我们在处理一些网站数据的时候,有时候我们需要的数据很多都是动态加载的,而不都是静态的,以下以一个实例来介绍简单的获取动态数据,首先申明本人小白,还在学习python中,这个方法还是比较笨拙的,但是对于初学者还是需要知道的。
首先我们的要求是获取下面文章的参考文献:
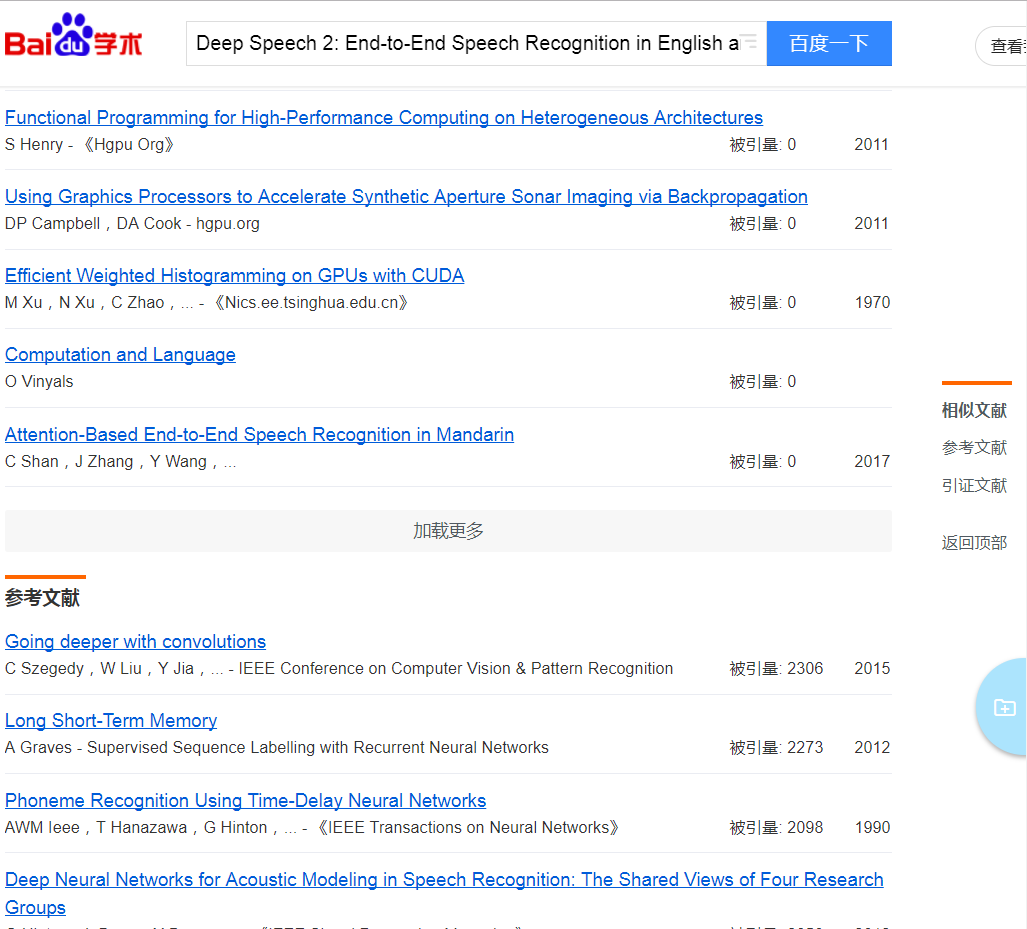
刚刚开始,我的想法是使用lxml、BeatifulSoup、正则表达式来处理,这几个是处理静态网站的常用方法,查看网页源码我们会发现相应的div里面是空,也就是说上面的数据不是静态的,而是后面动态加载的,利用googl浏览器可以看到:
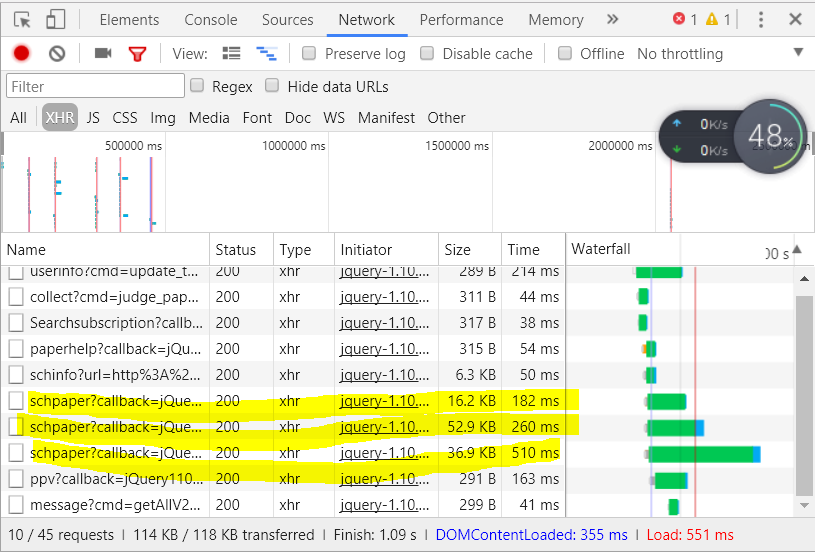
标记的三个对应了网站里面的相似文献、参考文献、引证文献,我们需要的是参考文献,所以点击第二个:
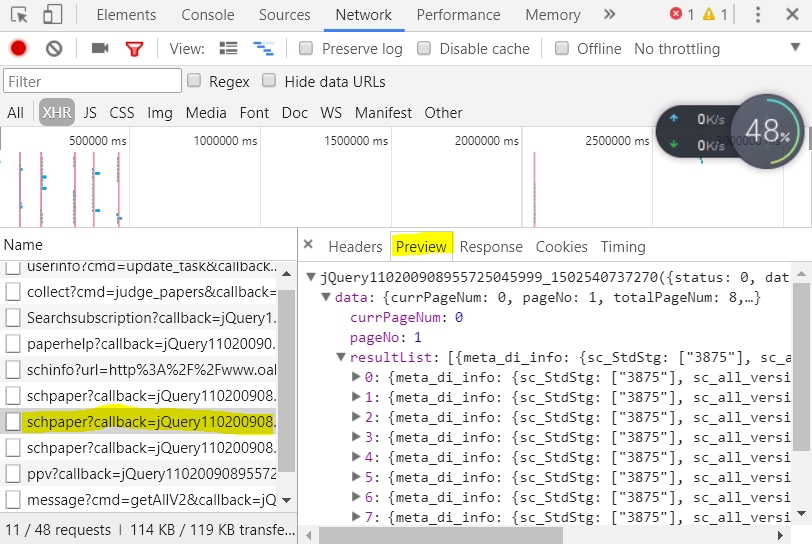
我们可以看到数据就在里面,然后点击Header,复制里面的URL:
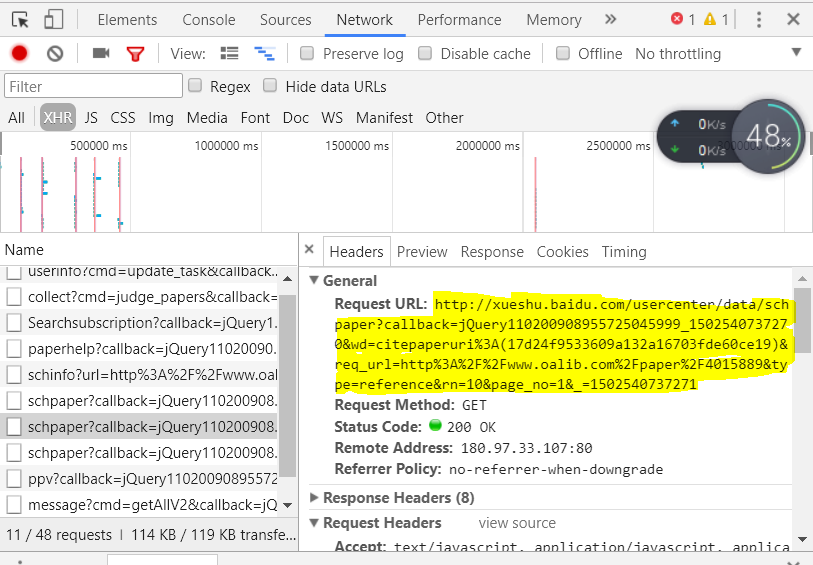
利用下面的代码就可以获取相应的数据了:
#-*- coding:utf-8 -*-
import requests
url='http://xueshu.baidu.com/usercenter/data/schpaper?callback=jQuery110208239584223582068_1502539053728&wd=citepaperuri%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2Fwww.oalib.com%2Fpaper%2F4015889&type=reference&rn=10&page_no=1'
data=requests.get(url)
print data
但是如果要获取所有的参考文献怎么办,我们不能一个链接一个链接的复制,那不就特别麻烦,下面是代码的改进,首先我们要知道总共有多少页参考文献,也就是URL里面的page_no的·值,以下为改进的代码:(其实我们也可以直接估计有50页参考文献,然后使用try。。。except。。。来获取异常也是可以的)
#-*- coding:utf-8 -*-
import requests
n=相关页数
