页表的入口index,[19:12]位存放二级页表的入口index,[11:0]位存放页偏移;
-
从TTBR(translation table base register,协处理器CP15中的一个寄存器,用于存放一级页表的基址)寄存器中获取一级页表的基址;
-
一级页表基址+ VA[31:20] = 一级页表描述符的入口地址;
-
一级页表描述符的[31:10]位存放二级页表的基址;
-
二级页表基址+ VA[19:12] = 二级页表描述符的入口地址;
-
二级页表描述符的[31:12]位存放该虚拟地址在内存中的物理页基址;
-
物理页基址+ VA[11:0]页偏移= 物理地址
由映射图可知,一个虚拟地址可以索引2^12个一级页表入口,每个一级页表入口指向的二级页表最大可以有2^8个二级页表入口,每个二级页表入口映射2^12大小的内存,故虚拟地址可以映射的最大物理内存为:2^12 * 2^8 * 2^12 ,即4G。
2.4 页映射,映射粒度为64K
当映射方式为页映射,且映射粒度为64K时,映射图如下:
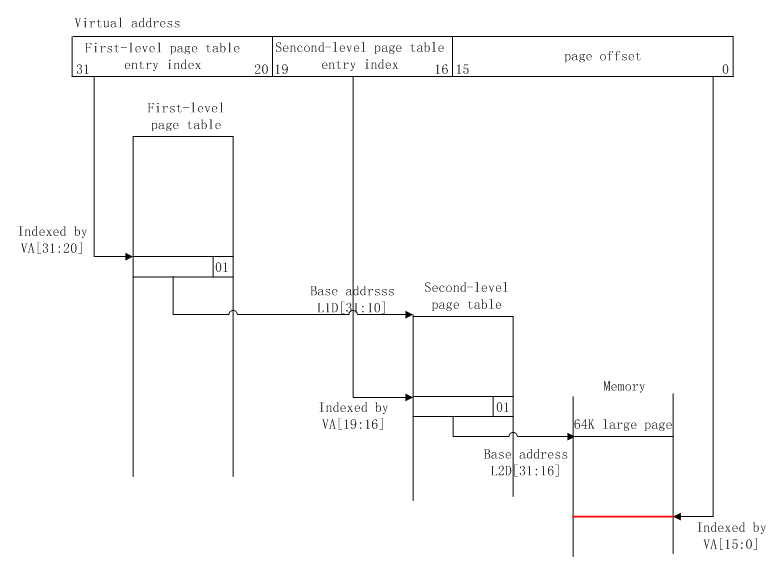
虚拟地址到物理地址的映射过程如下:
-
虚拟地址的[31:20]位存放一级页表的入口index,[19:16]位存放二级页表的入口index,[15:0]位存放页偏移;
-
从TTBR(translation table base register,协处理器CP15中的一个寄存器,用于存放一级页表的基址)寄存器中获取一级页表的基址;
-
一级页表基址+ VA[31:20] = 一级页表描述符的入口地址;
-
一级页表描述符的[31:10]位存放二级页表的基址;
-
二级页表基址+ VA[19:16] = 二级页表描述符的入口地址;
-
二级页表描述符的[31:16]位存放该虚拟地址在内存中的物理页基址;
-
物理页基址+ VA[15:0]页偏移= 物理地址
由映射图可知,一个虚拟地址可以索引2^12个一级页表入口,每个一级页表入口指向的二级页表最大可以有2^4个二级页表入口,每个二级页表入口映射2^16大小的内存,故虚拟地址可以映射的最大物理内存为:2^12 * 2^4 * 2^16 ,即4G。
2.5 地址映射总图
《ARM1176 JZF-S Technical Reference Manual》中有一张对上述四种映射情况的汇总图:
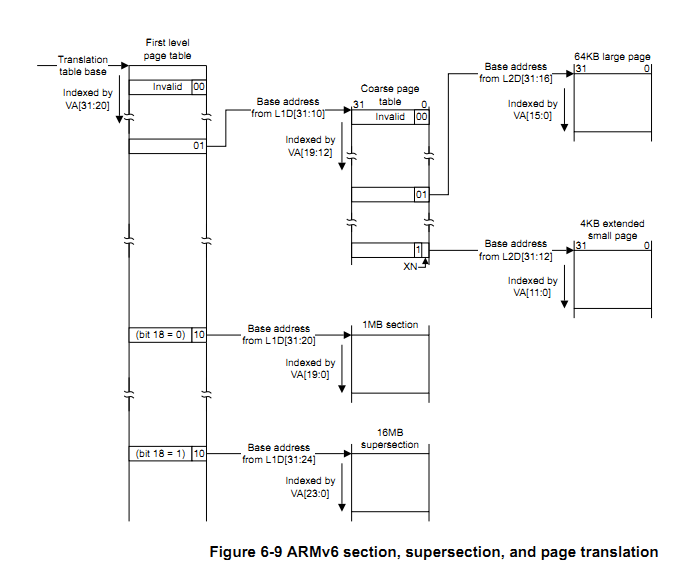
3. 关于一级页表基址
参考《ARM1176 JZF-S Technical Reference Manual》6.12 MMU descriptors
ARMv6中有两个协处理器寄存器用来存放一级页表基地址,TTBR0和TTBR1。操作系统把虚拟内存划分为内核空间和用户空间,TTBR0存放用户空间的一级页表基址,TTBR1存放内核空间的一级页表基址。
In this model, the virtual address space is divided into two regions: • 0x0 -> 1<<(32-N) that TTBR0 controls • 1<<(32-N) -> 4GB that TTBR1 controls.
