转载请注明原文地址: https://www.cnblogs.com/ygj0930/p/13563195.html
一:LinkedList特征
1、LinkedList底层是一个双向链表,可以被当做 堆栈、队列、双端队列 来使用。【能且应该仅被作为 栈、队列、双端队列 来使用!】
双向链表,又称为“双向循环链表”,每个数据结点中都有两个引用,分别指向直接后继和直接前驱节点,可以理解为它是一个“首尾相接”的环形链表。
从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点,从而可以从任意一个结点开始往后或者往前遍历完整个链表。
2、LinkedList的操作不是线程安全的,建议在单线程环境下使用。多线程中可以选择JUC并发包中的LinkedBlockingDeque。
3、因为底层是双向链表,那么它的顺序访问会[从表头开始迭代访问]非常高效,而随机访问[只查找某具体节点]效率比较低。
4、因为双向链表添加元素只是新增一个节点,延长链表而已,因此LinkedList 不存在容量不足的问题
二:LinkedList继承与实现关系
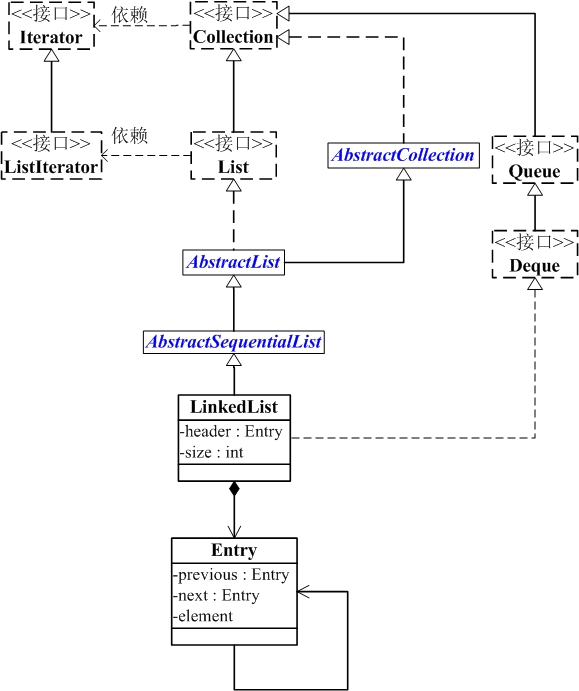
1、继承层次
java.lang.Object ↳ java.util.AbstractCollection<E> ↳ java.util.AbstractList<E> ↳ java.util.AbstractSequentialList<E> ↳ java.util.LinkedList<E>
2、类定义与实现
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable {}
1)LinkedList 继承于AbstractSequentialList,AbstractSequentialList 实现了get(int index)、set(int index, E element)、add(int index, E element) 和 remove(int index)等方法,支持随机访问List。
2)LinkedList 实现 了 List 接口,因此具备了 队列操作的方法。
3)LinkedList 实现 了 Deque 接口,因此具备了 双端队列操作方法。
4)LinkedList 实现了Cloneable接口,即重写 clone(),支持克隆。
5)LinkedList 实现了java.io.Serializable接口,支持序列化。
三:LinkedList原理
LinkedList的本质是双向链表,包含两个重要的成员变量:header 和 size。
1)header是双向链表节点类Entry的实例,LinkedList中只需要存放表头节点即可,表头header不包含数据,只存放前驱节点和后继节点的引用,其中:表头的前驱节点就是双向链表的最后一个元素节点,表头的后继节点就是双向链表的第一个元素节点。
Entry节点类中包含三个重要的成员变量: previous, next, element。previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。
2)size是LinkedList实例中双向链表中节点的个数。
四:LinkedList关键方法
1、如何实现在双向链表中用索引下标进行“随机访问”查找?
通过一个计数索引值来实现:当我们调用get(int location)等用索引下标进行查找时,首先会比较“location”和“size/2”[即双向链表长度的1/2]的大小:
若前者大,则从链表头开始往后查找,直到location位置;否则,从链表末尾开始先前查找,直到location位置。
2、实现Deque接口定义双端队列两端元素的操作方法,每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null或false)。
操作第一个元素(头部) 操作最后一个元素(尾部)
抛出异常 返回特殊值 抛出异常 返回特殊值
插入 addFirst(e) offerFirst(e) addLast(e) offerLast(e)
移除 removeFirst() pollFirst() removeLast() pollLast()
检查 getFirst() peekFirst() getLast() peekLast()
3、LinkedList作为FIFO(先进先出)的队列使用时的常用方法
队列方法 等效方法
add(e) addLast(e)
offer(e) offerLast(e)
remove() removeFirst()
poll() pollFirst()
element() getFirst()
peek() peekFirst()
4、LinkedList作为LIFO(后进先出)的栈使用时的常用方法
栈操作方法 等效方法
push(e) addFirst(e)
pop() removeFirst()
peek() peekFirst()
5、LinkedList的遍历
1)迭代器遍历
for(Iterator iter = list.iterator(); iter.hasNext();) iter.next();
2)下标访问
list.get(i);
3)for-each迭代
for (Integer integ:list)
4)保持从一个方向遍历,边遍历边删除,如果不存在则返回特殊值
从前往后:
while(list.pollFirst() != null)
从后往前:
while(list.pollLast() != null)
5)保持从一个方向遍历,边遍历边删除,如果不存在则报异常
从前往后:
try { while(list.removeFirst() != null) } catch (NoSuchElementException e) { }
从后往前:
try { while(list.removeLast() != null) } catch (NoSuchElementException e) { }
以上遍历方式的效率:removeFist()或removeLast()效率最高,for-each或pollFirst()或pollLast或Iterator迭代器次之,下标访问迭代最慢[而且是超级慢,几千倍的差异]。
如果只查找一次,并且查找完后不再需要数据,则使用removeFist()或removeLast(),注意需要捕获异常;
如果读取但是不能删除元素,则使用for-each迭代;
同时,根据上面可以知道,LinkedList适用于:栈、队列、双端队列 这三种数据结构的使用场景,即:每次操作都是针对首尾元素,内容访问也是全部迭代为主的情况,不适用于传统数组那种下标访问的场景。
如果业务场景下需要频繁使用到get(i)访问内容的,不应该使用LinkedList,而是使用ArrayList。
可大概记忆为:ArrayList用于不定长数组的场景,它会自动扩容,不用担心容量不足。当真的出现ArrayList也存不下的内容时,说明应该借助redis中间件等其他东西了,也不应该换用LinkedList来达到不限容量的效果;
