室外点云语义分割的特点:
剧烈变化的点密度是点云室外场景语义分割的难点。
pointcnn
pointconv(论文翻译:https://zhuanlan.zhihu.com/p/63189649
https://zhuanlan.zhihu.com/p/69597887)
DGCNN
ShellNet(有室外)
论文:Hierarchical Point-Edge Interaction Network for Point Cloud Semantic Segmentation
https://zhuanlan.zhihu.com/p/85417276
SGPN
PointNet
论文全称:Deep Learning on Point Sets for 3D Classification and Segmentation
会议名称:Computer Vision and Pattern Recognition (CVPR) 2017
项目地址:https://github.com/charlesq34/pointnet
PointNet++
论文全称:Deep Hierarchical Feature Learning on Point Sets in a Metric Space
会议名称:Conference on Neural Information Processing Systems (NIPS) 2017
项目地址:https://github.com/charlesq34/pointnet2
SEGCloud
论文全称:Semantic Segmentation of 3D Point Clouds
会议名称:International Conference of 3D Vision (3DV) 2017, Spotlight
项目地址:无
RSNet
论文全称:Recurrent Slice Networks for 3D Segmentation of Point Clouds
会议名称:Computer Vision and Pattern Recognition (CVPR) 2018, Spotlight
项目地址:https://github.com/qianguih/RSNet
PointSIFT
论文全称:A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation
会议名称:Computer Vision and Pattern Recognition (CVPR) 2018
三维数据的表示方法
- point cloud:点云,也就是三维坐标系统中点的集合,这些点通常以x,y,z坐标来表示,并且一般用来表示物体的外表形状。当然,除了最基本的位置信息以外,也可以在点云中加入其他的信息,如点的色彩信息等。大多数的点云是由3D扫描设备获取的,如激光雷达,立体摄像机,深度相机等。
- Mesh:网格,是由一组凸多边形顶点以及凸多边形表面组成的,也叫做非结构化网格。多边形网格是希望通过一种易于渲染的方式来表示三维物体模型。在三维可视化等方面有很大的作用。现在有很多种方法来将点云转换成多边形网格。
- Voxel:体素,概念上类似于二维空间中的最小单位--像素,体素可以看作是是数字数据在三维空间分区中的最小单位,体素化是一种规格化的表示方法,在很多方面都有着重要的应用。
- Multi-View Images:多视角图片,是通过不同视角的虚拟摄像机从物体模型中获取到的二维图像的集合。多视图通常需要使用比较多的图片来构建完整的三维模型,在固定图片数量的情况下,很容易受到物体自遮挡等因素的影响。

图1:三维模型的表示方法(来源:stanford bunny)
三维深度学习的难点与挑战:
点云的非结构化
二维图像是结构化的,可以使用一个二维矩阵进行表示,但是在三维表示方法中,点云以及多边形网格都是非结构化的,想要直接输入到神经网络架构中是非常困难的,而将点云数据进行体素化,然后使用深度学习模型进行特征提取的方法虽然效果很好,但是由于这种方法占用的内存太多,导致只能使用比较小分辨率的体素网格。
