NAS evaluation is frustratingly hard
2020-ICLR-NAS evaluation is frustratingly hard
来源:ChenBong 博客园
- Institute:Ecole´ Polytechnique, Huawei Noah’s Ark Lab
- Author:Antoine Yang, Pedro M Esperanca, Fabio Maria Carlucci
- GitHub:https://github.com/antoyang/NAS-Benchmark 130+
- Citation:60
Introduction
近年来NAS方法发展迅速 (NAS方法通常包括3个部分: 搜索空间, NAS搜索算法, 重训策略), 但哪个NAS方法的搜索算法最好却因为种种原因 (搜索空间, 重训策略) 等因素的不同, 而难以公平比较比较.
因此本文选择了8个开源的nas方法, 在5个数据集上通过大量实验. 提出了使用搜索算法对随机采样的acc1的相对改进(relative improvement), 作为评价搜索算法的metric, 得出了目前 sota的 nas搜索算法堪比随机采样(不是随机搜索), 各种工作中 impressive 的实验结果大多是来自于整个方法的另外2个部分: 空间设计和重训策略.
Motivation
- 尽管大部分NAS方法都是在相同的数据集(e.g. CIFAR10) 进行实验, 使用 acc1进行评估, 但是他们几乎都没有遵循相同的实验设置(相同的搜索空间, 相同的重训策略等), 而3个部分中任意一个的改进都会对 acc1 的提高有很大作用;
- 而且几乎所有的NAS方法都缺少足够的消融实验,这导致了尽管有了很多NAS方法, 我们还是不清楚这些NAS方法有效的原因是什么(搜索空间, 搜索算法, 重训策略), 也导致了很多工作都是在已知实验结果的情况下, 再提出假设来解释有效性 (Hypothesizing After the Results are Known)
- 已知3个部分中任意一个的改进都会对 acc1 的提高有很大作用, 那么使用手工精心设计的搜索空间的NAS方法, 可以被称为一个优秀的AutoML算法吗? 如果NAS的目的是在减少人工干预的情况下, 找到一个最优的结构, 那么为什么我们还在将越来越多的专家知识加入到NAS方法的流程(3部分)中呢?
Contribution
Method & Experiments
NAS的终极目标应该是针对任何一个数据集, 返回该数据集对应的最佳结构. 而不是在少数几个数据集上过拟合(专门优化, 超参等).
Benchmark
NAS方法(8个)
- DARTS, StacNAS, PDARTS, MANAS, CNAS, NSGANET, ENAS and NAO
数据集/任务(5个)
- CIFAR10, CIFAR100, SPORT8, MIT67 and FLOWERS102.
评估3个部分: 搜索空间, NAS搜索算法, 重训策略
评估 NAS搜索算法 (消融)
使用每个方法自己的 搜索空间, 重训策略不变,
