17.1-正则表达式
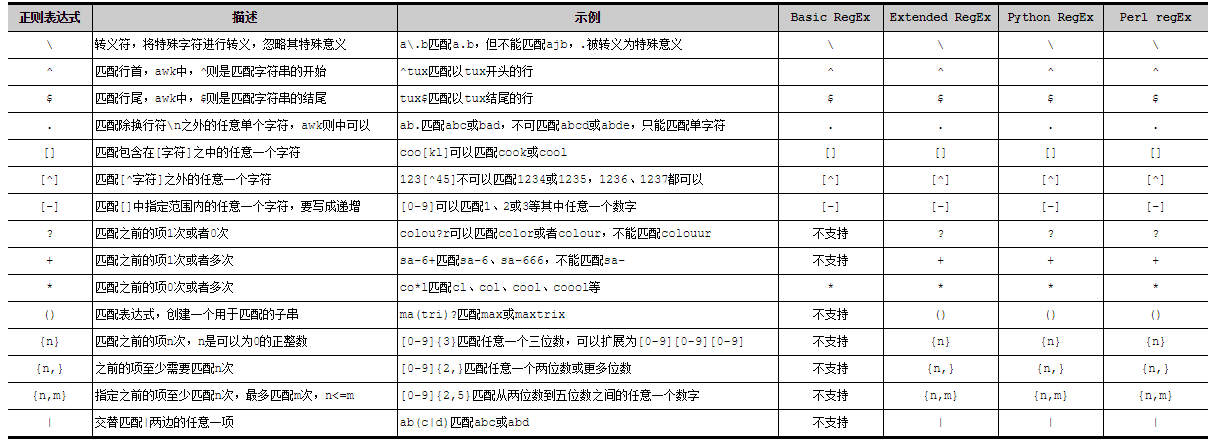
1. 正则表达式概念
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。规定一些特殊语法表示字符类、数量限定符和位置关系,然后用这些特殊语法和普通字符一起表示一个模式,这就是正则表达式(Regular Expression)。
使用原因:
- 程序设计过程中不可避免的遇到处理某些文本情况,有时候要查找符合某些比较复杂规则的字符串。正则表达式以非常简单的代码完成。
- Linux实用程序在输入数据时,将正则表达式模式和数据进行匹配。如果数据与模式一致,它接受处理(称作“匹配”)。如果数据与模式不一致,就拒绝(称作“过滤”)。
正则表达式是通过正则表达式引擎regular expression engine实现的。正则表达式引擎值是一套底层软件,负责解释正则表达式模式并使用这些模式进行文本匹配。
在linux系统中,比较流行的正则表达式引擎有两种:
- POSIX基础正则表达式引擎BRE
- POSIX扩展正则表达式引擎ERE
linux系统不同应用可以使用不同类型的正则表达式:
- 编程语言java 、perl 、python
- linux实用使用工具sed编辑器 、gawk程序、 grep工具
- 主流应用mysql、 PostgreSQL
常见的支持正则表达式的UNIX工具:
- grep命令族:用于匹配文本行
- sed流编辑器:用于改变输入流 (只符合BRE规范的子集)
- gawk程序:用于处理字符串的语言
- more或者less等:文件查看程序
- ed,vi或者vim等:文本编辑器
2. 正则表达式主要组成
- 字符类(Character Class)
- 数量限定符(Quantifier):
- 位置限定符(Anchor):描述各种字符类以及普通字符之间的位置关系
2.1 字符类
字符类(Character Class):在模式中表示一个字符,但是取值范围是一类字符中的任意一个。
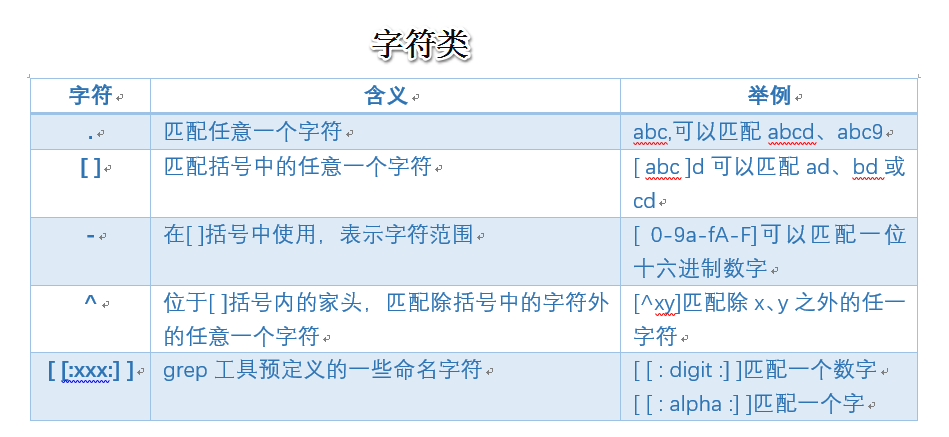
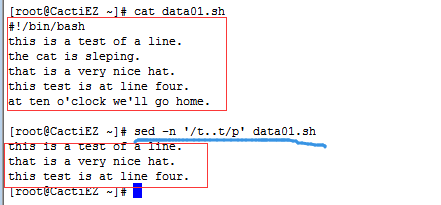
. 用来匹配除换行符之外的的任意单个字符, 它必须匹配一个字符,如果在.字符的位置没有字符,那么模式不成立。(空格也是字符)
- "s..d" 匹配在s和d这两个字母之间一定有两个字符的单词
- "s.*d" 匹配在s和d字母之间有任意字符
- ".*" 匹配所有内容