点云姿态变换的类别不变性
物体在三维空间中的姿态是任意的,将物体点云进行旋转平移操作,虽然改变了点云中的点的坐标,但是物体的类别其实是没有改变的,因此在三维深度网络架构过程中需要考虑到如何保证神经网络对于姿态的不变性。
点云数据的多样性
实际场景中得到物体多种多样,不同对象的点云在尺度上差距很大,模型能否处理不同尺度的点云也是非常大的挑战,还有就是,现在的点云数据集相较于二维方面的数据集来说,还是比较少的,这对于深度学习来说也是一个不小的挑战。
三维深度学习的方法
基于体素化的方法
这种方法的核心思想就是将无序的点云进行体素化,使之变成规格化的表示方法,然后使用3D CNN网络架构进行特征学习,来达到分类或是目标检测的目的。其中,比较有代表性的文章有3D ShapeNets [1],VoxNet [2]等,图2就是3D ShapeNets的网络架构以及数据的可视化图片。
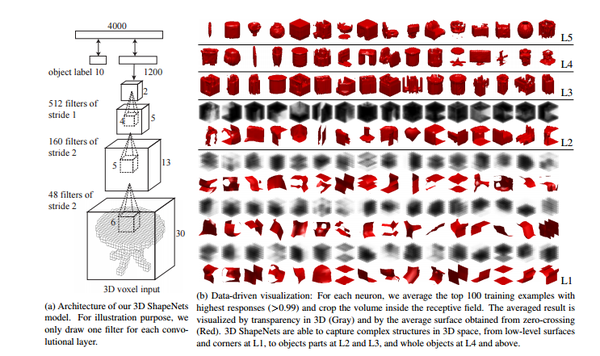 图2:3D ShapeNets(来源:[1])
图2:3D ShapeNets(来源:[1])
3D ShapeNets 的网络架构很简单,前三层是卷积层,第四层是全连接层,并且为了降低对外形的影响,网络中没有使用池化层,当然还有一些细节上的处理,包括对2.5D点云进行识别时的NextBestView预测的方法,这里就不详细讲解了,感兴趣的可以查看原论文。
其实这种方法可以看作是模拟二维深度学习的过程,只是将图片变成了体素网格,2D CNN变成了3D CNN,确实在分类方面取得了很好的性能。
但是这种方法也存在着很明显的缺点,首先,由于使用的是3D CNN和三维体素网格,导致计算过程中占用内存很大,且需要较长时间训练;这种情况下输入的体素网格的分辨率(30*30*30)也很低,所以还会存在局部信息的丢失,也就导致这种方法很难应用于大场景物体检测与定位中。
基于多视角图片的方法
区别于体素化的方法,多视角图片在处理三维问题核心思想是,希望通过使用物体在不同视角下的图片来将三维物体的表面特征完整表示出来,接下来就可以直接使用现在非常成熟的2D CNN技术进行识别与检测。这种技术的思想想并不难理解,其实跟人眼分类物体的方法相似,如果在某一个角度无法正确对物体进行分类,那么我们可以换一个角度试着去进行分类,多视角的方法就是使用了这种思想。在这方面比较具有代表性的论文就是Multi-view CNN [3]。
Multi-view CNN 通过对多个视角的图片学习到特征,然后达到比使用单张图片更好的性能。Multi-view CNN 主要分为两个步骤:1)使用在ImageNet预训练好的VGG网络提取特征,2)将这些特征组合在一起,然后再进一步的输入到可训练的CNN网络中进一步的进行特征学习然后输出分类结果。
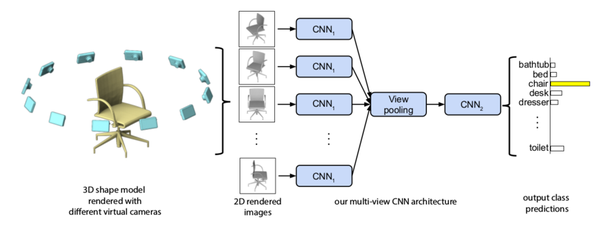 图3:Multi-view CNN架构(来源:[3])
图3:Multi-view CNN架构(来源:[3])
虽然这种方法取得了非常好的分类识别结果,但是,这种方法同样存在很大的限制,首先就是网络不允许我们无限制的使用各个视角的图片,所以固定数量的多视角图片可能无法将三维模型完全表示出来,很可能出现信息的丢失,比如物体自遮挡等。还有就是使用二维图片本身就会损失一些三维上的结构信息。当然,在复杂场景下,上面的两个限制就表现的更加明显了。
基于点云的方法
PointNet[4]
其实多视角图片和体素化的方法都有着相似的中心思想,就是希望通过将点云变换成规则化的、可以通过CNN直接进行处理的形式。而直接对点云进行处理的深度学习方法跟上述两种方法最大的不同就是,它是可以直接使用这些三维点的位置信息的。在这方面比较有代表性的就是PointNet方法。
PointNet主要是解决了两个核心问题:点云的无序化和物体姿态变换的不变性。