消融: NAS搜索算法 vs 随机采样
- 使用随机采样 (随机采样代表了搜索空间中模型的平均性能):
- 在搜索空间中随机采样8个模型
- 使用方法自己的重训代码对所有模型进行重训(相同的seed)
- 使用NAS搜索算法:
- 在搜索空间中搜索8个模型(不同的seed)
- 使用方法自己的重训代码对所有模型进行重训(相同的seed)
报告acc1 的 mean, std
metric: (RI = 100 × (Acc_m − Acc_r)/Acc_r)
对于一个通用的NAS搜索算法, 我们期望在不同任务上, 都有 (RI>0)
超参: 使用各自方法在 CIFAR10 上的超参, 因为所有的方法都没有将超参的优化作为搜索算法的一部分, 没有报告优化超参所需的时间, 因此有理由假设这些超参应该对于其他任务也是 robust and generalizable
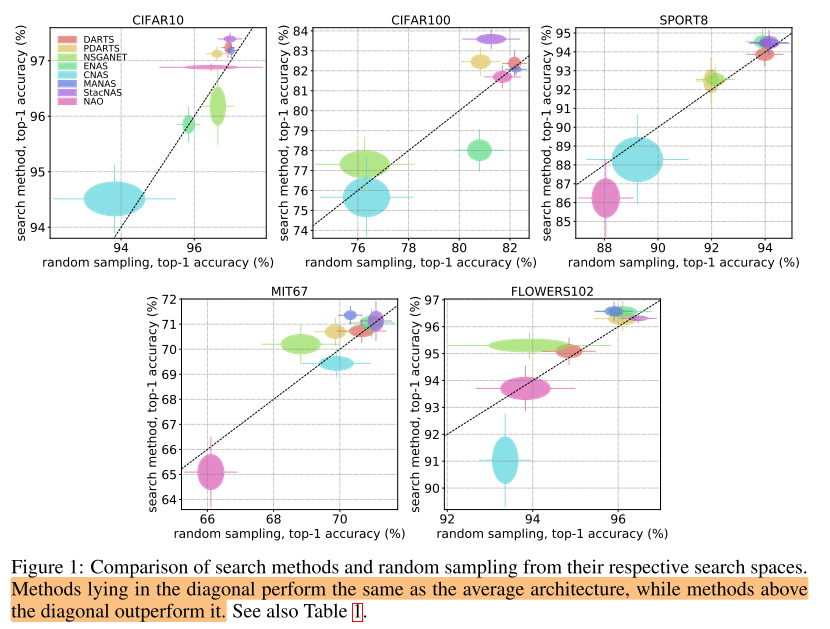

- 几乎所有nas搜索算法, 都无法在所有数据集上同时保持对随机采样的优势
- 甚至很多nas搜索算法比随机采样还要更差 ((RI<0))
- 即使能超过随机采样, 优势也不明显(2个百分点以内), 平均可能就1%以内
评估 重训策略 (消融)
使用DARTS的 搜索空间 + 随机采样
消融: 重训策略 (数据增强, dropout, droppath, epochs)
Base: similar to the one used in DARTS, but with all tricks disabled: the model is simply trained for 600 epochs.
Auxiliary Towers (A)
DropPath (D)
Cutout (C)
AutoAugment (AA)
1500 epochs (1500E)
ncreased number of channels (50C)
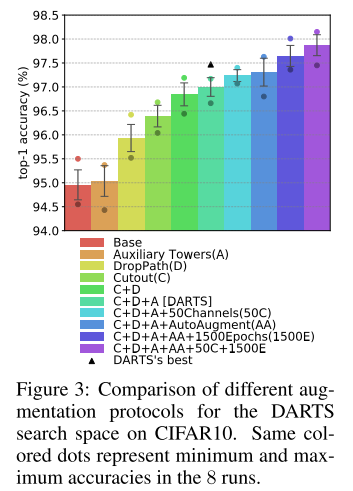
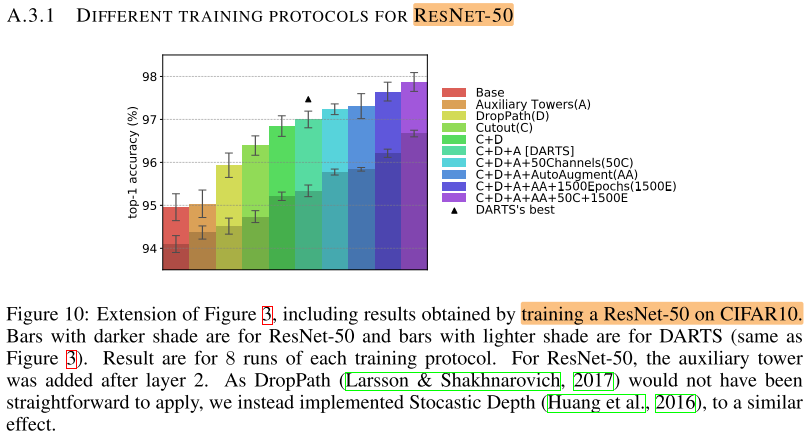
评估 DARTS的搜索空间
DARTS的搜索空间 模型性能分布

该空间中, 模型的性能分布很集中, 说明搜索空间的差异性很小
cell 中的operation
DARTs的operation集合:
- 3 × 3 and 5 × 5 separable convolutions,
- 3 × 3 and 5 × 5 dilated separable convolutions,
- 3 × 3 max pooling,
- 3 × 3 average pooling,
- identity (skip connection)
- zero
作者设计的次优的 operation集合:
- 1×1, 3×3, 7×7, 11×11 conv
- 3×3, 5×5 max pooling
- identity (skip connection)
- zero
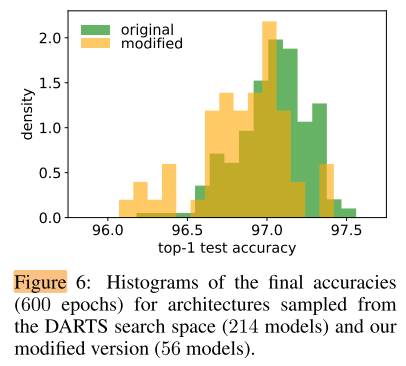
