图来自极客时间版权所有: https://time.geekbang.org/column/article/67856
一、散列表(Hash Table)
即哈希表,散列表用的是数组支持下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
将键值映射为数组下标的方法叫做散列函数(哈希函数);
散列函数计算得到的值叫做散列值(哈希值);
散列函数设计的三点基本要求:
1、散列函数计算得到的散列值是一个非负整数;
2、如果key1=key2,那么 hash(key1) == hash(key2);
3、如果key1≠key2,那么 hash(key1) ≠ hash(key2);
因为数组下标是从0开始的,所以散列函数生成的散列值也要是非负整数;相同的key,经过散列函数得到的散列值也应该是相同的;
但是,第三点来说,要想找到一个不同的key对应的散列值都不一样的散列函数,几乎是不可能的。即便业界著名的MD5,SHA,CRC等哈希算法,也无法完全避免这种哈希冲突。而且,因为数组的存储空间有限,也会加大散列冲突的概率。
散列冲突(哈希冲突)
再好的散列函数也无法避免散列冲突。常用的散列冲突解决方案有开放寻址法和链表法。
1、开放寻址法
开放寻址法的核心思想是,如果出现了散列冲突,就重新探测一个空闲位置,将其插入。探测方法是线性探测;
即,当向散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,那就从当前位置开始,依次往后查找,看是否有空闲位置,如果遍历到尾部都没有找到空闲位置,那就从散列表表头开始找,直到找到为止。
在散列表中查找元素时,先通过哈希函数求出要查找元素的键值对应的散列值,然后比较数组中下标为散列值的元素和要查找的元素。如果相等,说明就是我们要找的元素;如果不相等,那就顺序往后依次查找,如果遍历到数组中的空闲位置,还没有找到,就说明要查找的元素并没有在散列表中。
在使用线性探测法来解决冲突的散列表中删除元素时,不能简单的将要删除的元素设置为空。因为使用线性探测法来解决冲突的散列表在查找元素时,一旦找到一个空闲位置,就会认为散列表中不存在这个数据。但是,如果这个位置是我们之前删除的,就会导致原来的查找算法失效。因此,在删除时,将删除的元素特殊标记为deleted,当线性探测查找的时候,遇到标记为deleted的空间,并不是停下来,而是继续往下探测。
线性探测的问题:当散列表中插入的元素越来越多时,散列冲突发生的可能性就会越来越大,空闲位置会越来越少,线性探测的时间就会越来越久。
不过当数据量比较小,装载因子小的时候,适合采用开放寻址法。ThreadLocalMap采用的就是开放寻址法解决散列冲突。
除了线性探测还有二次探测和双重散列。二次探测即每次探测的步长是线性探测的二次方1,4,8等
双重散列的意思是使用一组多个散列函数,先用第一个散列函数,如果得到的散列值对应的存储位置已经被占用,再使用第二个散列函数,一次类推,直到找到空闲的存储位置。
装载因子:
当散列表中空闲位置不多的时候,散列冲突的概率就会增大。为了尽可能保证散列表的操作效率,一般要尽可能保证散列表中有一定比例的空闲槽位。用装载因子(load factor)来表示空位的多少。装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
散列表的装载因子=填入表中的元素个数/散列表的长度
2、链表法
链表法是一种比开发寻址更加常用且简单的散列冲突解决办法。在散列表中每个“槽slot”对应一个链表,所有散列值相同的元素我们都放到相同槽对应的链表中。

当插入元素的时候,只需要通过散列函数计算出对应的散列槽位,将其插入到对应的链表中即可。所以插入元素的时间复杂度为O(1)。当查找、删除一个元素时,同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除。
当装载因子比较大的时候,适合使用链表法。不过当链表的长度比较大的时候,查找和删除的效率就会急剧下降。时间复杂度为O(n),n为链表的长度。而且链表由于要存储指向下个元素的指针,因此链表长度太大的话,会占据更多的存储空间!