1)由于点云是无序的,那么最基本的就是需要保证的就是网络对同一点云的不同输入顺序的不变性,PointNet的解决方案是使用一个比较简单的对称函数,如图4所示:
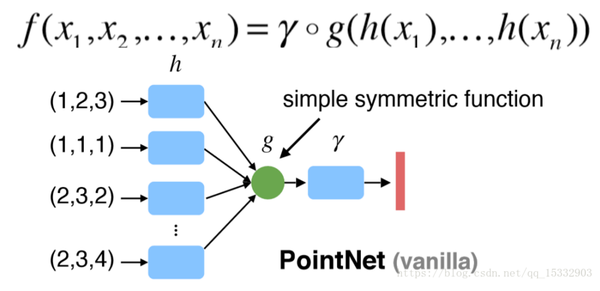 图4:PointNet对称函数(来源:[4])
图4:PointNet对称函数(来源:[4])
其中h是特征提取函数,在PointNet中就是MLP,g就是对称函数,可以是max、average等函数,在PointNet中用的是max函数,γ则代表的是网络更高层的特征提取函数。
2)在解决点云的无序性问题之后,还有一个非常重要的问题,那就是点云的旋转不变特性,点云在旋转过后的类别是不会发生改变的,所以PointNet在这个问题上参考了二维深度学习中的STN[5]网络,在网络架构中加入了T-Net网络架构,来对输入的点云进行空间变换,使其尽可能够达到对旋转的不变性。
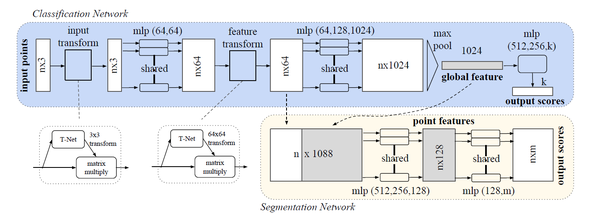 图5:PointNet网络架构(来源:[4])
图5:PointNet网络架构(来源:[4])
图5就是PointNet的整体网络架构,整体的架构中主要使用了MLP层进行特征提取以及T-Net层进行空间变换,并且在求解全局特征(global feature)时使用对称函数g(max pool)。网络支持分类和分割任务,对于分类任务来说,就是输出整个点云的类别,而分割任务则是输出点云中每一个点的分类结果。PointNet在这两种任务中都取得了很好的结果。
PointNet的实验是非常详细的,其中个人对其中一个实验非常感兴趣,就是输入网络中的所有的点只输出了一个1*1024的全局特征向量,所以说只有不到1024个关键点的特征使用到了,而论文对全局特征进行了反求,找出了是哪些关键点的特征构成了这个全局向量,并将这些点绘制了出来,如图6。
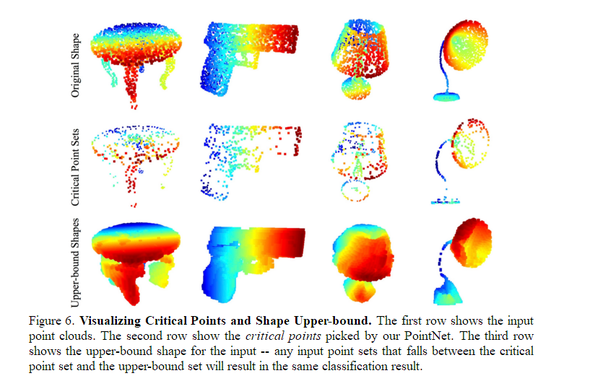 图6:关键点可视化(来源:[4])
图6:关键点可视化(来源:[4])
PointNet++[6]
虽然PointNet在分类和分割任务上都取得了很好的结果,但是论文指出PointNet存在着非常明显的缺点,那就是PointNet只使用了全局的点云特征,而没有使用局部点附近的特征信息,为了解决这个问题,PointNet++在网络中加入了局部信息提取的方案,并且取得了更好的结果。
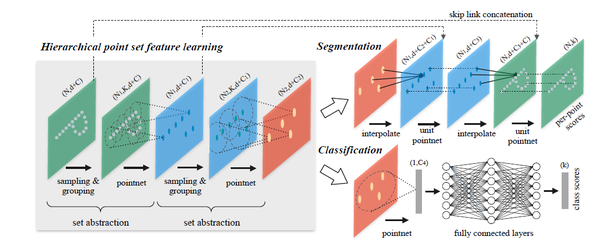 图7:PointNet++网络架构(来源:[6])
图7:PointNet++网络架构(来源:[6])
网络最主要的部分就是图7中的set abstraction部分,它首先是先寻找当前点云中的关键点,然后根据距离信息寻找关键点附近的点构成一个小的点集,最后使用PointNet进行特征求解,。
通过重复上面的set abstraction部分,便可以不断的对局部点云中进行特征提取,可以使网络更好的利用局部信息。并且实验也证明了PointNet++相对于PointNet有了不小的性能提升。当然网络也使用了MSG和MRG的方法来解决当点云密度不均匀时的采样距离需要改变的问题,具体细节可以查看原论文。
虽然PointNet++达到了更好的效果,但是由于网络加入局部信息之后的不再使用T-net,所以PointNet++有时候存在结果不稳定的情况,所以PointNet++的测试结果是对原始点云进行多次旋转求得的平均结果,可见网络还有很大的改进空间。
最近这段时间也陆续出现了很多不错的直接处理点云的深度学习论文,在这里就不一一介绍了,对这个方向有兴趣的同学可以去看看,应该会有很大的帮助,例如:PointCNN,PointSift,Graph CNNs等。
基于二维RGB图像与三维点云学习
Frustrum PointNet[7]
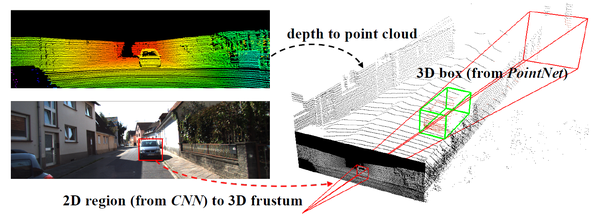 图8:Frustrum PointNet物体定位流程(来源:[7])
