完整示例训练过程用到的API
1 import tensorflow as tf 2 3 dataset = tf.data.TextLineDataset(file_path) 4 # tf.string_split 5 # tf.string_to_number 6 # tf.size 7 # tf.data.Dataset.zip 8 # tf.concat 9 10 # tf.logical_and 11 # tf.logical_not 12 # tf.logical_or 13 # 14 # tf.greater 15 # tf.greater_equal 16 # tf.less 17 # tf.less_equal 18 # tf.not_equal 19 20 # dataset.map 21 # dataset.filter 22 # dataset.shuffle 23 # dataset.padded_batch 24 # dataset.make_one_shot_iterator 25 # dataset.make_initializable_iterator 26 27 # tf.TensorShape 28 # tf.nn.rnn_cell.MultiRNNCell 29 # tf.nn.rnn_cell.BasicLSTMCell 30 # tf.transpose 31 # tf.random_uniform_initializer 32 # tf.nn.embedding_lookup 33 # tf.nn.dropout 34 # tf.nn.dynamic_rnn 35 # tf.nn.sparse_softmax_cross_entropy_with_logits 36 # tf.nn.softmax_cross_entropy_with_logits 37 # tf.sequence_mask 38 39 # tf.reduce_sum 40 # tf.reduce_mean 41 # tf.reduce_max 42 # tf.reduce_min 43 # tf.reduce_any 44 # tf.reduce_all 45 # tf.reduce_prod 46 47 # tf.to_float 48 # tf.to_double 49 # tf.to_int32 50 # tf.to_int64 51 # tf.to_bfloat16 52 53 # optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0) 54 # optimizer.apply_gradients 55 56 # tf.clip_by_global_norm 57 # tf.clip_by_value 58 # tf.clip_by_norm 59 # tf.clip_by_average_norm
tf.reduce_all和tf.reduce_any
1 a = [[False, True], [True, True], [True, True]] 2 l = tf.convert_to_tensor(a) 3 s1 = tf.reduce_all(l) # Computes the "logical and" of elements across dimensions of a tensor. 4 s2 = tf.reduce_any(l) # Computes the "logical or" of elements across dimensions of a tensor. 5 6 print(l, s1, s2) 7 with tf.Session() as sess: 8 print(sess.run([l, s1, s2])) 9 10 # [array([[False, True], 11 # [ True, True], 12 # [ True, True]]), False, True]
编码过程用到的API
1 # tf.convert_to_tensor 2 # init_array = tf.TensorArray 3 # init_array.read 返回一个元素 4 # init_array.write 返回整个数组 5 # init_array.stack 一次性取出全部 6 # 7 # tf.reduce_all 8 # self.dec_cell.call 9 # tf.while_loop
这一章将介绍如何使用深度学习方法解决自然语言处理问题。
9.1 语言模型的背景知识
语言模型是自然语言处理问题中一类最基本的问题,它有着非常广泛的应用,也是理解更加复杂的自然语言处理问题的基础。
9.1.1 语言模型简介
假设一门语言中所有可能的句子服从某一个概率分布,每个句子出现的概率加起来为1,那么“语言模型”的任务就是预测每个句子在语言中出现的概率。把句子看成单词的序列,语言模型可以表示为一个计算p(w1, w2, w3,…, wm)的模型。语言模型仅仅对句子出现的概率进行建模,并不尝试去“理解”句子的内容含义。
语言模型有很多应用。很多生成自然语言文本的应用都依赖语言模型来优化输出文本的流畅性。生成的句子在语言模型中的概率越高,说明其越有可能是一个流程、自然的句子。例如在输入法中,假设输入的拼音串为“xianzaiquna”,输出可能是”西安在去哪“,也可能是”现在去哪“,这时输入法就利用语言模型比较两个输出的概率,得出”现在去哪“更有可能是用户所需要的输出。在统计机器翻译的噪声信道模型(Noise Channel Model)中,每个候选翻译的概率由一个翻译模型和一个语言模型共同决定,其中的语言模型就起到了在目标语言中挑选较为合理的句子的作用。在9.3小节将看到,神经网络机器翻译的Seq2Seq模型可以看作是一个条件语言模型(Conditional Language Model),它相当于是在给定输入的情况下对目标语言的所有句子估算概率,并选择其中概率最大的句子作为输出。
计算一个句子的概率:
首先一个句子可以被看成是一个单词序列:
S = (w1, w2, w3,…, wm),
其中m为句子的长度。那么,它的概率可以表示为
p(S) = p(w1, w2, w3,…, wm) =
p(w1)p(w2|w1)p(w3|w1, w2,) … p(wm|w1, w2, w3,…, wm-1),
p(wm|w1, w2, w3,…, wm-1)表示,已知前m-1个单词时,第m个单词为wm的条件概率。如果能对这一项建模,那么只要把每个位置的条件概率相乘,就能计算一个句子出现的概率。然而一般来说,任何一门语言的词汇量都很大,词汇的组合更是不计其数。假设一门语言的词汇量为V,如果要将p(wm|w1, w2, w3,…, wm-1)的所有参数保存一个模型里,将需要vm个参数,一般的句子长度远远超出了实际可行的范围。为了评估这些参数的取值,常见的方法由n-gram模型、决策树、最大熵模型、条件随机场、神经网络模型等。这里先以其中最简单的n-gram模型来介绍语言模型问题。
为了控制参数数量,n-gram模型做了一个有限历史假设:当前单词的出现概率仅仅与前面的n-1个单词相关,因此以上公式可以近似为
p(S) = p(w1, w2, w3,…, wm) = Πimp(wi| w1, w2, w3,…, wi-1)。
n-gram模型里的n指的是当前单词依赖它前面的单词的个数。通常n可以取1、2、3、4。n-gram模型中需要预估的参数为条件概率p(wi|wi-n+1,…, wi-1)。假设某种语言的单词表大小为V,那么n-gram模型需要估计的不同参数数量为O(vn)量级。当n越大时,模型在理论上越准确,但也越复杂,需要的计算量和训练语料数据量也就越大,因为n取>=4的情况非常少。
n-gram模型的参数一般采用最大似然估计(Maximum Likelihood Estimation, MLE)方法计算:
p(wi|wi-n+1,…, wi-1) = C(wi-n+1,…, wi-1, wi) / C(wi-n+1,…, wi-1),
其中C(X)表示单词序列X在训练语料中出现的次数。训练语料的规模越大,参数估计的结果越可靠。但即使训练数据的规模非常大时,还是有很多单词序列在训练语料中不会出现,这就会导致很多参数为0。为了避免因为乘以0而导致整个句子概率为0,使用最大似然估计方法时需要加入平滑避免参数取值为0。
9.1.2 语言模型的评价方法
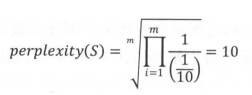
语言模型效果好坏的常用评价标准是复杂度(perplexity)。在测试集上得到的复杂度越低,说明建模效果越好。计算perplexity值的公式如下:

简单来说,perplexity值刻画的是语言模型预测一个语言样本的能力。
从上面的定义中可以看出,perplexity实际是计算每个单词得到的概率倒数的几何平均,因此perplexity可以理解为平均分支系数(average branching factor),即模型预测下一个词时的平均可选择数量。例如,考虑一个由0~9这10个数字随机组成的长度为m的序列,由于这10个数字出现的概率是随机的,所以每个数字出现的概率是1//10,因此,在任何时刻,模型都有10个等概率的候选答案可以选择,于是perplexity就是10。计算过程如下:
在语言模型的训练中,通常采用perplexity的对数表达形式:
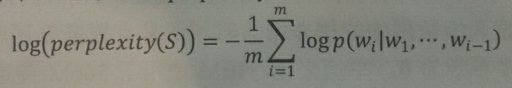
