这是我以前遇到的一个网站:人卫临床助手,这个网站比较奇怪,不能点击右键查看源码,但是大家可以使用ctrl+U,打开开发者选项,点击network,然后点击第2页和第3页:
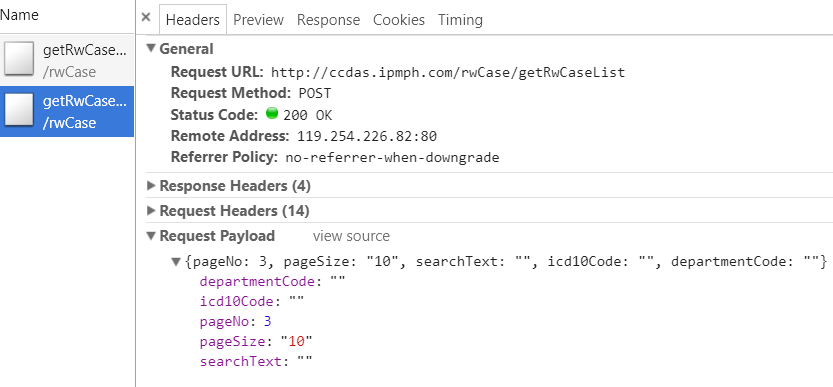
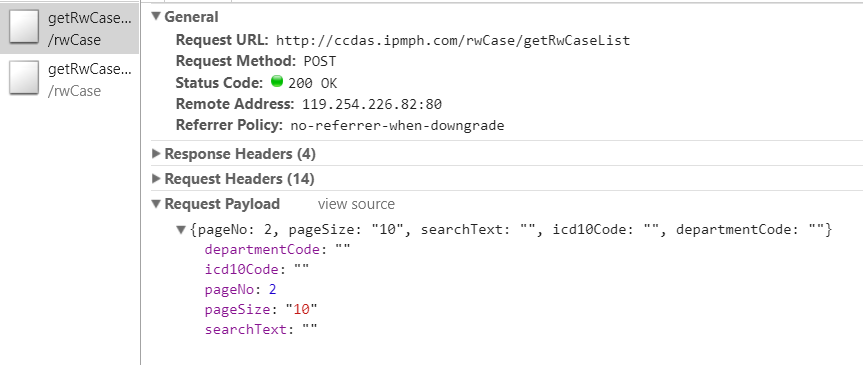
可以看到上面的URL是一模一样的,这是我以前没见过的,可以参考我最早写的博客:python获取动态网站上面的动态加载的数据(初级),那些包里面的URL是不一样的,通过URL可以得到相关的json数据,但在这里是不一样的,所以这里要用selenium模仿键盘输入来爬取数据:
#-*- coding:utf-8 -*- from selenium import webdriver from selenium.webdriver.common.keys import Keys import time from bs4 import BeautifulSoup diver=webdriver.Firefox() diver.get('http://ccdas.ipmph.com/typicalCase/goTypicalCase')
#等待网站加载完成
time.sleep(5) #输入第3页 diver.find_element_by_id('gogogo').send_keys('3') #点击跳转 diver.find_element_by_id('gogo').send_keys(Keys.ENTER) time.sleep(5) soup=BeautifulSoup(diver.page_source,'lxml') items=soup.find_all('div',{'class':'ResultList'}) for i in items: print i.find('div',{'class':'ResultList_title'}).find_all('a')[1].get_text() print i.find('div',{'class':'ResultCont'}).find('p').get_text() diver.close()
本人遇到一个问题,每次第一次爬取,diver.find_element_by_id('gogo').send_keys(Keys.ENTER)事件不响应,利用断点查看发现当网站没加载完成,该事件就不会被执行