图8:Frustrum PointNet物体定位流程(来源:[7])
由于无人驾驶技术的火热,大规模场景物体定位问题一直受到很大的关注,而传统的解决大规模场景物体定位的方法是在整个点云上进行滑动窗口然后对窗口进行物体分类来确定物体的三维边界,但是可想而知这种情况下的计算量太大,很难达到实时预测。
考虑到现在二维深度学习方向的技术已经非常成熟,同时使用RGB和点云信息在大规模三位物体定位中应该可以取得更好的成果,基于这个想法,Frustrum PointNet这篇文章就出现了。
上面图8就是Frustrum PointNet的物体定位的主要流程图,主要包含三个步骤:1)使用二维图像信息以及FPN网络在二维图像上找到物体边界框,2)使用相机的内参数信息将这个二维边界框投射到三维空间,形成一个Frustrum(截椎体),现在就只需要在这个Frustrum里面进行物体搜索,大大减少了搜索时间。3)将PointNet加入了进来,使用PointNet直接对Frustrum中的点云进行物体分割,而不是使用传统的滑动窗口操作,从而使得分割的速度更快。当然,网络还有一些其他的细节处理,比如对Frustrum里的点云进行坐标的变换处理。通过以上的操作,使得论文的方法既鲁棒又迅速,同时在KITTI 以及 SUN RGB-D 检测中取得了更好的性能。
论文当然也存在着一些问题,那就是论文的二维物体定位之后才能进行三维定位,一旦二维出错,那么三维定位也将出现问题,当然这也是基于现在二维定位效果比三维好的情况下设计的。
SPLATNet[8]
 图8:BCL过程(来源:[8])
图8:BCL过程(来源:[8])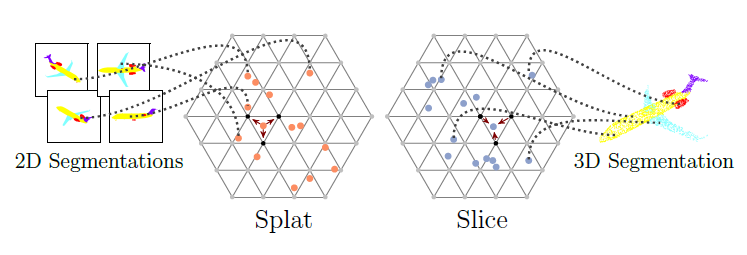 图9:BCL2D->3D过程(来源:[8])
图9:BCL2D->3D过程(来源:[8])
这篇文章使用了一种比较特殊的点云处理方法。文章主要是使用了bilateral convolution layers(BCL)这种网络架构,可以对点云直接进行卷积操作,见图9。
BCL主要有三个基本操作:Splat、Convolve、Slice:Splat是将欧式空间通过使用一个变换矩阵转换成另外一个Permutohedral Lattice空间,并使用插值的方法将点的信息赋值给空间的顶点,从图中可以看出Permutohedral Lattice空间是由多个三角形构成的,分布在平面上,这个空间对于点云这种稀疏无序的数据,能够高效的进行组织和查找,并且方便各种运算的进行,如卷积运算。接下来就是Convolve,这就比较简单了,由于点云已经被投射到这个规格化的空间中,位置是比较规整的,只要按照哈希表做索引,进行卷积操作就可以了。Convolve结束之后使用Slice操作了,这是Splat的逆过程就是把卷积后的Permutohedral Lattice空间上的点的信息转换到原来欧式空间中的点上。
论文另一个吸引人的地方就是BCL2D->3D,可以将从多视图图像中提取的特征利用Permutohedral Lattice投射到三维空间,使得二维图像与点云以一种学习的方法结合在一起,论文也通过这种方法取得了非常好的语义分割性能。
不过由于这篇论文在BCL方面讲解的并不细致,所以要是想要深入了解这方面的的内容的话,需要参考另外论文中的参考文献1和25文献才能真正理解这方面的一些详细内容。
总结
三维方向的深度学习在过去几年里也已经发生了比较大的变化,已经从使用体素网格或者多视角图像转变为了直接使用点云进行学习,并且性能方面也有了很大的提高。不过,这个领域也是近期才快速的发展起来,并且随着三维传感器的进一步普及,这个领域的相关研究会得到更多的关注。而且现在的大规模数据集基本上是关于自动驾驶的,但是可以想象三维深度学习在三维医疗影像、智能机器人等也会发挥很大的作用。
链接:https://zhuanlan.zhihu.com/p/46742217
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。