相比先乘积再求平方根的方式,采用对数形式(因为可以转为加法运算)可以加速计算,同时避免概率乘积数值过小导致浮点数向下溢出的问题。
在数学上,log perplexity可以看成真实分布与预测分布之间的交叉熵。假设x是一个离散变量,μ(x)和v(x)是两个与x相关的概率分布,那么μ和v之间交叉熵的定义是在分布μ下-log(v(x))的期望值:
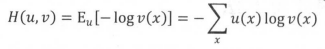
把x看作单词,μ(x)为每个位置上单词的真实分布,v(x)为模型的预测分布p(wi|wi-n+1,…, wi-1),就可以看出log perplexity和交叉熵是等价的。唯一的区别在于,由于语言的真实分布是未知的,因此在log perplexity的定义中,真实分布用测试语料中的取样代替,即认为在给定上文w1, w2, w3,…, wi-1的条件下,语料中出现单词 wi 的概率为1,出现其他单词的概率均为0。
在神经网络模型中,p(wi| w1, w2, w3,…, wi-1)分布通常是由一个softmax层产生的。这时tensorflow提供了两个方便计算交叉熵的函数:tf.nn.softmax_cross_entropy_with_logits和tf.nn.sparse_softmax_cross_entropy_with_logits。
1 import tensorflow as tf 2 3 # tf.nn.softmax_cross_entropy_with_logits与tf.nn.sparse_softmax_cross_entropy_with_logits的区别在于 4 # 前者需要预测目标(即label)以概率分布的形式给出 5 6 # 假设词汇表大小为3,语料包含有2个单词,分别为2和0 7 word_labels = tf.constant([2, 0]) 8 9 # 假设模型对两个单词预测时,产生的logit分别为[2.0, -1.0, 3.0]和[1.0, 0.0, -0.5] 10 predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]]) 11 12 # 交叉熵 13 loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=word_labels, logits=predict_logits) 14 15 # softmax_cross_entropy_with_logits需要将预测目标(即label)以概率分布的形式给出 16 word_prob_distribution = tf.constant([[0.0, 0.0, 1.0], [1.0, 0.0, 0.0]]) 17 loss2 = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_distribution, logits=predict_logits) 18 19 with tf.Session() as sess: 20 print(sess.run([loss, loss2])) 21 22 # 结果: 对应两个预测的perplexity损失 23 # [array([0.32656264, 0.4643688 ], dtype=float32), array([0.32656264, 0.4643688 ], dtype=float32)] 24 25 # 由于softmax_cross_entropy_with_logits允许提供一个概率分布,因此在使用时有更大的自由度。 26 # 例如,一种叫label smoothing的技巧是将正确数据的概率设为一个比1.0略小的值,将错误数据的概率设为比0.0略大的值,这样可以避免模型与数据过拟合,在某些时候可以提高训练效果。 27 word_prob_smooth = tf.constant([[0.01, 0.01, 0.98], [0.98, 0.01, 0.01]]) 28 loss3 = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_smooth, logits=predict_logits) 29 30 with tf.Session() as sess: 31 print(sess.run(loss3)) 32 # [0.37656265 0.48936883]
9.2 神经语言模型
上节提到,n-gram模型为了控制参数数量,需要将上下文信息控制在几个单词以内。也就是说,在预测下一个单词时,n-gram模型只能考虑前n个单词的信息,这对语言模型的能力造成了很大的限制。与之相比,循环神经网络可以将任意长度的上文信息存储在隐藏状态中。因此使用循环神经网络作为语言模型有着天然的优势。
由于隐藏状态的维度有限,它并不能真的存储’所有‘的上文信息,通常来说,距离越远的上文对下一个单词的影响越小,因此存储’所有‘信息也并非必要。研究表面,在神经语言模型中保留13个单词的上文信息大致可以取得与保留所有上文信息相同的效果。
与图像数据不同,自然语言文本数据无法直接被当做数据值提供给神经网络,需要进行预处理。
9.2.1 预处理
9.2.2 batching
9.2.3 完整示例
9.2.1 PTB数据集的预处理
PTB(Penn Treebank Dataset)文本数据集是目前语言模型学习中使用最广泛的数据集。
下载地址:http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
1 import collections 2 from operator import itemgetter 3 4 RAW_DATA = '/home/yangxl/files/ptb/ptb.train.txt' 5 VOCAB_OUTPUT = '/home/yangxl/files/ptb/ptb.vocab' 6 7 counter = collections.Counter() 8 with open(RAW_DATA, 'r') as f: 9 for line in f.readlines(): 10 for word in line.strip().split(): 11 counter[word] += 1 12 13 # 按词频顺序对单词进行排序 14 sorted_word_to_cnt = sorted(counter.items(), key=itemgetter(1), reverse=True) 15 sorted_words = [x[0] for x in sorted_word_to_cnt] 16 17 # 稍后我们需要在文本换行处加入句子结束符'<eos>',这里预先将其加入词汇表。
# 这个句子结束符应该就相当于翻译模型中的'_'吧。 18 sorted_words = ['<eos>'] + sorted_words 19 20 # 在9.3.2小节处理机器翻译数据时,除了'<eos>',还需要将'<unk>'和句子起始符'<sos>'加入词汇表,并从词汇表中删除低频慈湖。
# 在PTB数据中,因为输入数据已经将低频词汇替换为'unk',因此不需要这一步骤。
# 恰好10000个词汇。 21 # sorted_words = ['<unk>', '<sos>', '<eos>'] + sorted_words 22 # if len(sorted_words) > 10000: 23 # sorted_words = sorted_words[:10000] 24 25 with open(VOCAB_OUTPUT, 'w') as f_out: 26 for word in sorted_words: 27 f_out.write(word + ' ')
在确定了词汇表(就一个词汇表)之后,再将训练文件、测试文件等根据词汇表文件转化为单词编号。每个单词的编号就是它在词汇文件中的行号。(说是替换,其实是重新创建了一个新文件)
1 RAW_DATA = '/home/error/simple-examples/data/ptb.test.txt' 2 VACAB = '/home/error/ptb/test.vocab' 3 OUTPUT_DATA = '/home/error/ptb/ptb.test' 4 5 with codecs.open(VACAB, 'r', 'utf-8') as f: 6 vocab = [word.strip() for word in f.readlines()] 7 word_to_id = {v: k for k, v in enumerate(vocab)} 8 print(word_to_id) 9 print(word_to_id['<eos>']) 10 11 def get_id(word): 12 return word_to_id[word] if word in word_to_id else word_to_id['<unk>'] 13 14 fin = codecs.open(RAW_DATA, 'r', 'utf-8') 15 fout = codecs.open(OUTPUT_DATA, 'w', 'utf-8') 16 17 for line in fin: 18 words = line.strip().split() + ['<eos>'] # 读取出来的行,每行都要加一个换行符(为了替换为序号),在读取并strip时去掉了,所以得加上 19 out_line = ' '.join([str(get_id(w)) for w in words]) + ' ' # 这个换行符只是为了换行(上面那个是为了替换为序号) 20 fout.write(out_line) 21 22 fin.close() 23 fout.close()