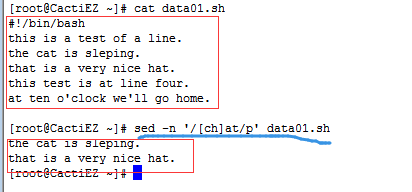
[ ]包含出现在所有该字符组中的字符,可以在单个表达式中使用多个字符组,字符组可以使字符也可以是数字。
- " [aeiou ]" 匹配任意一个元音字母,
- " [0-9] " 匹配任意一位数字,
- " [a-z][0-9] " 匹配小写字母和一位数字构成的两位字符。
- " s[ao]id " 匹配s和i字母中,要么是a,要么是o
- " ^[a-z] " 匹配小写字母开头的行
- " [^0-9] " 匹配任意一位非数字字符,
- " [^a-z] " 表示任意一位非小写字母
- " ^[^a-z] " 匹配不是小写字母开头的行
- " ^[^a-zA-Z] " 匹配不是字母开头的行
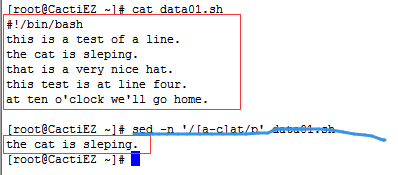
- 在[ ]号内使用表示字符范围。
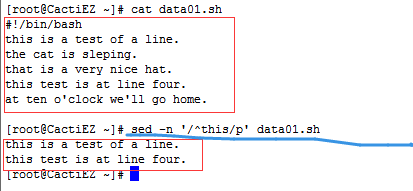
^ 脱字符定义从数据流文本行的行首开始的模式。如果模式出现在行首之外的位置,正则表达式模式则无法匹配。
- "^hello" 匹配以hello开头的行
- "^M" 匹配以大写“M”开头的行
- "[^0-9]" 匹配任意一位非数字字符,
- "[^a-z]" 表示任意一位非小写字母
- "^[^a-z]" 匹配不是小写字母开头的行
- "^[^a-zA-Z]" 匹配不是字母开头的行
[ [ :xxxx:] ] BRE特殊字符组,用来匹配特定类型的字符。
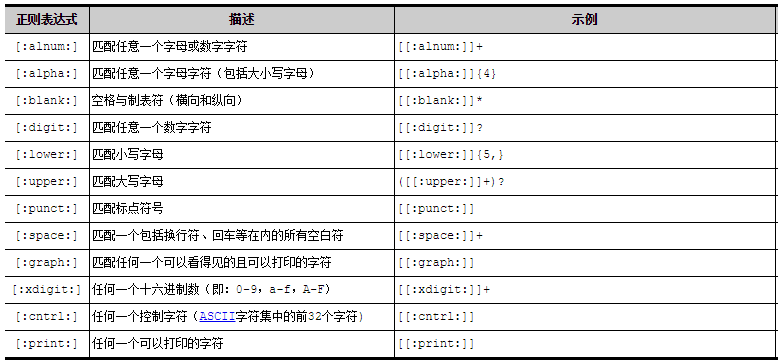
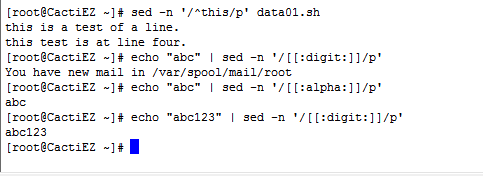
2.2 数量限定符
数量限定符(Quantifier): 每一部分可以有一个或多个x字符

2.3 位置限定符
位置限定符(Anchor):描述各种字符类以及普通字符之间的位置关系
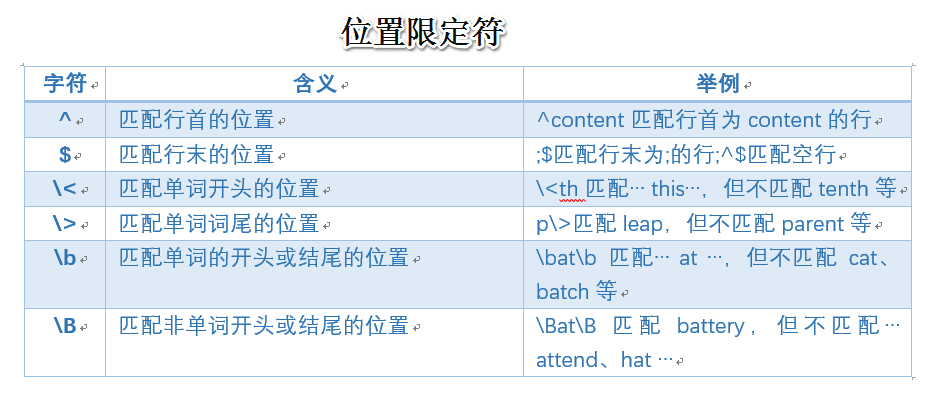
2.4 其他特殊定符

3. 正则表达式分类
- 基本的正则表达式(Basic Regular Expression 又叫Basic RegEx 简称BREs)
- 扩展的正则表达式(Extended Regular Expression 又叫Extended RegEx 简称EREs)
- Perl的正则表达式(Perl Regular Expression 又叫Perl RegEx 简称PREs)
- Python的正则表达式(Python Regular Expression 又叫Perl RegEx 简称PREs) 等