因此,需要对链表法进行稍加改造,使其更加高效。可以将链表法中的链表改成其他高效的数据结构,使查询,删除更快;比如跳表、红黑树;查找的时间复杂度就变成了logn。也一定的避免了哈希碰撞攻击。
哈希碰撞攻击:在极端情况下,有些恶意的攻击者,还有可能通过精心构造的数据,使得所有的数据经过散列函数之后,都散列到同一个槽里。如果我们使用的是基于链表的冲突解决方法,那这个时候,散列表就会退化为链表,查询的时间复杂度就从 O(1) 急剧退化为 O(n)。
所以,基于链表法解决散列冲突的方法比较适合存储大对象、大数据量的散列表。如果用红黑树代替链表,性能更高。HashMap就是使用链表法来解决哈希冲突。JDK1.8中的hashMap在一个槽内的链表长度大于8的时候就自动将链表转成红黑树;当红黑树结点个数小于8的时候又会转化为链表。因为在数据量比较小的情况下,红黑树要维护平衡,比起链表来,性能上的优势并不明显。
树
树的高度,深度和层

二叉树(Binary Tree)
每个节点只有两个叉,也就是最多只有两个节点,分别是左子节点和右子节点。
除了叶子节点外,每个节点都有左右两个子节点的二叉树,叫 满二叉树。
叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫完全二叉树。
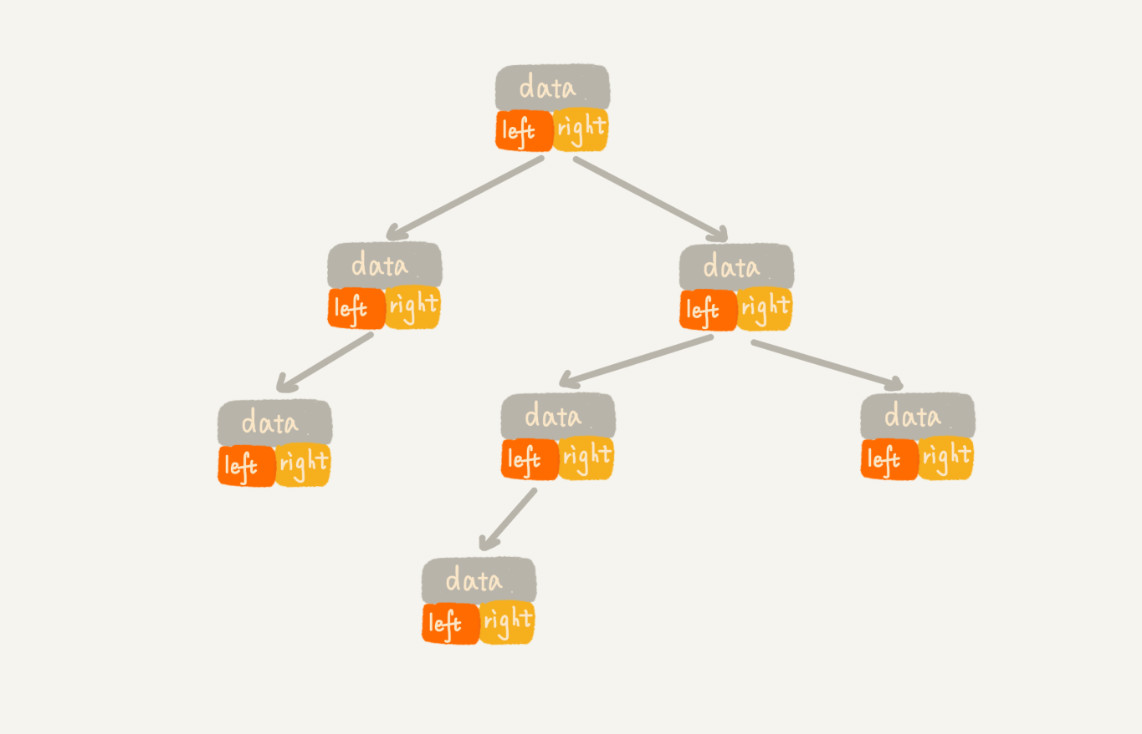
想要存储一棵二叉树,有两种方式,一种是基于指针或者引用的二叉链式存储法,一种是基于数组的顺序存储法。
链式存储法:每个节点有三个字段,其中一个存储数据,另外两个指向左右子节点的指针。
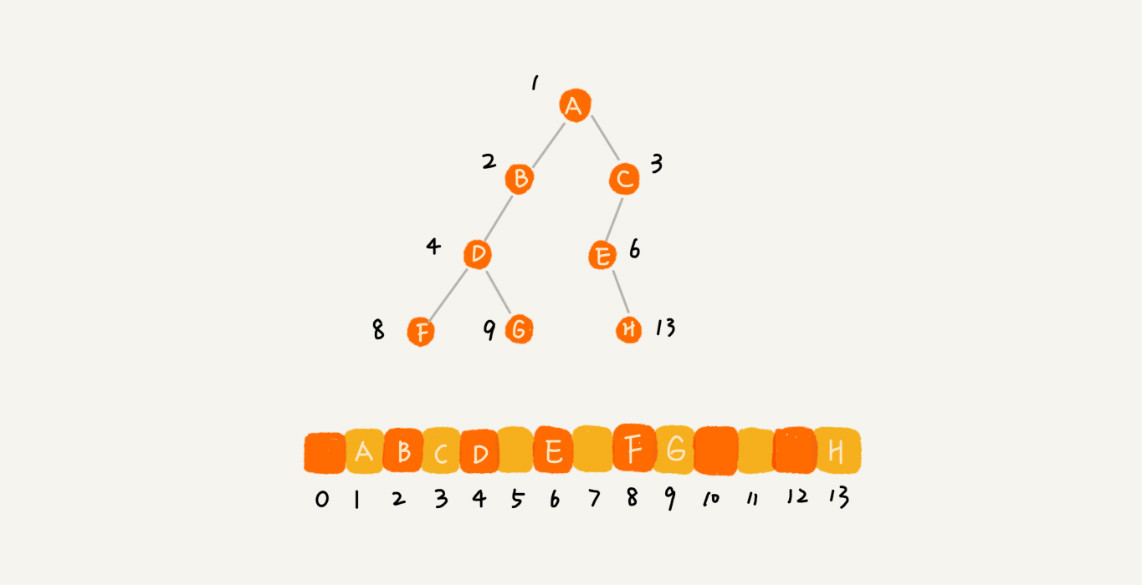
数组存储法:根节点在下标i=1的位置,左子节点存储在下标2*i=2的位置,右子节点存储在2*i+1=3的位置,依此类推。