上面的实例使用了文本文件来保存经过处理的数据。在实际工程中,通常使用TFRecord格式来提高读写效率。
虽然预处理原则上可以放在TF的Dataset框架中与读取文本同时进行,但在工程实践上,保存处理好的数据有几个重要的优点:第一,在调试模型的过程中,可以保证不同模型采取的预处理步骤相同;第二,减小文件体积,节省磁盘读取的时间;第三,方便对预处理步骤本身进行debug,例如,在模型训练效果不理想时,只需检查最终的数据文件就可以知道是不是预处理过程出了问题。
9.2.2 PTB数据的batching方法
在文本数据中,由于每个句子的长度不同,又无法像图像那样调整到固定维度,因为在对文本数据进行batching时需要采取一些特殊操作。最常见的方法是使用填充(padding),将同一batch内的句子长度补齐。
但是,在PTB数据集中,每个句子并非随机抽取的文本,而是在上下文之间有关联的内容。语言模型为了利用上下文信息,必须将前面句子的信息传递到后面的句子。为了解决这个问题,通常采用的是另一种batching方法。
如果模型大小没有限制,那么最理想的设计是将整个文档前后连接起来,当做一个句子来训练。但现实中这是无法实现的。例如PTB数据总共约有19万词,若将整个文档放入一个计算图,循环神经网络将展开成一个19万层的前馈网络。这样会导致计算图过大,另外序列过长可能造成训练中梯度爆炸的问题。
对此问题的解决方法是,将长序列截断为固定长度的子序列。循环神经网络在处理完一个子序列后,它最终的隐藏状态将复制到下一个序列作为初始值,这样在前向计算时,效果等同于一次性顺序地读取了整个文档;而在反向传播时,梯度则只在每个子序列内部传播。

为了利用计算时的并行能力,我们希望每一次计算可以对多个句子进行并行处理,同时又要尽量保证batch之间的上下文连续。解决方案是,先将整个文档切分成若干连续段落(可以理解为几行),再让batch中的每个位置负责其中一段(可以理解为纵向,一个batch含有所有连续段落的一小部分)。例如,如果batch大小为4,为了让batch的每个位置负责一个子序列,需要将全文平均分为4个子序列,这样每个子文档内部的所有数据仍可以被顺序处理。
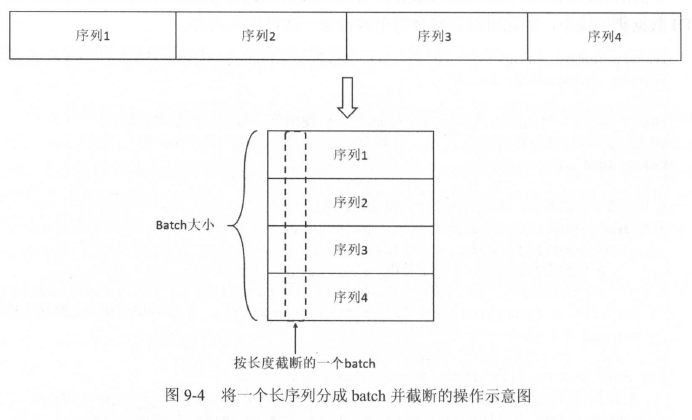
下面的代码从文本文件中读取数据,并按上面介绍的方案将数据整理成batch。由于PTB数据集比较小,因此可以直接将整个数据集一次性读入内存。
1 import numpy as np 2 3 TRAIN_DATA = '/home/yangxl/files/ptb/ptb.train' 4 TRAIN_BATCH_SIZE = 20 5 TRAIN_NUM_STEP = 35 6 7 8 # 从文件中读取数据,并返回包含单词编号的数组 9 def read_data(file_path): 10 with open(file_path, 'r') as fin: 11 # 将整个文档读进一个长字符串 12 id_string = ' '.join([line.strip() for line in fin]) 13 # 将读取的单词编号转为整数 14 id_list = [int(w) for w in id_string.split()] 15 return id_list 16 17 18 def make_batches(id_list, batch_size, num_step): 19 # batch的数量,即每一个子序列在纵向上能切分为多少小段:1327段;num_step为每一小段的大小,即一个句子的长度; 20 # 每个batch包含的单词数量为batch_size * num_step 21 num_batches = (len(id_list) - 1) // (batch_size * num_step) # 这里减1,是为了预留一个数据当作label使用 22 23 # 如9-4图所示,将数据整理成一个维度为[batch_size, num_batches * num_step]的二维数组 24 data = np.array(id_list[: num_batches * batch_size * num_step]) # 后面689个数据未用到。 25 data = np.reshape(data, [batch_size, num_batches * num_step]) # 26 # print(data.shape) # (20, 46445) 27 28 # 沿着第二个维度将数据切分成num_batches个shape为(batch_size, num_step)的batch,存入一个列表 29 data_batched = np.split(data, num_batches, axis=1) # (1327, 20, 35) 30 31 # label的处理与data一样。 32 label = np.array(id_list[1: num_batches * batch_size * num_step + 1]) 33 label = np.reshape(label, [batch_size, num_batches * num_step]) 34 label_batches = np.split(label, num_batches, axis=1) 35 36 # 返回一个长度为num_batches的数组, 37 return list(zip(data_batched, label_batches)) # (1327, 2, 20, 35) 38 39 40 def main(): 41 train_batches = make_batches(read_data(TRAIN_DATA), TRAIN_BATCH_SIZE, TRAIN_NUM_STEP) 42 43 44 if __name__ == '__main__': 45 main()
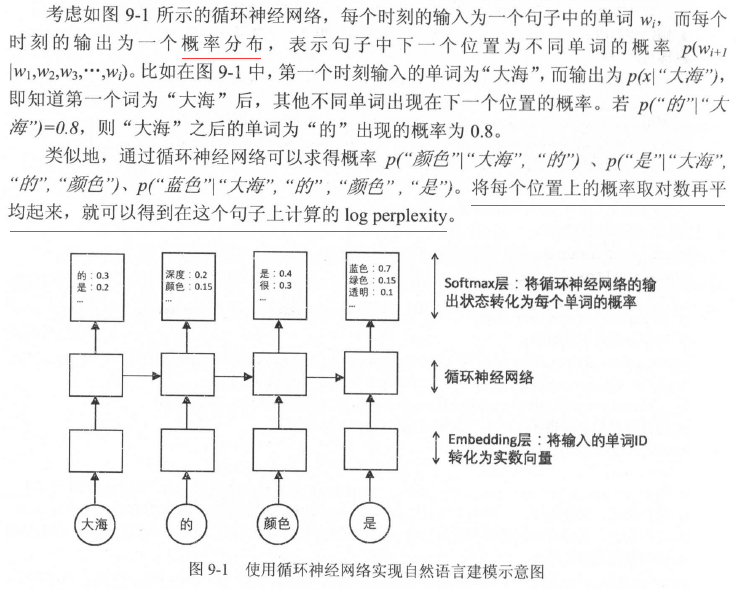
9.2.3 基于循环神经网络的神经语言模型
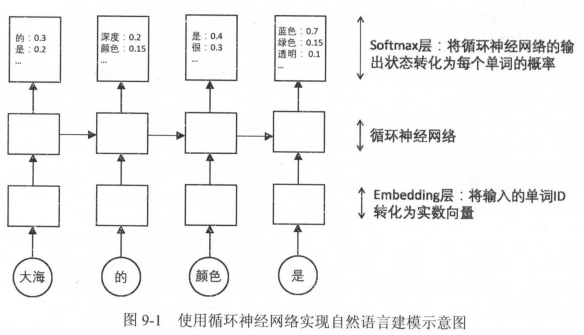
如图9-1所示,与第8章介绍的循环神经网络相比,NLP应用中主要多了两个层:词向量层(embedding)和softmax层。
词向量层
在输入层,每个单词用一个实数向量表示,这个向量被称为“词向量”。词向量可以形象地理解为将词汇表嵌入到一个固定维度的实数空间里。将单词编号转化为词向量主要有两大作用。
1. 降低输入的维度。如果不使用词向量,而直接将单词以one-hot vector的形式输入循环神经网络,那么输入的维度大小将与词汇表大小相同,通常在10000以上。而词向量的维度通常在200~1000之间,这将大大减少循环神经网络的参数数量与计算量。
2. 增加语义信息。简单的单词编号是不包含任何语义信息的。两个单词之间编号相近,并不意味着它们的含义有任何关联。而词向量层将稀疏的编号转化为稠密的向量表示,这使得词向量有可能包含更为丰富的信息。在自然语言应用中学习得到的词向量通常会将含义相似的词赋予取值相近的词向量值,使得上层的网络可以更容易地抓住相似单词之间的共性。例如,因为猫和狗都需要吃东西,因此在预测下文中出现单词“吃”的概率时,上文中出现“猫”或“狗”带来的影响可能是相似的。这样的任务训练出来的词向量中,代表“猫”和“狗”的词向量取值很可能是相似的。
假设词向量的维度是EMB_SIZE,词汇表的大小为VOCAB_SIZE,那么所有单词的词向量可以放入一个大小为VOCAB_SIZE × EME_SIZE的矩阵内。在读取词向量时,可以调用tf.nn.embedding_lookup方法。
1 import tensorflow as tf 2 3 BATCH_SIZE = 20 4 NUM_STEP = 35 5 VOCAB_SIZE = 1000 6 EMB_SIZE = 200 7 8 input_data = tf.placeholder(dtype=tf.int64, shape=[BATCH_SIZE, NUM_STEP]) # int32, int64 9 embedding = tf.get_variable('embedding', [VOCAB_SIZE, EMB_SIZE]) 10 input_embedding = tf.nn.embedding_lookup(embedding, input_data) 11 # 输出矩阵比输入矩阵多一个维度,新增维度的大小为EMB_SIZE。 12 # 在语言模型中,一般input_data的维度为batch_size * num_steps,而输出的input_embedding的维度是batch_size * num_steps * EMB_SIZE. 13 print(input_embedding) # Tensor("embedding_lookup/Identity:0", shape=(20, 35, 200), dtype=float32)
softmax层
softmax层的作用是将循环神经网络的输出转化为一个单词表中每个单词的输出概率。
为此需要两个步骤:第一,使用一个线性映射将循环神经网络的输出映射为一个维度与词汇表大小相同的向量,这一步的输出叫做logits.