N的大小由TTBCR寄存器决定。0x0 -> 1<<(32-N)为用户空间,由TTBR0控制,1<<(32-N) -> 4GB为内核空间,由TTBR1控制。
N的大小与一级页表大小的关系图如下:
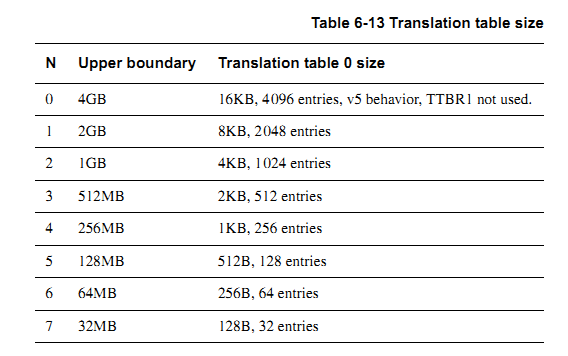
操作系统为用户空间的每个进程分配各自的页表,即每个进程的一级页表基址是不一样的,故当发生进程上下文切换时,TTBR0需要被存放当前进程的一级页表基址;TTBR1中存放的是内核空间的一级页表基址,内核空间的一级页表基址是固定的,故TTBR1中的基址值不需要改变。
4. u-boot中MMU初始化代码分析
u-boot中的MMU地址映射方式为段映射,映射粒度为1M,只用到一级页表。
start.S中的MMU初始化代码如下:
#ifdef CONFIG_ENABLE_MMU
enable_mmu:
/* enable domain access */
ldr r5, =0x0000ffff
mcr p15, 0, r5, c3, c0, 0 @ load domain access register
/* Set the TTB register */
ldr r0, _mmu_table_base
ldr r1, =CFG_PHY_UBOOT_BASE
ldr r2, =0xfff00000
bic r0, r0, r2
orr r1, r0, r1
mcr p15, 0, r1, c2, c0, 0
/* Enable the MMU */
mmu_on:
mrc p15, 0, r0, c1, c0, 0
orr r0, r0, #1 /* Set CR_M to enable MMU */
mcr p15, 0, r0, c1, c0, 0
nop
nop
nop
nop
#endif
…
…
…
#ifdef CONFIG_ENABLE_MMU
_mmu_table_base:
.word mmu_table
#endif
对协处理器的寄存器操作参考:
《ARM1176 JZF-S Technical Reference Manual》Chapter 3 System Control Coprocessor
MMU初始化过程中有一步是将页表基址(CFG_PHY_UBOOT_BASE + mmu_table)存入TTBR0中,在lowlevel_init.S中可以看到对页表的初始化:
#ifdef CONFIG_ENABLE_MMU
/*
* MMU Table for SMDK6400
*/
/* form a first-level section entry */
.macro FL_SECTION_ENTRY base,ap,d,c,b
.word (ase << 20) | (ap << 10) |
(d << 5) | (1<<4) | (c << 3) | ( << 2) | (1<<1)
.endm
.section .mmudata, "a"
.align 14
// the following alignment creates the mmu table at address 0x4000.