那么如果节点X存储在数组中下标为i的位置,则节点X的左子节点在数组中的下标为2*i,节点X的右子节点在数组中的下标为2*i+1;
通过这种方式,我们只要知道根节点存储的位置,则整棵树都可以串起来。
如果是一棵非完全二叉树,则会浪费比较多的数组存储空间:
如果某棵树是一棵完全二叉树,那么数组存储无疑是最节省内存的方式,因为数组存储不需要像链式存储那样需要额外存储左右子节点的指针。这也是完全二叉树要求最后一层的子节点都靠左的原因。
堆其实就是一棵完全二叉时,最常用的存储方式是数组。
二叉树的遍历:
前序遍历:根左右<
中序遍历:左根右^
后序遍历:左右根>

实际上,二叉树的前、中、后序遍历就是一个递归的过程;
前序遍历:先打印根节点,然后递归打印左子树,最后递归打印右子树。
二叉查找树(Binary Search Tree)
二叉查找树也叫二叉搜索树,是为了实现快速查找而生的,不仅仅支持快速查找一个数据,还支持插入、删除一个数据。这依赖于二叉查找树的数据结构:在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值。
1、二叉查找树的查找操作
先取根节点,如果它等于我们要查找的数据,那就返回。如果要查找的数据比根节点的值小,那就在左子树中递归查找;如果要查找的数据比根节点大,那就在右子树中递归查找。
2、二叉查找树的插入操作
与查找类似,新插入的数据最终一般都是再叶子节点上,从根节点开始,依次比较要插入的数据和节点的大小关系;如果要插入的数据比节点的数据大,并且节点的右子树为空,就将新数据直接插入到右子节点的位置;如果不为空,那就递归遍历右子树,查找插入位置。同理,如果要插入的数据比节点数据值小,并且节点的左子树为空,就将新数据插入到左子节点的位置;如果不为空,就递归遍历左子树,查找插入位置。