1 import tensorflow as tf 2 3 BATCH_SIZE = 20 4 NUM_STEP = 35 5 HIDDEN_SIZE = 10 6 VOCAB_SIZE = 1000 7 8 # 定义线性映射用到的参数。 9 weight = tf.get_variable('weight', shape=[HIDDEN_SIZE, VOCAB_SIZE]) 10 bias = tf.get_variable('bias', [VOCAB_SIZE]) 11 # 计算线性映射。output是RNN的输出,shape=(batch_size * num_steps, HIDDEN_SIZE) 12 output = tf.placeholder(tf.float32, shape=[BATCH_SIZE * NUM_STEP, HIDDEN_SIZE]) 13 logits = tf.nn.bias_add(tf.matmul(output, weight), bias) 14 print(logits) # Tensor("BiasAdd:0", shape=(700, 1000), dtype=float32)
第二,调用softmax将logits转化为和为1的概率分布。语言模型的每一步输出都可以看作一个分类问题:在VOCAB_SIZE个可能的类别中决定这一步最可能输出的单词。
1 probs = tf.nn.softmax(logits) # 概率;probs的维度与logits的维度相同
模型训练通常并不关心概率的具体取值,而更关心最终的log perplexity,因此可以调用tf.nn.sparse_softmax_cross_entropy_with_logits方法直接从logits计算log perplexity作为损失函数:
1 # labels是一个大小为[batch_size * num_step]的一维数组,包含每个位置正确的单词编号。 2 # logits的维度为[batch_size * num_step, HIDDEN_SIZE VOCAB_SIZE](书上是错的),loss的维度与labels相同,代表每个位置上的log perplexity。 3 labels = tf.placeholder(tf.int64, shape=[BATCH_SIZE * NUM_STEP]) 4 loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits) 5 print(loss) # shape=(700,)
通过共享参数减少参数数量
softmax层和词向量层的参数数量都与词汇表大小VOCAB_SIZE成正比。VOCAB_SIZE的数值通常较大,而HIDDEN_SIZE相对较小,导致softmax和embedding在整个网络的参数数量中占很大比例。例如,VOCAB_SIZE为10000,HIDDEN_SIZE和EMB_SIZE都为512,循环神经网络采用双层LSTM,那么词向量层和Softmax层的参数数量均为10000*512=5120000,而循环神经网络本身的参数数量仅为2*4*2*512*512=4194304(LSTM有4个参数矩阵,每个参数矩阵的维度是[2*HIDDEN_SIZE, HIDDEN_SIZE],忽略偏置项, 见图8-7),少于词向量层和Softmax层的参数数量,仅占总参数数量的29%。
注意,在上面的例子中,词向量层和softmax层的参数数量是相等的,它们都为每个单词分配了长度为512的向量。如果共享词向量层和softmax层的参数,不仅能大幅减少参数数量,还能提供最终模型的效果。(能够共享参数的原因,可能是两层都是线性变换,可以使用任意参数系,那么使用相同的参数系也无妨,进一步可以说,它们是不可训练的)。下面的完整代码样例中实现了这一方法。
语言模型完整实例:
1 import numpy as np 2 import tensorflow as tf 3 4 TRAIN_DATA = '/home/yangxl/files/ptb/ptb.train' 5 EVAL_DATA = '/home/yangxl/files/ptb/ptb.valid' 6 TEST_DATA = '/home/yangxl/files/ptb/ptb.test' 7 HIDDEN_SIZE = 300 # 隐藏层大小 8 NUM_LAYERS = 2 # 深层循环神经网络中LSTM结构的层数 9 VOCAB_SIZE = 10000 # 词汇表大小 10 TRAIN_BATCH_SIZE = 20 # 训练数据batch大小 11 TRAIN_NUM_STEP = 35 # 训练数据截断长度 12 13 EVAL_BATCH_SIZE = 1 # 测试数据batch大小 14 EVAL_NUM_STEP = 1 # 测试数据截断长度 15 NUM_EPOCH = 10 # 使用训练数据的轮数 16 LSTM_KEEP_PROB = 0.9 # LSTM节点不被dropout的概率 17 EMBEDDING_KEEP_PROB = 0.9 # 词向量不被dropout的概率 18 MAX_GRAD_NORM = 5 # 用于控制梯度膨胀的梯度大小上限 19 SHARE_EMB_AND_SOFTMAX = True # 在softmax层和词向量层之间共享参数 20 21 22 # 从文件中读取数据,并返回包含单词编号的数组 23 def read_data(file_path): 24 with open(file_path, 'r') as fin: 25 # 将整个文档读进一个长字符串 26 id_string = ' '.join([line.strip() for line in fin]) 27 # 将读取的单词编号转为整数 28 id_list = [int(w) for w in id_string.split()] # 长度为929589 29 return id_list 30 31 32 def make_batches(id_list, batch_size, num_step): 33 # batch的数量,即每一个子序列在纵向上能切分为多少小段:1327段;num_step为每一小段的大小,即一个句子的长度; 34 # 每个batch包含的单词数量为batch_size * num_step 35 num_batches = (len(id_list) - 1) // (batch_size * num_step) # 这里减1,是为了预留一个数据当作label使用 36 37 # 如9-4图所示,将数据整理成一个维度为[batch_size, num_batches * num_step]的二维数组 38 data = np.array(id_list[: num_batches * batch_size * num_step]) # 后面689个数据未用到。 39 data = np.reshape(data, [batch_size, num_batches * num_step]) # 40 # print(data.shape) # (20, 46445) 41 42 # 沿着第二个维度将数据切分成num_batches个shape为(batch_size, num_step)的batch,存入一个列表 43 data_batched = np.split(data, num_batches, axis=1) # (1327, 20, 35) 44 45 # label的处理与data一样。 46 label = np.array(id_list[1: num_batches * batch_size * num_step + 1]) 47 label = np.reshape(label, [batch_size, num_batches * num_step]) 48 label_batches = np.split(label, num_batches, axis=1) 49 50 # 返回一个长度为num_batches的数组, 51 return list(zip(data_batched, label_batches)) # (1327, 2, 20, 35) 52 53 54 # 通过一个PTBModel类来描述模型,这样方便维护循环神经网络中的状态。 55 class PTBModel(object): 56 def __init__(self, is_training, batch_size, num_steps): 57 self.batch_size = batch_size 58 self.num_steps = num_steps # 在run_epoch()中计算iters时会用到 59 60 # 定义每一步的输入和预期输出,二者维度相同。 61 self.input_data = tf.placeholder(dtype=tf.int32, shape=[batch_size, num_steps]) 62 self.targets = tf.placeholder(dtype=tf.int32, shape=[batch_size, num_steps]) 63 64 # 定义以LSTM为循环体结构且使用dropout的深层循环神经网络。 65 dropout_keep_prob = LSTM_KEEP_PROB if is_training else 1.0 66 lstm_cells = [ 67 tf.nn.rnn_cell.DropoutWrapper( 68 tf.nn.rnn_cell.LSTMCell(HIDDEN_SIZE), 69 output_keep_prob=dropout_keep_prob) 70 for _ in range(NUM_LAYERS)] 71 cell = tf.nn.rnn_cell.MultiRNNCell(lstm_cells) 72 73 # 初始化最初的状态,即全零的向量。这个量只在每个epoch初始化第一个batch时使用。 74 # 和其他神经网络类似,在优化循环神经网络时,每次也会使用一个batch的训练样本。 c和h的shape都为[batch_size, HIDDEN_SIZE] 75 self.initial_state = cell.zero_state(batch_size, tf.float32) 76 77 # 定义单词的词向量矩阵 78 embedding = tf.get_variable('embedding', [VOCAB_SIZE, HIDDEN_SIZE]) 79 80 # 将输入单词转为词向量 81 inputs = tf.nn.embedding_lookup(embedding, self.input_data) 82 83 # 只在训练时使用dropout 84 if is_training: 85 # 在输入之前要dropout, 各个循环层也要dropout。不改变inputs.shape 86 inputs = tf.nn.dropout(inputs, keep_prob=EMBEDDING_KEEP_PROB) 87 88 # 定义输出列表。在这里先将不同时刻LSMT的输出收集起来,再一起提供给softmax层。 89 # outputs = [] 90 # state = self.initial_state 91 # with tf.variable_scope('RNN'): 92 # for time_step in range(num_steps): 93 # if time_step > 0: 94 # tf.get_variable_scope().reuse_variables() 95 # cell_output, state = cell(inputs[:, time_step, :], state) 96 # outputs.append(cell_output) # 长度为35,元素的shape=(20, 300) 97 # 把输出队列展开为[batch, num_steps*hidden_size]的形状,然后在reshape成[batch*num_steps, hidden_size]的形状 98 # 比直接按行拼接区别在于能够让同一片段的数据放在一起, 也是为了在计算loss时方便使用reshape得到labels 99 # output = tf.reshape(tf.concat(outputs, axis=1), [-1, HIDDEN_SIZE]) # shape=(700, 300) 100 # print('output', output) 101 # print('state', state) 102 103 # 下面这样自动计算的更牛 104 outputs, state = tf.nn.dynamic_rnn(cell, inputs, dtype=tf.float32) 105 output = tf.reshape(outputs, [-1, HIDDEN_SIZE]) 106 print('output2', output) 107 print('state2', state) 108 109 # Softmax层:将RNN在每个位置上的输出转化为各个单词的logits. 110 if SHARE_EMB_AND_SOFTMAX: # 共享参数,不会创建新的变量 111 weight = tf.transpose(embedding) 112 else: 113 weight = tf.get_variable('weight', [HIDDEN_SIZE, VOCAB_SIZE]) 114 bias = tf.get_variable('bias', [VOCAB_SIZE]) 115 logits = tf.matmul(output, weight) + bias # output、weight的先后问题?? 