1、查看慢查询日志是否打开
mysql > show variables like '%slow_query_log';

2、上图显示慢日志是关着的,使用如下命令打开;
mysql > set global slow_query_log='ON';
3、再次查询,慢日志已打开
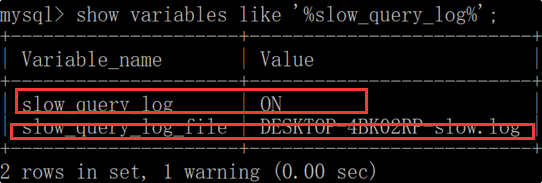
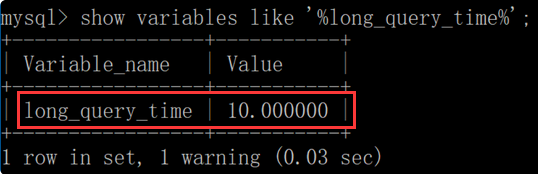
4、查看慢日志阈值时间,显示为10s;
mysql > show variables like '%long_query_time%';
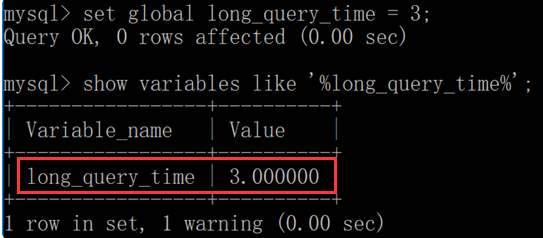
5、设置慢查询时间为3s;
mysql > set global long_query_time = 3; sql执行时间大于3s的将会写到慢日志中
6、我们可以使用 MySQL 自带的 mysqldumpslow 工具统计慢查询日志(这个工具是个 Perl 脚本,你需要先安装好 Perl)。
mysqldumpslow 命令的具体参数如下:
-s:采用 order 排序的方式,排序方式可以有以下几种。分别是 c(访问次数)、t(查询时间)、l(锁定时间)、r(返回记录)、ac(平均查询次数)、al(平均锁定时间)、ar(平均返回记录数)和 at(平均查询时间)。其中 at 为默认排序方式。
-t:返回前 N 条数据 。
-g:后面可以是正则表达式,对大小写不敏感。
比如我们想要按照查询时间排序,查看前两条 SQL 语句,这样写即可:
perl mysqldumpslow.pl -s t -t 2 "C:ProgramDataMySQLMySQL Server 8.0DataDESKTOP-4BK02RP-slow.log"

能看到开启了慢查询日志,并设置了相应的慢查询时间阈值之后,只要查询时间大于这个阈值的 SQL 语句都会保存在慢查询日志中,然后我们就可以通过 mysqldumpslow 工具提取想要查找的 SQL 语句了。
7、使用 EXPLAIN 查看执行计划
EXPLAIN SELECT comment_id, product_id, comment_text, product_comment.user_id, user_name FROM product_comment JOIN user on product_comment.user_id = user.user_id

EXPLAIN 可以帮助我们了解数据表的读取顺序、SELECT 子句的类型、数据表的访问类型、可使用的索引、实际使用的索引、使用的索引长度、上一个表的连接匹配条件、被优化器查询的行的数量以及额外的信息(比如是否使用了外部排序,是否使用了临时表等)等。
SQL 执行的顺序是根据 id 从大到小执行的,也就是 id 越大越先执行,当 id 相同时,从上到下执行。
数据表的访问类型所对应的 type 列是我们比较关注的信息。type 可能有以下几种情况:

在这些情况里,all 是最坏的情况,因为采用了全表扫描的方式。index 和 all 差不多,只不过 index 对索引表进行全扫描,这样做的好处是不再需要对数据进行排序,但是开销依然很大。如果我们在 Extral 列中看到 Using index,说明采用了索引覆盖,也就是索引可以覆盖所需的 SELECT 字段,就不需要进行回表,这样就减少了数据查找的开销。