一、简介
本文主要是要利用百度提供的NLP接口对搜狐的新闻做分类,百度对NLP接口有提供免费的额度可以拿来练习,主要是利用了NLP里面有个文章分类的功能,可以顺便测试看看百度NLP分类做的准不准。详细功能与使用方式可以上(http://ai.baidu.com/tech/nlp/topictagger)观看。
二、建立爬虫
首先要先写一个可以快速爬取所有文章内容的爬虫程序,关于爬虫的原理可以看我之前写的介绍(https://www.cnblogs.com/yenpaul/p/9968015.html),这边就直接附上代码
def all_url(): url = 'http://news.sohu.com/' data = requests.get(url).text s = etree.HTML(data) print(' ') urls0 = s.xpath('/html/body/div[*]/div[*]/div[1]/div/div[*]/div[*]/div[*]/ul/li[*]/a/@href') urls1 = s.xpath('/html/body/div[*]/div[*]/div[1]/div/div[*]/div[*]/div/div[*]/div[*]/ul/li[*]/a/@href') urls2 = s.xpath('/html/body/div[*]/div[*]/div[1]/div[*]/div[*]/ul/li[*]/a/@href') urls3 = s.xpath('/html/body/div[*]/div[*]/div[1]/div/div[*]/div[*]/ul/li[*]/a/@href') urls_all = urls0+urls1+urls2+urls3 f = open('urllist.txt','a') for url in urls_all: f.write(url) f.write(" ") f.close()
先把搜狐首页的新闻链接全部抓下来放在“urllist.txt”的文件里面
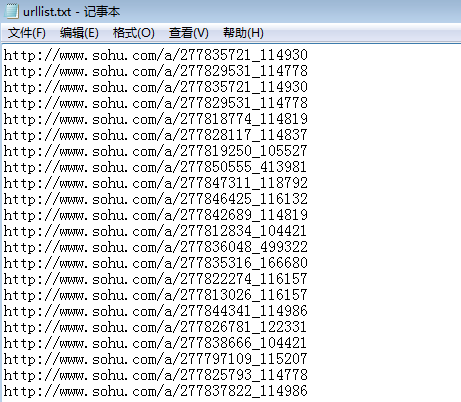
可以看到这边都是新闻的链接,也就是我接下来要去爬取得网页
三、申请接口权限
由于是要利用百度的接口,必须要先在百度注册账号然后登陆,然后需要先创建一个项目,创建完会得到一组APP_ID,APP_KEY,APP_SECRECT,是用在接下来的接口鉴权上的,创建完再查看百度AI的API文档,python的可以看这边(http://ai.baidu.com/docs#/NLP-Python-SDK/top)
然后下拉到文章分类的接口

可以看到他需要两个参数,分别是文章的标题和文章的内容,再看返回参数的格式

我们只需要知道分类的这个tag放哪里就好
四、抓取资料,提供数据给接口
接着就是要去抓取资料,我们需要去抓“标题”和“内文”传给这个接口,并将返回的结果写入“xinwen.txt”这个记事本,下面是代码
def get_content(): f = open('urllist.txt') u = 0 for url in f: u = u+1 print(u) head = {} head['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36' req = request.Request(url, headers=head) response = request.urlopen(req) data = response.read().decode('utf-8') s = etree.HTML(data) title = s.xpath('//*[@id="article-container"]/div[2]/div[1]/div[1]/h1/text()') content = s.xpath('//*[@id="mp-editor"]/p/text()') content_text = ''.join(content) type = client.topic(title, content) f = open('xinwen.txt','a') f.write('##') f.write(type['item']['lv1_tag_list'][0]['tag']) f.write('##') f.write(title[0]) f.write(' ') f.close()
由于搜狐也是有反爬虫,需要伪装user-agent,下面就是输出到文件的结果
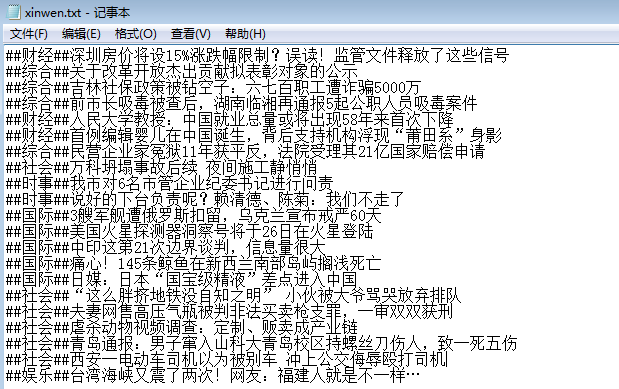
可以看到百度分类的还算可以,不过没有分的很细,像是时事跟综合这两个的范围也太广了,大部分的新闻分这两个几乎不会错,然后也是有几个新闻分类错,例如最后一个明显不是娱乐新闻。