116 117 # 定义交叉熵损失函数和平均损失 118 # loss = tf.losses.mean_squared_error(labels=tf.reshape(self.targets, [-1]), predictions=logits) 119 loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.reshape(self.targets, [-1]), logits=logits) 120 self.cost = tf.reduce_sum(loss) / batch_size 121 self.final_state = state # 保存了每次batch的状态 122 123 if not is_training: 124 return 125 126 trainable_variables = tf.trainable_variables() 127 # print('train', trainable_variables) 128 # [<tf.Variable 'language_model/embedding:0' shape=(10000, 300) dtype=float32_ref>, 129 # <tf.Variable 'language_model/RNN/multi_rnn_cell/cell_0/lstm_cell/kernel:0' shape=(600, 1200) dtype=float32_ref>, 每层有4个维度为[2n, n]的参数矩阵,所以kernel.shape=[600, 1200] 130 # <tf.Variable 'language_model/RNN/multi_rnn_cell/cell_0/lstm_cell/bias:0' shape=(1200,) dtype=float32_ref>, 131 # <tf.Variable 'language_model/RNN/multi_rnn_cell/cell_1/lstm_cell/kernel:0' shape=(600, 1200) dtype=float32_ref>, 132 # <tf.Variable 'language_model/RNN/multi_rnn_cell/cell_1/lstm_cell/bias:0' shape=(1200,) dtype=float32_ref>, 133 # <tf.Variable 'language_model/bias:0' shape=(10000,) dtype=float32_ref>] 134 # 控制梯度大小,定义优化方法和训练步骤 135 grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, trainable_variables), MAX_GRAD_NORM) 136 optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0) 137 self.train_op = optimizer.apply_gradients(zip(grads, trainable_variables)) 138 139 140 def run_epoch(session, model, batches, train_op, output_log, step): 141 # train_op作为一个专门的参数而不是使用model.train_op,是为了区分训练过程和测试/验证过程 142 143 # 计算平均perplexity的辅助变量 144 total_costs = 0.0 145 iters = 0 146 state = session.run(model.initial_state) 147 # 训练一个epoch 148 for x, y in batches: 149 # 在当前batch上运行train_op并计算损失值。交叉熵损失函数计算的就是下一个单词为给定单词的概率 150 cost, state, _ = session.run( 151 # 最需要注意的是state,每个epoch都要重新提供初始化状态。 152 [model.cost, model.final_state, train_op], feed_dict={model.input_data: x, model.targets: y, model.initial_state: state} # feed_dict里面的值不只是placeholder! 153 ) 154 total_costs += cost 155 iters += model.num_steps 156 157 # 只有在训练时输出日志 158 if output_log and step % 100 == 0: 159 print('After %d steps, perplexity is %.3f' % (step, np.exp(total_costs / iters))) 160 161 step += 1 162 163 return step, np.exp(total_costs / iters) 164 165 166 def main(): 167 # 定义初始化函数 168 initializer = tf.random_normal_initializer(-0.05, 0.05) 169 170 # 定义训练用的循环神经网络模型 171 with tf.variable_scope('language_model', reuse=None, initializer=initializer): 172 train_model = PTBModel(True, TRAIN_BATCH_SIZE, TRAIN_NUM_STEP) 173 174 # 定义测试用的循环神经网络模型,它与train_model共用参数,但没有dropout 175 with tf.variable_scope('language_model', reuse=True, initializer=initializer): 176 eval_model = PTBModel(False, EVAL_BATCH_SIZE, EVAL_NUM_STEP) 177 178 # 训练模型 179 with tf.Session() as session: 180 tf.global_variables_initializer().run() 181 train_batches = make_batches(read_data(TRAIN_DATA), TRAIN_BATCH_SIZE, TRAIN_NUM_STEP) 182 eval_batches = make_batches(read_data(EVAL_DATA), EVAL_BATCH_SIZE, EVAL_NUM_STEP) 183 test_batches = make_batches(read_data(TEST_DATA), EVAL_BATCH_SIZE, EVAL_NUM_STEP) 184 185 step = 0 186 187 for i in range(NUM_EPOCH): 188 print('In iteration: %d' % (i+1)) 189 step, train_pplx = run_epoch(session, train_model, train_batches, train_model.train_op, True, step) 190 print('Epoch: %d Train PerPlexity: %.3f' % (i+1, train_pplx)) 191 192 _, eval_pplx = run_epoch(session, eval_model, eval_batches, tf.no_op(), False, 0) 193 print('Epoch: %d Eval Perplexity: %.3f' % (i+1, eval_pplx)) 194 195 _, test_pplx = run_epoch(session, eval_model, test_batches, tf.no_op(), False, 0) 196 print('Test Perplexity: %.3f' % test_pplx) 197 198 199 if __name__ == '__main__': 200 main()

也就吃个饭的时间(一个多小时),TIME+都到478了,看来还真不是常规的时间。
top命令的TIME/TIME+是指的进程所使用的CPU时间,不是进程启动到现在的时间,因此,如果一个进程使用的cpu很少,那即使这个进程已经存在N长时间,TIME/TIME+也是很小的数值。此外,如果你的系统有多个CPU,或者是多核CPU的话,那么,进程占用多个cpu的时间是累加的,上边的示例,一个多小时对应478,就说明机器是8核的。
通过调整LSTM隐藏层的节点个数和大小以及训练迭代的轮数还可以将perplexity值降到最低。
非常多的自然语言处理应用的技术都是基于语言模型。
9.3 神经网络机器翻译
最基础的机器翻译算法——Seq2Seq模型。
9.3.1 机器翻译背景与Seq2Seq模型介绍
Seq2Seq模型的基本思想:使用一个循环神经网络读取输入句子,将整个句子的信息压缩到一个固定维度的编码中,再使用另一个循环神经网络读取这个编码,将其“解压”为目标语言的一个句子。这两个循环神经网络分别成为编码器(Encoder)和解码器(Decoder),这个模型也称为encoder-decoder模型。
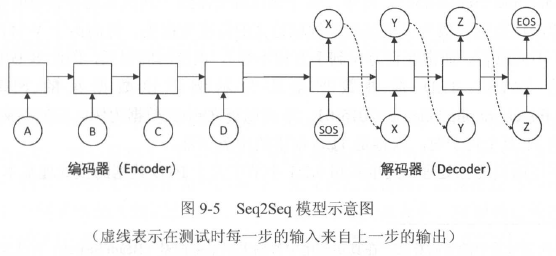
解码器部分的结构与语言模型几乎完全相同:输入为单词的词向量,输出为softmax层产生的单词概率,损失函数为log perplexity。解码器可以理解为一个以输入编码为前提的语言模型。语言模型中使用的一些技巧,如共享softmax层和词向量的参数,都可以直接应用到Seq2Seq模型的解码器中。
编码器分布则更为简单。它与解码器一样拥有词向量层和循环神经网络,但是由于编码阶段并未输出,因此不需要softmax层。
在训练过程中,编码器顺序读入每个单词的词向量,然后将最终的隐藏状态复制到解码器作为初始状态。解码器的第一个输入是一个特殊的<sos>字符(start-of-sentence),每一步预测的单词是训练数据的目标句子,预测序列的最后一个单词是与语言模型相同的'<eos>'字符(end-of-sentence)。
在机器翻译应用中,真实应用场景中的测试步骤与语言模型的测试步骤有所不同。语言模型中测试的标准是给定目标句子上的perplexity。而机器翻译的测试方法是,让解码器在没有“正确答案”的情况下自主生成一个翻译句子,然后采用人工或自动的方法对翻译句子的质量进行评测。
在解码过程中,每一步预测的单词中概率最大的单词被选为这一步的输出,并复制到下一步的输入中(图9-3中用虚线表示)。这里描述的是最简单的贪心算法,在真实应用中普遍采用集束搜索(Beam Search)方法来获得最好的翻译效果。
9.3.2 机器翻译文本数据的预处理
机器翻译领域最重要的公开数据集是WMT数据集(Workshop on Statistical Machine Translation),下载地址:http://data.statmt.org/wmt17/translation-task/,该会议从2016年起改为Conference on Machine Translation。每年,该会议就会组织一次机器翻译领域的竞赛,其提供的训练和测试数据也成为了机器翻译领域论文的标准数据集。然而由于WMT数据集较大,训练时间较长,因此本节采用一个较小的IWLST TED演讲数据集作为示例,下载地址:https://wit3.fbk.eu/mt.php?release=2015-01

点击'0.51'下载的就是了。
它的英文-中文训练数据包含21万个句子对,内容是TED演讲的中英字幕。
对于平行语料的预处理,其步骤和9.2.1小节中关于PTB数据的预处理基本一样。首先,需要统计语料中出现的单词,为每个单词分配一个ID,将词汇表存入一个vocab文件,然后将文本转化为用单词编号的形式来表示。
与前面不同的地方主要在于,下载的文本没有经过预处理,尤其没有经过切词。例如,由于每个英文单词和标点符号之间紧密相连,导致不能像处理PTB数据那样直接用空格对单词进行切割。为此需要用一些独立的工具来进行切词操作。
最常用的切词工具是moses:(书上的地址不对)
1 git clone https://github.com/moses-smt/mosesdecoder.git
切词操作:
1 # 英文切词 2 error@error-F14CU27:~/moses/mosesdecoder/scripts/tokenizer$ perl ./tokenizer.perl -no-escape -l en < /home/error/en-zh/train.tags.en-zh.en > /home/error/codes/train.tags.en-zh.en 3 Tokenizer Version 1.1 4 Language: en 5 Number of threads: 1 6 7 # 中文切词 8 # 先把汉字和汉字切分开 9 error@error-F14CU27:~/en-zh$ sed 's/ //g; s/B/ /g' ./train.tags.en-zh.zh > /home/error/codes/train.tags.en-zh.zh 10 11 # 切分汉字和标点符号 12 error@error-F14CU27:~/moses/mosesdecoder/scripts/tokenizer$ perl ./tokenizer.perl -no-escape -l en < /home/error/codes/train.tags.en-zh.zh > /home/error/codes/train.tags.en-zh.zh2 13 Tokenizer Version 1.1 14 Language: en 15 Number of threads: 1