次优空间 与 原始空间 随机采样的结果只有 0.18% 的偏移, 说明操作集合的构成不是影响性能的主要因素
seed
随机采样32个网络, 使用不同的seed进行训练
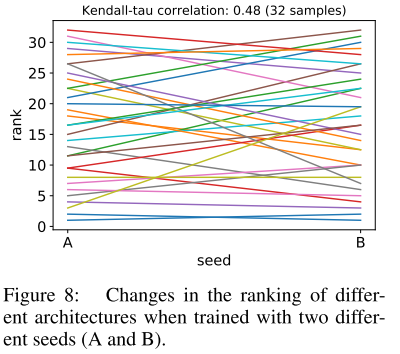
同样的结构, 完全相同的重训策略, 使用不同的seed, acc1 的相关系数只有0.48, 平均变化 0.13%±0.08 (最大的变化了0.39%), 相对于nas搜索算法对随机采样的提升(DARTS on CIFAR10 (RI=0.32)), 已经是不可忽略的变化
建议: 既然seed对结果影响很大, 最终的结果应该报告多个seed的平均值
cell 数量(超参) 的影响
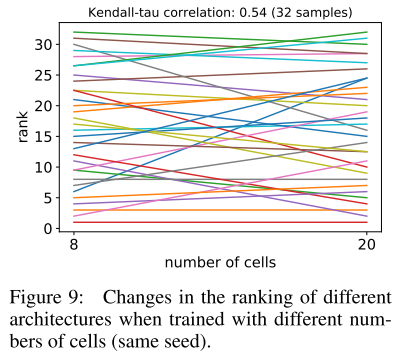
完全相同的cell, 不同的cell个数, 相关系数只有0.54, 说明很多NAS方法中, 在少量cell的模型上搜索, 搜索完再多次堆叠得到大模型的方式也是不合理的.
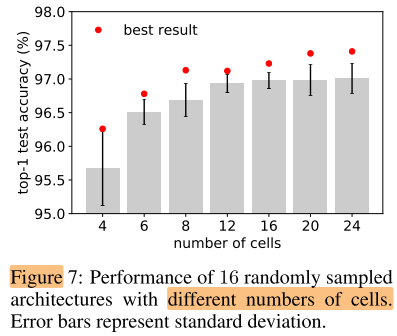
cell 数量对性能影响很大, 是一个比较重要的超参
Conclusion
作者给出的对NAS工作的一些建议:
- Augmention tricks: 同时报告w, w/o tricks 的实验结果
- Search Space:
- 报告搜索空间的随机采样性能(mean, std), 才能知道所提出的NAS搜索方法相对随机采样的提升程度
- 设计变异性更大的搜索空间(方差大), 虽然手工设计的限制性高的搜索空间可以保证良好的性能和较少的搜索开销, 但不可避免地受到专家知识的限制(局部最优)
- 宏观结构(cell数)的影响比微观结构(cell内的operation)的影响要大, 多做宏观设计上的探索(e.g. FAIR: Random wired)
- Multiple datasets: 多种数据集上的实验
- hidden components: 更充分的消融, 明确那部分起作用(cell num vs cell operation)
- reproducibility: release 代码, 超参, 最佳结构及对应的seed, 方便后续的研究者复现
- Hyperparameter tuning cost:
- 要么超参数足够general, 无需调整可以用在多个任务当中
- 要么就要报告优化这些超参数的开销, 将其计入搜索开销当中
Summary
对NAS的3个主要部分: 搜索空间, NAS搜索算法, 重训策略 做了大量的消融实验, 证明了目前的NAS搜索算法基本上相当于随机采样, 主要贡献来自于其他2个部分
pros:
- 实验设计合理, 丰富
- 给出了很多实际的建议
- 结论令人印象深刻
cons:
- 基本上都在小数据集上实验, 没有大数据集上的实验结果
To Read
Reference
NAS EVALUATION IS FRUSTRATINGLY HARD_丶小祖宗的博客-CSDN博客
ICLR 2020| NAS evaluation is frustratingly hard - 知乎 (zhihu.com)