
public class ttt { public static void main(String[] args) { long i = 1L; System.out.println(i << 2);//4 System.out.println(i);//1 System.out.println(1L << 4);//16 System.out.println(1L << 61);//2305843009213693952 System.out.println(1L << 63);//-9223372036854775808 System.out.println(1L << 64);//1 System.out.println(1L << 65);//2 System.out.println(Long.toBinaryString( 0xffL >>> -1));//0,右移64-1=63位,左边补0, System.out.println(Long.toBinaryString( 0xffffffffffffffffL));//11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 System.out.println(Long.toBinaryString( 0xffffffffffffffffL >>> -63));//01111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 System.out.println(1L << -62);//4,64-62=2,是根据前面的L确定的, System.out.println(1L << -31);//64-31=33,2^33=8589934592 System.out.println(1 << -31);//2,32-31=1, System.out.println(1 << -63);//2,32-31=1, LongBuffer1 l1 = LongBuffer1.allocate(8);//mark=-1,position=0,limit=8,capacity=8,元素都是0, LongBuffer1 ll1 = l1.slice(); LongBuffer1 ll2 = l1.duplicate(); long[] p = l1.array(); l1.put(1);l1.put(2);l1.put(3);l1.put(4);//position是下一个要放的位置,mark=-1,position=4, limit=8,capacity=8, // System.out.println(l1.get());//不反转,get的时候position继续会加1。 l1.flip();//mark=-1,position=0,limit=4,capacity=8,limit是最后一个读出去的位置下一个位置, System.out.println(l1.get()); System.out.println(l1.get());//mark=-1,position=2,limit=4,capacity=8,position是下一个要读出去的位置 LongBuffer1 ll11 = l1.slice();//ll11:mark=-1,position=0,limit=2,capacity=2,offset=position=2, //slice()得到的是原来position到limit的位置的数据,包括position不包括limit,ll11的position=0和limit=2是相对offset的位置。 //l1:mark=-1,position=2,limit=4,capacity=8, System.out.println(ll11.remaining());//2 System.out.println(ll11.get()); System.out.println(ll11.get()); System.out.println(ll11.get()); LongBuffer1 ll22 = l1.duplicate();//ll22:mark=-1,position=2,limit=4,capacity=8,,l1:mark=-1,position=2,limit=4,capacity=8, l1.flip();//mark=-1,position=0,limit=2,capacity=8, l1.put(5);l1.put(6);l1.put(7);//只能放2个了。 l1.flip(); System.out.println(l1.get());//不反转,get的时候position继续会加价 System.out.println(l1.get()); LongBuffer1 ll13 = l1.slice(); LongBuffer1 ll23 = l1.duplicate(); long[] p1 = l1.array(); LongBuffer1 l2 = LongBuffer1.wrap(new long[] {(long) 1.2,(long) 133,(long) 1.4,(long) 1.5,(long) 1.6,(long) 1.7}); } }

public class ttt { @SuppressWarnings("unused") public static void main(String[] args) { BitSet1 qq = new BitSet1(new long[] {0x71,0x121,0x2121});//16进制每个数字都是4位半个字节表示, qq.toString(); long[] l = qq.words; int i = qq.cardinality(); int j = qq.length();//142 BitSet1 qq2 = (BitSet1) qq.clone(); qq.flip(1); qq.flip(2); qq.flip(18); boolean b = qq.get(18); LongBuffer1 l1 = LongBuffer1.allocate(8); l1.put(1);l1.put(2);l1.put(3);l1.put(4); l1.flip(); BitSet1 qq3 = BitSet1.valueOf(l1); int k = qq3.cardinality(); } }