$ cat train.tags.en-zh.en | grep -v '<url>'| grep -v '<keywords>' | grep -v '<speaker>' | grep -v '<talkid>' | grep -v '<translator' | grep -v '<reviewer' > train.en
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/ //g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/B/ /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/,/ , /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/。 / 。/g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/!/ !/g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/!/ !/g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/,/ , /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/./ . /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/?/ ? /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/?/ ? /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/《/ 《 /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/》/ 》 /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/"/ " /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/— —/ —— /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/•/ • /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/、/ 、 /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/·/ · /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/:/ : /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/…/ … /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/【/ 【 /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/】/ 】 /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/(/ ( /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/)/ ) /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/-/ - /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/- -/--/g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/- -/--/g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/— —/ —— /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/- -/ - - /g' train.zh.bk yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/- -/--/g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/-/ - /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/- -/--/g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/(/ ( /g' train.zh.bk
yangxl@yangxl-Lenovo-ideapad-330C-15IKB:~/files/trans$ sed -i 's/)/ ) /g' train.zh.bk
完成切词后,再使用之前处理PTB数据的方法,分别生成英文文本和中文文本词汇文件,并将文本转化为单词编号。生成词汇文件时,需要注意将<sos>、<eos>、<unk>这3个词手动加入到词汇表中,并且要限制词汇表大小,将词频过低的次替换为<unk>。假定英文词汇表大小为10000,中文词汇表大小为4000。
在PTB 数据中,由于句子之间有上下文关联,因此可以直接将连续的句子连接起来称为一个大的段落。而在机器翻译的训练样本中,每个句子对通常是作为独立的数据来训练的。由于每个句子的长短不一致,因此在将这些句子放入同一个batch 时,需要将较短的句子补齐到与同batch内最长句子相同的长度。用于填充长度而填入的位置叫作填充(padding)。在TensorFlow中,tf.data.Dataset.padded_ batch函数提供了这一功能。
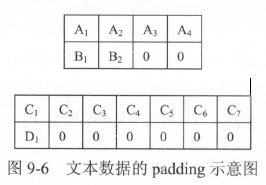
循环神经网络在读取数据时会将填充位置的内容与其他内容一样纳入计算,因此为了不让填充影响训练,有两方面需要注意:
第一,循环神经网络在读取填充时,应当跳过这一位置的计算。以编码器为例,如果编码器在读取填充时,像正常输入一样处理填充输入,那么在读取“B1B200”之后产生的最后一位隐藏状态就和读取“B1B2”之后的隐藏状态不同,会产生错误的结果。
TensorFlow提供了tf.nn.dynamic_rnn方法来实现这一功能。dynamic_rnn对每一个batch的数据读取两个输入:输入数据的内容(维度为[batch_size, time])和输入数据的长度(维度为[time])。对于输入batch里的每一条数据,在读取了相应长度的内容后,dynamic_rnn就跳过后面的输入,直接把前一步的计算结果复制到后面的时刻。这样可以保证padding是否存在不影响模型效果。
另外值得注意的是,使用dyanmic_rnn时每个batch的最大序列长度不需要相同。例如,在上面的例子中,第一个batch的维度是2×4,而第二个batch的维度是2×7。在训练中dynamic_rnn会根据每个batch的最大长度动态展开到需要的层数,这就是它被称为“dynamic”的原因。
第二,在设计损失函数时需要特别将填充位置的损失的权重设置为0,这样在填充位置产生的预测不会影响梯度的计算。
下面的代码使用tf.data.Dataset.padded_batch来进行填充和batching,并记录每个句子的序列长度以用作dynamic_rnn的输入。与前面PTB的例子不同,这里没有将所有数据读入内存,而是使用Dataset从磁盘动态读取数据。
数据处理的示例见完整代码的前面部分。
sequence_mask方法:
1 g = tf.sequence_mask([8, 9, 7, 5, 8], maxlen=10, dtype=tf.float32) 2 3 with tf.Session() as sess: 4 print(sess.run(g)) 5 6 # 结果: 7 # [[1. 1. 1. 1. 1. 1. 1. 1. 0. 0.] 8 # [1. 1. 1. 1. 1. 1. 1. 1. 1. 0.] 9 # [1. 1. 1. 1. 1. 1. 1. 0. 0. 0.] 10 # [1. 1. 1. 1. 1. 0. 0. 0. 0. 0.] 11 # [1. 1. 1. 1. 1. 1. 1. 1. 0. 0.]]
seq2seq模型完整实例:
1 #!coding:utf8 2 3 import tensorflow as tf 4 import time 5 6 MAX_LEN = 50 # 限定句子的最大单词数量 7 SOS_ID = 1 # 目标语言词汇表中<sos>的ID 8 9 SRC_TRAIN_DATA = 'D:\files\tf\train.txt.en.num' 10 TRG_TRAIN_DATA = 'D:\files\tf\train.txt.zh2.num' 11 CHECKPOINT_PATH = 'D:\files\tf\seq222seq_ckpt' 12 HIDDEN_SIZE = 1024 # 隐藏层大小 13 NUM_LAYERS = 2 # 层数 14 SRC_VOCAB_SIZE = 10000 # 源语言词汇表大小 15 TRG_VOCAB_SIZE = 4000 # 目标语言词汇表大小 16 BATCH_SIZE = 100 17 NUM_EPOCH = 1 18 KEEP_PROB = 0.8 # 节点不被dropout的概率 19 MAX_GRAD_NORM = 5 # 用于控制梯度膨胀的梯度大小上限 20 SHARE_EMB_AND_SOFTMAX = True 21 22 23 # 使用Dataset从一个文件中读取一个语言的数据。 24 # 数据格式为每行一句话,单词已经转化为单词编号 25 # 行数据,当前行单词个数 26 def MakeDataset(file_path): 27 dataset = tf.data.TextLineDataset(file_path) # 取出来的是一行,bytes类型 28 # b'95 13 1590 0 4 11 90 4870 0 4 2' 29 30 # 根据空格将单词编号切分开并放入一个一维向量 31 dataset = dataset.map(lambda string: tf.string_split([string]).values) # '[]'不能丢 32 # [b'95' b'13' b'1590' b'0' b'4' b'11' b'90' b'4870' b'0' b'4' b'2'] 33 34 # 将字符串形式的单词编号转化为整数 35 dataset = dataset.map(lambda string: tf.string_to_number(string, tf.int32)) 36 # [ 95 13 1590 0 4 11 90 4870 0 4 2] 37 38 # 统计每个句子的单词数量,并与句子内容一起放入Dataset中 39 dataset = dataset.map(lambda x: (x, tf.size(x))) # ([ 95 13 1590 0 4 11 90 4870 0 4 2], 11) 40 return dataset 41 42 43 # 从源语言文件src_path和目标语言文件trg_path中分别读取数据,并进行填充和batching操作 44 def MakeSrcTrgDataset(src_path, trg_path, batch_size): 45 # 首先分别读取源语言数据和目标语言数据 46 src_data = MakeDataset(src_path) # ([ 95 13 1590 0 4 11 90 4870 0 4 2], 11) 47 trg_data = MakeDataset(trg_path) # ([ 40, 5545, 610, 118, 10, 261, 7, 171, 4827, 507, 4, 5, 7, 40, 5545, 610, 6, 2], 18) 48 49 # 通过zip操作将两个Dataset合并为一个Dataset。 50 dataset = tf.data.Dataset.zip((src_data, trg_data)) 51 52 # 删除内容为空的句子和长度过长的句子 53 def FilterLength(src_tuple, trg_tuple): 54 ((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple) 55 src_len_ok = tf.logical_and(tf.greater(src_len, 1), tf.less_equal(src_len, MAX_LEN)) # 句子长度大于1且不大于50 56 trg_len_ok = tf.logical_and(tf.greater(trg_len, 1), tf.less_equal(trg_len, MAX_LEN)) 57 return tf.logical_and(src_len_ok, trg_len_ok) 58 dataset = dataset.filter(FilterLength) # 作为过滤器的函数必须能够返回布尔值。 