url='http://xueshu.baidu.com/usercenter/data/schpaper?callback=jQuery110208239584223582068_1502539053728&wd=citepaperuri%3A(17d24f9533609a132a16703fde60ce19)&req_url=http%3A%2F%2Fwww.oalib.com%2Fpaper%2F4015889&type=reference&rn=10&page_no='
for i in range(1,n+1):
data=requests.get(url+str(i))
print data
返回值是json格式的,剩下的就是处理json格式了(记得除去返回的多余数据),参见:http://www.cnblogs.com/ybf-yyj/articles/7351580.html。
以下贴上所有代码:
#-*- coding:utf-8 -*- import requests import re import json def get_reference(url): data=requests.get(url) json_datas=data.content #使用贪婪算法的正则表达式获取json类型的字符串 json_data = re.compile(r"{.*}") json_data = json_data.search(json_datas).group() # 将获取的json字符串转化为字典 title_data=json.loads(json_data) n=title_data.get('data').get("resultList") for i in range(0,len(n)): try: print 'reference:', print n[i].get('meta_di_info').get('sc_title')[0] for i in n[i].get('meta_di_info').get('sc_author'): print i.get('sc_name')[1]+u',', print ' ' except: print i n=4 url='http://xueshu.baidu.com/usercenter/data/schpaper?callback=jQuery110204974031490917943_1502604841329&wd=citepaperuri%3A(0689fe98fd34a1aac82d41225ad9ceca)&req_url=http%3A%2F%2Feuropepmc.org%2Fabstract%2Fmed%2F24235252&type=reference&rn=10&page_no=' for i in range(1,n+1): get_reference(url+str(i))