Bitset,也就是位图,由于可以用非常紧凑的格式来表示给定范围的连续数据而经常出现在各种算法设计中。
基本原理是,用1位来表示一个数据是否出现过,0为没有出现过,1表示出现过。使用用的时候既可根据某一个是否为0表示此数是否出现过。
一个1G的空间,有 8*1024*1024*1024=8.58*10^9bit,也就是可以表示85亿bit,85亿位,85亿个不同的数。数组的值为1就有这个索引的值。
//现在有1千万个随机数,随机数的范围在1到1亿之间。现在要求写出一种算法,将1到1亿之间没有在随机数中的数求出来
public static void test() throws IOException { int[] randomNums = new int[10000000]; Random random = new Random(); for (int i = 0, length = randomNums.length; i < length; i++) { randomNums[i] = random.nextInt(10000000); } long start = System.currentTimeMillis(); boolean[] bitArray = new boolean[10000000]; for (int i = 0, length = randomNums.length; i < length; i++) { bitArray[randomNums[i]] = true;//randomNums[i]是值,bitArray索引位置为true,表示有这个索引的值。 //bitArray数组值为1,表示有这个索引值。为0表示没有这个索引值。 } for (int i = 0, length = bitArray.length; i < length; i++) { if (bitArray[i]) { continue; } System.out.println(i);//打印下标就是没有的值。 } long end = System.currentTimeMillis(); System.out.println("Spend milliseconds: " + (end - start)); } }
通常是用来判断某个数据存不存在的。它最大的一个特点就是对内存的占用极小,所以经常在大数据中被优化使用。为什么说占用内存小呢?其实从名字就可以看出端倪,直译过来叫位图,但不是图形学里面的位图哦,关键单词是 Bit 。
比如通过某种方法用一个 bit 来表示一个 int,这样的话内存足足压缩至 1/32(1 int = 4 byte = 32 bit,PS:理论计算而已,实操时并不会有 1/32 这么夸张,下文会解释),所以原先需要8G内存的数据,现在只需要256M。
比如有个 int 数组 [2,6,1,7,3],内含5个元素,存储的空间大小为 5 * 32 = 160 bit,取的时候,使用元素的下标来获取对应位上的元素。把元素的值作为下标,每个下标位使用 bit 来标记,有值则为1,否则为0,此时我们只需要在内存上开辟一个 连续的二进制位 空间,长度为8(因为上面数据最大的元素是7,但是需要考虑下标起点为0),则可以表示成:

下标就是值,重复就不行了。
BitMap 最简单的说明图,蓝色代表有值
说明:初始化一个长度是8的 BitMap,初始值均为0,然后将[2,6,1,7,3]填入对应的下标处,上图中蓝色域,即将这几个下标处的值设置为1,所以表示为: 1 1 0 0 1 1 1 0 。此时占用的内存空间为 8 bit,而原来是 160 bit(顺便解释下上文提到的 1/32,因为我们开辟的是连续的内容空间,所以会有冗余,一个字节一个字节的开)。
① 案例一:还是上文的数组,需求是查询元素6是否在数组中。原先我们需要遍历整个数组,时间复杂度为 O(n);而现在我们只需要查验下标为6的字节是0还是1即可,如果是1,则代表存在,时间复杂度直接降为 O(1)。所以, 最直接的应用场景便是: 数据的查重
案例二:有两个数组,判断这两个数组中的重复元素。原先的最浅显的做法是双层for循环进行判断比较。而现在,只需要将转换完成的两个BirMap进行与运算即可,如:11001110B & 10100000B = 10000000B,所有得出结果,只有元素 7 重复。当然, 最直接的应用场景是: 每个客户都有不同的标签,当需要查找同时符合标签a和标签b的客户的时候,只需要将标签a和标签b的客户查出来进行如上的 与运算 即可。
3、补充说明
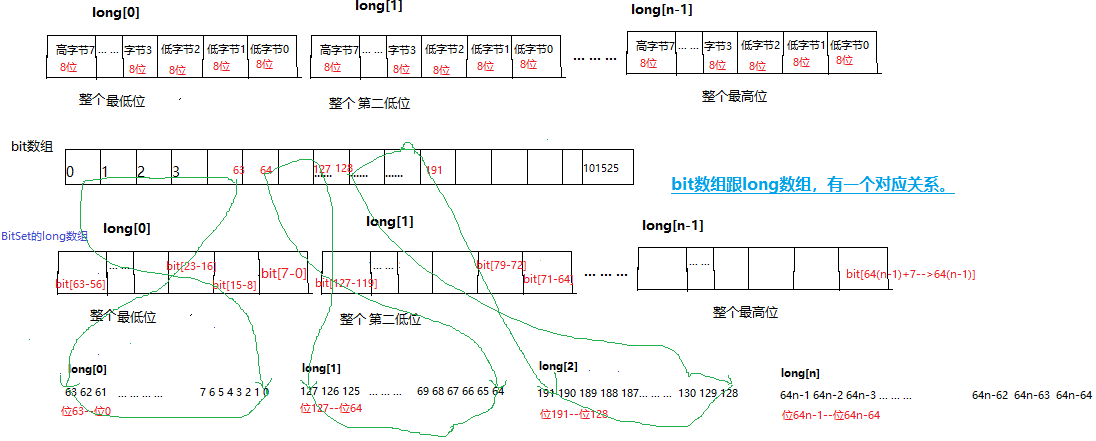
① 实际使用的时候,并不会向上面一样很随意地将长度设置为8,一般会设置为32(int型)或64(long型),理由见下文 BitSet 源码即可。
BitSet 为什么使用 long 数组而不使用 int 数组,我觉得应该是出于 Java 语言的性能考虑的,因为在进行 逻辑与等一系列位运算 的时候,是需要将两个数组中的元素一一进行位运算的,而使用 long 的一个好处是数组的长度减少了,从而遍历的次数也就减少了。
问题:对40亿个数据进行排序,数据类型为 int,无相同数据。 间隔不能太开,比如只有1,2,1000000000000,这样就浪费内存了。
思考:关于40亿个数据的排序,首先想如何存储呢?一个int 4个字节,也就是160亿个字节,也就是大概有16GB的数据,现在所有的计算机估计没有这么大的内存吧,所以我们就可以文件归并排序,也可以分段读入数据在进行Qsort,但是都需要不停地读入文件,可以想象不停地读取文件硬件操作会有多么浪费时间。
例如我们对2,1,5,12这四个数据进行由小到大的排序,首先把32位初始化为0,我们可以把这4个数据存储为0000 0000 0000 0000 0001 0000 0010 0110。索引值就是真的值(从0开始)。完成了数据从小到大的排序。
返回原题应用BitSet就可以把16GB的存储空间缩小为16GB/32 = 512M,原来一个字节32位,现在只要一位,就除以32。这是理想情况下,都是连续时候就除以32。就可以大大减少读取文件的工作。直接读一次文件存入内存,然后遍历输出就完成了排序。
使用场景:整数,无重复。