59 60 # 解码器需要两种格式的目标句子。 61 # 1. 解码器的输入(trg_input), 形式如同'<sos> X Y Z' 62 # 2. 解码器的目标输出(trg_label), 形式如同'X Y Z <eos>' 63 # 上面从目标文件中读到的目标句子是'X Y Z <eos>'的形式,需要从中生成'<sos> X Y Z'形式并加入到dataset中。 64 def MakeTrgInput(src_tuple, trg_tuple): 65 ((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple) # [ 40, 5545, 610, 118, 10, 261, 7, 171, 4827, 507, 4, 5, 7, 40, 5545, 610, 6, 2] 66 trg_input = tf.concat([[SOS_ID], trg_label[:-1]], axis=0) 67 return ((src_input, src_len), (trg_input, trg_label, trg_len)) 68 dataset = dataset.map(MakeTrgInput) 69 70 # 随机打乱循环数据 71 dataset = dataset.shuffle(10000) 72 73 # 规定填充后输出的数据维度 74 padded_shapes = ( 75 (tf.TensorShape([None]), # 源句子是长度未知的向量 76 tf.TensorShape([])), # 源句子长度是单个数字 77 78 (tf.TensorShape([None]), # 目标句子(解码器输入)是长度未知的向量 79 tf.TensorShape([None]), # 目标句子(解码器目标输出)是长度未知的向量 80 tf.TensorShape([])) # 目标句子长度是单个数字 81 ) 82 83 # batching操作, 84 # Defaults are `0` for numeric types and the empty string for string types. 85 batched_dataset = dataset.padded_batch(batch_size, padded_shapes) # src.shape=(batch_size, max_length) 86 return batched_dataset 87 88 89 # 定义模型 90 class NMTModel(object): 91 def __init__(self): 92 self.enc_cell = tf.nn.rnn_cell.MultiRNNCell( 93 [tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)] 94 ) 95 self.dec_cell = tf.nn.rnn_cell.MultiRNNCell( 96 [tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)] 97 ) 98 99 # 为源语言和目标语言分别定义词向量 100 # 注意VOCAB_SIZE是词汇表大小,不是文本大小。 101 # 初始化的变量取什么值都无所谓吧 102 self.src_embedding = tf.get_variable('src_emb', [SRC_VOCAB_SIZE, HIDDEN_SIZE]) 103 self.trg_embedding = tf.get_variable('trg_emb', [TRG_VOCAB_SIZE, HIDDEN_SIZE]) 104 105 # softmax层的变量都是trg的,因为是输出层进行分类 106 if SHARE_EMB_AND_SOFTMAX: 107 self.softmax_weight = tf.transpose(self.trg_embedding) 108 else: 109 self.softmax_weight = tf.get_variable('weight', [HIDDEN_SIZE, TRG_VOCAB_SIZE]) 110 self.softmax_bias = tf.get_variable('softmax_bias', [TRG_VOCAB_SIZE]) 111 112 def forward(self, src_input, src_size, trg_input, trg_label, trg_size): 113 # src_input.shape=(5, 17) src_size=[10 9 13 11 17] # (5, 17)是因为没有去掉文件头部几行,看了不下一遍了。 114 # trg_label.shape=(5, 30) trg_size=[30 21 26 18 21] 115 batch_size = tf.shape(src_input)[0] 116 117 src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input) # (5, 17, 1024) 118 trg_emb = tf.nn.embedding_lookup(self.trg_embedding, trg_input) # (5, 30, 1024) # 解码器的输入trg_input 119 120 # 在词向量上进行dropout,dropout不会改变shape。 121 src_emb = tf.nn.dropout(src_emb, KEEP_PROB) # (5, 17, 1024) 122 trg_emb = tf.nn.dropout(trg_emb, KEEP_PROB) # (5, 30, 1024) 123 124 # 使用dynamic_rnn构造编码器 125 # 不改变shape 126 with tf.variable_scope('encoder'): 127 # 因为编码器是一个双层LSTM结构,因此enc_state是一个包含两个LSTMStateTuple类的tuple,每个类对应编码器中一层的状态。 128 # state_c和state_h的shape都为[batch_size, HIDDEN_SIZE],即(5, 1024) 129 # enc_outputs是顶层LSTM在每一步的输出,维度为[batch_size, max_time, HIDDEN_SIZE],同输入(5, 17, 1024) 130 # 后两个参数的作用?? 131 enc_outputs, enc_state = tf.nn.dynamic_rnn( 132 self.enc_cell, src_emb, src_size, dtype=tf.float32 133 ) 134 135 # 构造解码器 136 with tf.variable_scope('decoder'): 137 # dec_outputs.shape=(5, 30, 1024), 同输入 138 # 输出隐藏状态,4个都是(5, 1024) 139 # 解码器的初始状态为编码器的输出状态 140 dec_outputs, _ = tf.nn.dynamic_rnn( 141 self.dec_cell, trg_emb, trg_size, initial_state=enc_state # 编码器的最终状态,作为解码器的初始状态。 142 ) 143 144 # 计算解码器每一步的log perplexity 145 output = tf.reshape(dec_outputs, [-1, HIDDEN_SIZE]) # shape=(150, 1024) 146 147 # softmax层输出 148 logits = tf.matmul(output, self.softmax_weight) + self.softmax_bias # shape=(150, 4000) 149 loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.reshape(trg_label, [-1]), logits=logits) # shape=(150,) 一个batch(150个单词编号)的总损失。 150 151 # 在计算平均损失时,需要将填充位置的权重设置为0,以避免无效位置的预测干扰模型的训练 152 label_weight = tf.sequence_mask( 153 trg_size, maxlen=tf.shape(trg_label)[1], dtype=tf.float32 154 ) # 假如trg_size=[30 21 26 18 21], maxlen=30, 那么结果的第二个元素为[21个1.0,(30-21)个0.0] 155 156 label_weight = tf.reshape(label_weight, [-1]) # shape=(150,) 157 158 cost = tf.reduce_sum(loss * label_weight) # 一个batch的损失,1035.8269 # 把填充位置的损失过滤掉了 159 cost_per_token = cost / tf.reduce_sum(label_weight) # 一个单词编号对应的损失,8.704428 # 也是把填充位置排除了 160 161 # 定义反向传播 162 trainable_variables = tf.trainable_variables() 163 164 # 控制梯度大小,定义优化方法和训练步骤 165 grads = tf.gradients(cost / tf.to_float(batch_size), trainable_variables) # 习惯上,一个batch有batch_size个数据,除以batch_size表示一个`数据`(一个句子)的损失 166 grads, _ = tf.clip_by_global_norm(grads, MAX_GRAD_NORM) 167 optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0) 168 train_op = optimizer.apply_gradients(zip(grads, trainable_variables)) 169 return cost_per_token, train_op 170 # return src_input, src_size, src_emb, dropout_src_emb, enc_outputs, trg_input, trg_label, trg_size, trg_emb, dropout_trg_emb, dec_outputs, output, logits, loss, cost_per_token, train_op 171 172 173 def run_epoch(sess, cost_op, train_op, saver, step): 174 # 重复训练步骤直至遍历完dataset中的所有数据 175 # 训练之前不知道需要训练多少轮 176 while True: 177 try: 178 cost, _ = sess.run([cost_op, train_op]) 179 if step % 10 == 0: 180 print('After %s steps, per token cost is %.3f' % (step, cost)) 181 # 每200步保存一个checkpoint 182 if step % 200 == 0: 183 saver.save(sess, CHECKPOINT_PATH, global_step=step) 184 step += 1 185 except tf.errors.OutOfRangeError: 186 break 187 return step 188 189 190 def main(): 191 initializer = tf.random_uniform_initializer(-0.05, 0.05) 192 193 # 定义训练用的循环神经网络模型 194 with tf.variable_scope('nmt_model', reuse=None, initializer=initializer): 195 train_model = NMTModel() 196 197 # 定义输入数据 198 data = MakeSrcTrgDataset(SRC_TRAIN_DATA, TRG_TRAIN_DATA, BATCH_SIZE) 199 iter = data.make_initializable_iterator() 200 (src, src_size), (trg_input, trg_label, trg_size) = iter.get_next() # trg_input的shape=[batch_size, max_length] 201 202 cost_op, train_op = train_model.forward(src, src_size, trg_input, trg_label, trg_size) 203 # src_input, src_size, src_emb, dropout_src_emb, enc_outputs, trg_input, trg_label, trg_size, trg_emb, dropout_trg_emb, dec_outputs, output, logits, loss, cost_per_token, train_op = train_model.forward(None, src, src_size, trg_input, trg_label, trg_size) 