LinkLinkedList用于满足 栈、队列、双端队列 的使用场景,仅此而已,不能作为不定长数组来使用。
6、LinkedList在指定位置插入、移除比ArrayList快的原因
LinkedList 向指定位置插入元素的代码:


// 在index前添加节点,且节点的值为element public void add(int index, E element) { addBefore(element, (index==size ? header : entry(index))); } // 获取双向链表中指定位置的节点 private Entry<E> entry(int index) { if (index < 0 || index >= size) throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size); Entry<E> e = header; // 获取index处的节点。 // 若index < 双向链表长度的1/2,则从前向后查找; // 否则,从后向前查找。 if (index < (size >> 1)) { for (int i = 0; i <= index; i++) e = e.next; } else { for (int i = size; i > index; i--) e = e.previous; } return e; } // 将节点(节点数据是e)添加到entry节点之前。 private Entry<E> addBefore(E e, Entry<E> entry) { // 新建节点newEntry,将newEntry插入到节点e之前;并且设置newEntry的数据是e Entry<E> newEntry = new Entry<E>(e, entry, entry.previous); // 插入newEntry到链表中 newEntry.previous.next = newEntry; newEntry.next.previous = newEntry; size++; modCount++; return newEntry; }
LinkedList插入元素时:先在双向链表中找到要插入节点;找到之后,再插入一个新节点。
而双向链表查找index位置的节点时,有一个加速动作,即“计数索引”:若index < 双向链表长度的1/2,则从前向后查找; 否则,从后向前查找。
ArrayList 向指定位置插入元素的代码:
// 将e添加到ArrayList的指定位置 public void add(int index, E element) { if (index > size || index < 0) throw new IndexOutOfBoundsException( "Index: "+index+", Size: "+size); ensureCapacity(size+1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; }
ArrayList插入元素时:需要借助System.arraycopy方法,移动index之后所有元素,因此在指定位置插入元素比较慢。
7、LinkedList查找指定位置元素比ArrayList慢的原因
LinkedList查找元素时,先借助“计数索引”确定遍历方向,然后从前往后或者从后往前逐个遍历,直到目标位置;
而ArrayList底层是个数组,可以直接根据索引找到该位置。
五:Stack
1、特征
Stack是用于先进后出场景下的栈实现类。
Stack是线程安全的,也是通过synchronized修饰方法来实现。
Stack底层是数组实现。
2、原理
Stack是继承于Vector(矢量队列)的,由于Vector是通过数组实现的,这就意味着,Stack也是通过数组实现的!
Stack和继承于Vector,因此它包含Vector中的全部API,然后再额外封装了用于栈操作的一系列方法:
boolean empty() synchronized E peek() synchronized E pop() E push(E object) synchronized int search(Object o)
3、源码分析
package java.util; public class Stack<E> extends Vector<E> { // 版本ID。这个用于版本升级控制,这里不须理会! private static final long serialVersionUID = 1224463164541339165L; // 构造函数 public Stack() { } // push函数:将元素存入栈顶 public E push(E item) { // 将元素存入栈顶。 // addElement()的实现在Vector.java中 addElement(item); return item; } // pop函数:返回栈顶元素,并将其从栈中删除 public synchronized E pop() { E obj; int len = size(); obj = peek(); // 删除栈顶元素,removeElementAt()的实现在Vector.java中 removeElementAt(len - 1); return obj; } // peek函数:返回栈顶元素,不执行删除操作 public synchronized E peek() { int len = size(); if (len == 0) throw new EmptyStackException(); // 返回栈顶元素,elementAt()具体实现在Vector.java中 return elementAt(len - 1); } // 栈是否为空 public boolean empty() { return size() == 0; } // 查找“元素o”在栈中的位置:由栈底向栈顶方向数 public synchronized int search(Object o) { // 获取元素索引,elementAt()具体实现在Vector.java中 int i = lastIndexOf(o); if (i >= 0) { return size() - i; } return -1; } }
Stack实际上是通过数组去实现的:
执行push时(即,将元素推入栈中),是通过将元素追加的数组的末尾中。
执行peek时(即,取出栈顶元素,不执行删除),是返回数组末尾的元素。
执行pop时(即,取出栈顶元素,并将该元素从栈中删除),是取出数组末尾的元素,然后将该元素从数组中删除。
因为Stack是通过synchronized来实现同步的,多线程环境下表现一般,而且Stack只实现了栈的功能,适用场景比较单一,现在已过时。
如果想要在多线程环境下使用栈、队列、双端队列,我们推荐使用LinkedBlockingDeque,其功能更丰富,不单单支持栈功能;而且LinkedBlockingDeque的锁机制更加灵活,在多线程环境下性能更加。