中序遍历二叉查找树,可以输出有序的数据序列。时间复杂度为O(n),非常高效。所以二叉查找树又叫二叉排序树。
红黑树(Red Black Tree )
二叉查找树在频繁的动态更新过程中,可能会出现树的高度远大于log2n的情况,从而导致各个操作的效率下降。在极端情况下,二叉树会退化成链表,时间复杂度会退化为O(n)。要解决这个复杂度退化的问题,需要一种能平衡左右节点的二叉查找树。红黑树就是这种结构,因此实际上能用到二叉查找树的地方都会用红黑树(平衡二叉查找树)。
平衡二叉树:二叉树中任意一个节点的左右子树的高度差不能大于1。完全二叉树和满二叉树都是平衡二叉树。
平衡二叉查找树不仅满足平衡二叉树的定义,还满足二叉查找树的特点。最早的平衡二叉查找树是AVL树。
红黑树:一种不严格的平衡二叉查找树
1、根节点是黑色的
2、每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据
3、任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的
4、每个节点,从该节点到达其可达叶子结点的所有路径,都包含相同数目的黑色节点
为了维持平衡,需要两个重要的操作,左旋,右旋;左旋:围绕某个节点的左旋;右旋:围绕某个节点的右旋;
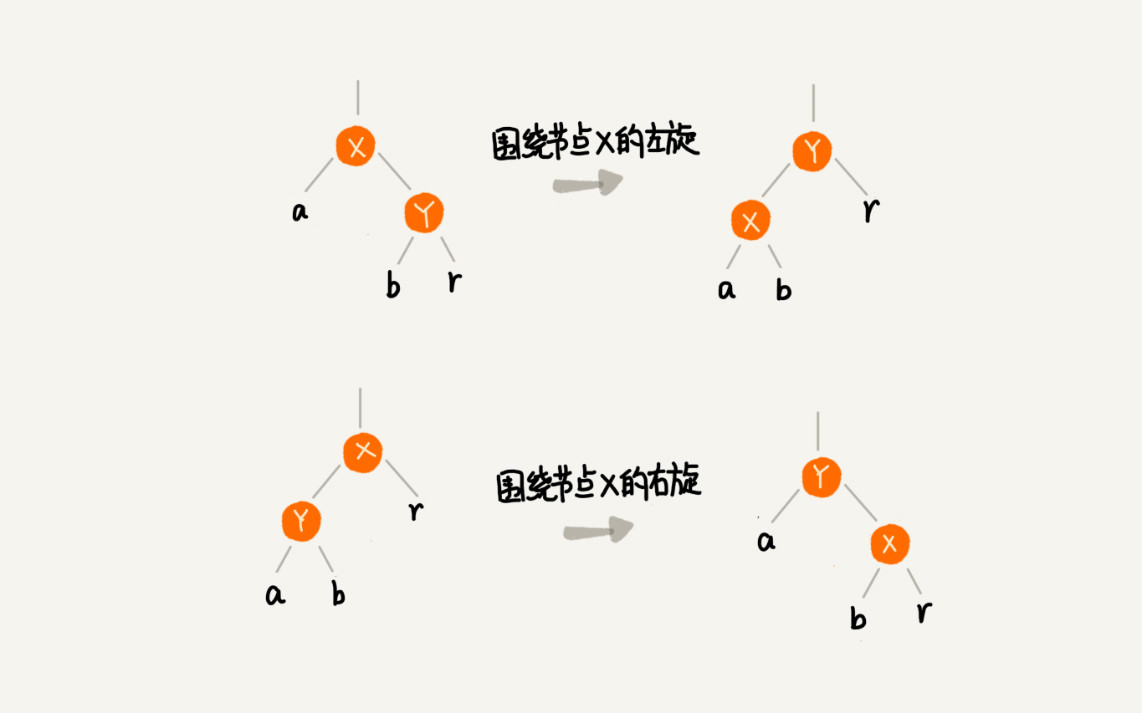
插入操作的平衡操作
红黑树规定,插入的节点必须是红色的。而且,二叉查找树中新插入的节点都是放在叶子节点上。所以插入操作的平衡调整有下面两种特殊情况:
1、如果插入节点的父节点是黑色的,那我们什么都不做,它仍然满足红黑树定义。
2、如果插入的节点是根节点,那直接改变它的颜色,将其变成黑色即可。
除此之外,其他情况都会违背红黑树的定义,需要进行调整,调整的过程包含两种基础的操作:左右旋转和改变颜色。