204 205 # 训练模型 206 saver = tf.train.Saver() 207 step = 0 208 with tf.Session() as sess: 209 tf.global_variables_initializer().run() 210 211 # src_input, src_size, src_emb, dropout_src_emb, enc_outputs, trg_input, trg_label, trg_size, trg_emb, dropout_trg_emb, dec_outputs, output, logits, loss, cost_per_token, train_op = sess.run([src_input, src_size, src_emb, dropout_src_emb, enc_outputs, trg_input, trg_label, trg_size, trg_emb, dropout_trg_emb, dec_outputs, output, logits, loss, cost_per_token, train_op]) 212 # print(src_input.shape, src_size, src_emb.shape, dropout_src_emb.shape, enc_outputs.shape, trg_input.shape, trg_label.shape, trg_size, trg_emb.shape, dropout_trg_emb.shape, dec_outputs.shape, output.shape, logits.shape, loss.shape, cost_per_token, train_op) 213 # return 214 215 for i in range(NUM_EPOCH): 216 print('In iterator: %d' % (i+1)) 217 # iterator为何放在循环中,遍历第二遍时还要重新初始化?? 218 sess.run(iter.initializer) # 取值之前一定不要忘记迭代器初始化 219 step = run_epoch(sess, cost_op, train_op, saver, step) 220 print('In interator %d is end, step is %d' % (i+1, step)) 221 222 if __name__ == '__main__': 223 print(int(time.time())) 224 main() 225 print(int(time.time()))
在解码的程序中,解码器的实现与训练时有很大不同。因为训练时解码器可以从输入中读取完整的目标训练句子,因此可以用dynamic_rnn简单地展开成前馈网络。而在解码过程中,模型只能看到输入句子,却不能看到目标句子。解码器的第一步读取<sos>符,预测目标句子的第一个单词,然后需要将这个预测的单词复制到第二步作为输入,再预测第二个单词,知道预测的单词为<eos>为止。这个过程需要使用一个循环结构来实现。tf.while_loop。
翻译过程:
1 #!coding:utf8 2 3 import tensorflow as tf 4 5 CHECKPOINT_PATH = '/home/yangxl/codes/seq2seq_ckpt-400' 6 7 # 必须要与训练模型的参数一致 8 HIDDEN_SIZE = 1024 # 隐藏层大小 9 NUM_LAYERS = 2 # 层数 10 SRC_VOCAB_SIZE = 10000 # 源语言词汇表大小 11 TRG_VOCAB_SIZE = 10000 # 目标语言词汇表大小 12 SHARE_EMB_AND_SOFTMAX = True 13 14 SOS_ID = 1 15 EOS_ID = 2 16 17 class NMTModel(object): 18 def __init__(self): 19 # 与训练模型中的__init__函数相同。 20 self.enc_cell = tf.nn.rnn_cell.MultiRNNCell( 21 [tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)] 22 ) 23 self.dec_cell = tf.nn.rnn_cell.MultiRNNCell( 24 [tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)] 25 ) 26 27 # 为源语言和目标语言分别定义词向量 28 self.src_embedding = tf.get_variable('src_emb', [SRC_VOCAB_SIZE, HIDDEN_SIZE]) 29 self.trg_embedding = tf.get_variable('trg_emb', [TRG_VOCAB_SIZE, HIDDEN_SIZE]) 30 31 # softmax层的变量 32 if SHARE_EMB_AND_SOFTMAX: 33 self.softmax_weight = tf.transpose(self.trg_embedding) 34 else: 35 self.softmax_weight = tf.get_variable('weight', [HIDDEN_SIZE, TRG_VOCAB_SIZE]) 36 self.softmax_bias = tf.get_variable('softmax_bias', [TRG_VOCAB_SIZE]) 37 38 def inference(self, src_input): 39 # dynamic_rnn要求输入是batch形式,因此这里需要把输入整理为大小为1的batch 40 src_size = tf.convert_to_tensor([len(src_input)], dtype=tf.int32) # 加上`[]`使其batch为1 # shape=(1,) 41 src_input = tf.convert_to_tensor([src_input], dtype=tf.int32) # 这也要加, 与上面对应,shape=(1, 6) 42 src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input) # (1, 6, 1024) 43 44 # 构造编码器,与训练时一致 45 with tf.variable_scope('encoder'): 46 # 输入数据的rank至少为3(batch_size, max_time, ...) 47 # enc_output.shape=(1, 6, 1024) 48 enc_output, enc_state = tf.nn.dynamic_rnn( 49 self.enc_cell, src_emb, src_size, dtype=tf.float32 50 ) 51 52 # 设置解码的最大步数,以避免极端情况下出现无限循环问题。 53 MAX_DEC_LEN = 100 54 55 with tf.variable_scope('decoder/rnn/multi_rnn_cell'): # 这样写是为了与加载文件中的一致 56 # 使用一个变长的tensorarray来存储生成的句子 57 init_array = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True, clear_after_read=False) 58 # 填入第一个单词<sos>作为解码器的输入 59 # init_array.read() 60 # init_array.write() 61 # init_array.stack() 62 init_array = init_array.write(0, SOS_ID) 63 # 构建初始的循环状态,循环状态包含循环神经网络的隐藏状态,保存生成句子的tensorarry,以及记录解码步数step 64 init_loop_var = (enc_state, init_array, 0) 65 66 # tf.while_loop的循环条件: 直到解码器输出<sos>,或者达到最大步数 67 def continue_loop_condition(state, trg_ids, step): 68 # trg_ids.read(step), 即init_array.read(step) 69 # tf.reduce_all 70 return tf.reduce_all(tf.logical_and( # 去掉reduce_all也没问题 71 tf.not_equal(trg_ids.read(step), EOS_ID), 72 tf.less(step, MAX_DEC_LEN-1) 73 )) 74 75 def loop_body(state, trg_ids, step): 76 # 读取最后一步输出的单词,并读取其词向量 77 trg_input = [trg_ids.read(step)] # 加一个中括号 # (1,1) 78 trg_emb = tf.nn.embedding_lookup(self.trg_embedding, trg_input) # (1, 1, 1024) 79 # 这里不使用dynamic_rnn,而是直接调用dec_cell向前计算一步 80 dec_outputs, next_state = self.dec_cell.call(state=state, inputs=trg_emb) # (1, 1, 1024) 81 # 计算每个可能的输出单词对应的logits 82 output = tf.reshape(dec_outputs, [-1, HIDDEN_SIZE]) # (1, 1024) 83 logits = tf.matmul(output, self.softmax_weight) + self.softmax_bias # (1, 4000) 84 # 选取logit值最大的单词作为这一步的输出 85 next_id = tf.argmax(logits, axis=1, output_type=tf.int32) 86 # 将这一步输出的单词写入循环状态的trg_ids中 87 trg_ids = trg_ids.write(step+1, next_id[0]) # 写入,然后下一步输出 88 return next_state, trg_ids, step+1 89 90 # 执行循环tf.while_loop,返回最终状态 91 state, trg_ids, step = tf.while_loop(continue_loop_condition, loop_body, init_loop_var) 92 return trg_ids.stack() 93 94 95 def main(x): 96 with tf.variable_scope('nmt_model', reuse=None): 97 model = NMTModel() 98 99 test_sentence = [90, 13, 9, 689, 4, 2] 100 output_op = model.inference(test_sentence) 101 102 saver = tf.train.Saver() 103 with tf.Session() as sess: 104 105 saver.restore(sess, CHECKPOINT_PATH) 106 107 # 读取翻译结果 108 output = sess.run(output_op) 109 print('result: ', output) 110 111 if __name__ == '__main__': 112 tf.app.run()
API:
tf.string_split()、tf.string_join()
1 strs = tf.string_split([b'95 13 1590 0 4 11 90 4870 0 4 2']) 2 SparseTensor(indices=Tensor("StringSplit:0", shape=(?, 2), dtype=int64), values=Tensor("StringSplit:1", shape=(?,), dtype=string), dense_shape=Tensor("StringSplit:2", shape=(2,), dtype=int64)) # 有3个属性:indices、values、dense_shape 3 4 with tf.Session() as sess: 5 print(sess.run(strs)) 6 SparseTensorValue(indices=array([[ 0, 0], 7 [ 0, 1], 8 [ 0, 2], 9 [ 0, 3], 10 [ 0, 4], 11 [ 0, 5], 12 [ 0, 6], 13 [ 0, 7], 14 [ 0, 8], 15 [ 0, 9], 16 [ 0, 10]], dtype=int64), values=array([b'95', b'13', b'1590', b'0', b'4', b'11', b'90', b'4870', b'0', 17 b'4', b'2'], dtype=object), dense_shape=array([ 1, 11], dtype=int64))
验证是否改变shape:embedding改变、dropout、dynastic_rnn不变。具体代码看训练过程。