.globl mmu_table
mmu_table:
.set __base,0
// 1:1 mapping for debugging
.rept 0xA00
FL_SECTION_ENTRY __base,3,0,0,0
.set __base,__base+1
.endr
// access is not allowed.
.rept 0xC00 - 0xA00
.word 0x00000000
.endr
// 128MB for SDRAM 0xC0000000 -> 0x50000000
.set __base, 0x500
.rept 0xC80 - 0xC00
FL_SECTION_ENTRY __base,3,0,1,1
.set __base,__base+1
.endr
// access is not allowed.
.rept 0x1000 - 0xc80
.word 0x00000000
.endr
#endif
下面对页表的初始化代码作详细解释:
/* form a first-level section entry */
.macro FL_SECTION_ENTRY base,ap,d,c,b
.word (ase << 20) | (ap << 10) |
(d << 5) | (1<<4) | (c << 3) | ( << 2) | (1<<1)
.endm
定义一个宏FL_SECTION_ENTRY用来设置页表入口描述符,base即物理基址,ap即access permission,d即domain,c即cacheable,b即bufferable。
内存访问控制和段属性相关描述请参考:
《ARM1176 JZF-S Technical Reference Manual》6.6 Memory access control和6.7 Memory region attributes。
.section .mmudata, "a"
.align 14
// the following alignment creates the mmu table at address 0x4000.
定义一个名为mmudata的段,段属性为“a”,allowable,该段16K对齐。从u-boot.lds中可以看到,u-boot的各个段在内存中的分布依次为:.text,.rodata,.data,.got,.u_boot_cmd,.mmudata,.bss。
为什么页表是16K对齐呢?
在上一节我们讲过:有两个寄存器TTBR0和TTBR1用来存放一级页表基址,操作系统把虚拟地址空间划分为用户空间和内核空间,0x0 -> 1<<(32-N)为用户空间,由TTBR0控制,1<<(32-N) -> 4GB为内核空间,由TTBR1控制,N的大小由TTBCR寄存器决定。由于u-boot主要作用是硬件初始化和引导操作系统,所以没有必要对虚拟地址空间进行划分,即N=0,整个虚拟地址空间由TTBR0控制,TTBR0的格式如下:

N=0时,[31:14]存放页表基址,即一级页表的基址为([31:14]<<14),2^14为16K。
.set __base,0
// 1:1 mapping for debugging
.rept 0xA00
FL_SECTION_ENTRY __base,3,0,0,0
.set __base,__base+1
.endr
对虚拟地址0x0-0xA0000000作平行映射(flat mapping),即把虚拟地址0x0-0xA0000000映射到物理地址0x0-0xA0000000。
// access is not allowed.
.rept 0xC00 - 0xA00
.word 0x00000000
.endr
不对虚拟地址空间0xA0000000-0xC0000000作映射,即禁止访问虚拟地址空间0xA0000000-0xC0000000。
// 128MB for SDRAM 0xC0000000 -> 0x50000000
.set __base, 0x500
.rept 0xC80 - 0xC00
FL_SECTION_ENTRY __base,3,0,1,1
.set __base,__base+1
.endr
把虚拟地址空间0xC0000000-0xC8000000映射到物理地址空间0x50000000-0x58000000,0x50000000-0x58000000为sdram的地址空间,此时sdram有128M。
// access is not allowed.
.rept 0x1000 - 0xc80
.word 0x00000000
.endr
不对虚拟地址空间0xc8000000-0xffffffff作映射,即禁止访问虚拟地址空间0xc8000000-0xffffffff。