微软以不断发明新的专有文件格式而闻名,而.pdb文件的程序数据库格式就是其中之一。许多软件开发人员都在拼命寻找关于PDB内部的更多信息。好消息:搜索结束了!本文将PDB格式记录到最后一位,并提供一个Win32实用程序,该实用程序将复合PDB文件拆分为单独的文件。
软件开发和调试工具的编写人员经常面临着显示有关Windows 2000系统模块的符号信息的任务。例如,每个好的反汇编程序都不应该只显示原始的数字和地址,而应该尝试将它们解析为有意义的名称。否则,用户很难弄清楚反汇编代码的实际用途。要采取的第一步(也是最简单的一步)是使用隐藏在被检查模块的可移植可执行文件(PE)文件中的符号信息,以及它通过动态链接引用的所有模块。然而,这些信息并不足以完全理解反汇编代码,因为这些信息只涉及模块之间的接触点。要掌握内部(非导出)函数的语义,首先了解函数的名称通常非常有帮助。还必须知道它调用的从属函数的名称和它访问的全局变量。幸运的是,微软在Windows2000操作系统中以符号文件的形式发布了这些重要信息,这些文件的扩展名是.dbg和.pdb。
.dbg and .pdb Symbol Files
在安装Windows 2000、微软Visual C/C++和平台SDK之后,您仍然会丢失它们,必须在单独的步骤中设置的符号文件。请注意,符号文件必须始终与操作系统的“已更正的服务磁盘”(CSD)级别匹配。也就是说,在每次安装Service Pack和热修复程序之后,也必须始终更新符号文件。通常,符号安装程序会附带新的操作系统文件。安装程序名为symbolsx.exe,符号文件位于关联的存档文件symbols.cab中。首次运行安装程序后,您会发现包含Windows 2000操作系统的硬盘丢失了400MB到500MB的可用空间。默认情况下,符号文件安装在名为Symbols的目录树中,该目录树包含在Windows 2000系统根目录中(例如,C:WINNTSymbols)。
对于每个模块文件扩展名,将创建一个单独的子目录,并且每个系统模块都有两个文件扩展名为.dbg和.pdb的符号文件。如果您以前使用过WindowsNT4.0,您可能会想为什么现在每个Windows2000需要两个符号文件,而不是一个.dbg文件。原因是微软已经将所谓的“公共符号”移动到一个叫做程序数据库(Program Database,PDB)的单独文件中。基本上,PDB文件是由几个独立的流组成的复合文件。您可以将PDB复合文件视为单个文件中的简单平面文件系统,其中的流与文件系统承载的文件相对应。其中一个流包含一系列可变长度的记录,这些记录描述了在关联模块中定义的符号。
在上一个示例中,假定Windows 2000安装在目录C: WINNT中,符号根目录为C: WINNTSymbols,则Windows 2000内核模块ntoskrnl.exe的符号文件将安装为C: WINNTSymbolsexe toskrnl.dbg和C: WINNTSymbolsexe toskrnl.pdb。同样,ntdll.dll符号文件的路径将是C: WINNTSymbolsdll tdll.dbg和C: WINNTSymbolsdll tdll.pdb。这些文件的主要目的之一是允许调试器或反汇编程序查找可归属于模块中给定二进制地址的最近符号名。例如,如果反汇编程序发现要显示的下一个汇编语言指令是call72A05A2Eh,那么最好为用户提供与函数入口点0x72A05A2E相关联的实名,例如call_pMemAlloc@4。
PDB文件布局全局
在本文中,我将介绍更一般的任务,即解析PDB文件并将其分解为各个部分,而不考虑其各种流的内容。这里提供的示例应用程序是一个简单的Win32控制台模式程序,它期望PDB文件的路径,并将其组成部分存储在单独的文件中。根据命令行中指定的选项开关,可以提取以下信息:
- PDB文件头,包含有关文件的一般信息
- 分配位表,指定文件的哪些部分正在使用
- 根流,包含有关所有数据流的特定信息
- 根流中列出的所有数据流
PDB文件最基本的结构属性是将其细分为大小相等的页面。最常用的页面大小是1KB(1024字节),但我的研究表明2K和4K页面也是合法的。(可以通过检查Microsoft的dbghelp.dll如何处理PDB文件来验证这一点。)PDB流是包含一致信息的文件页序列。流最基本的特性是它的页面可以按任意顺序位于文件中的任何位置。
当一个流被读或写时,流目录负责告诉应用程序哪些页面需要按哪个顺序访问。此目录本身存储在名为根流的流中。此外,嵌入的分配位表会跟踪已使用和未使用的页。由于流的重新排列,一旦PDB文件中出现“洞”,此表就必不可少。如果流被重写到PDB文件的末尾,释放它之前占用的页,则分配位表反映在使用新页时前页是空闲的。该方案是从简单的操作系统(如MS-DOS)及其胖文件系统借鉴而来的,其中有一个类似的表指定将哪些磁盘扇区分配给文件。
下图显示了1-KB、2-KB和4-KB模式下PDB文件的典型基本布局。应该使用哪个页面大小取决于要存储在流中的数据。如果页面大小增加,分配位表和根流就会变小。另一方面,较大的页面大小会导致更多的页面悬置;也就是说,如果流大小不是页面大小的确切倍数,则会浪费更多的文件字节。同样的问题也出现在文件系统中,在文件系统中,必须正确选择磁盘扇区大小,以避免过度的扇区挂起。大多数PDB文件,如Windows 2000符号文件和微软Visual C/C++ 6所生成的调试信息,都采用1-KB方案,如下图左侧所示。
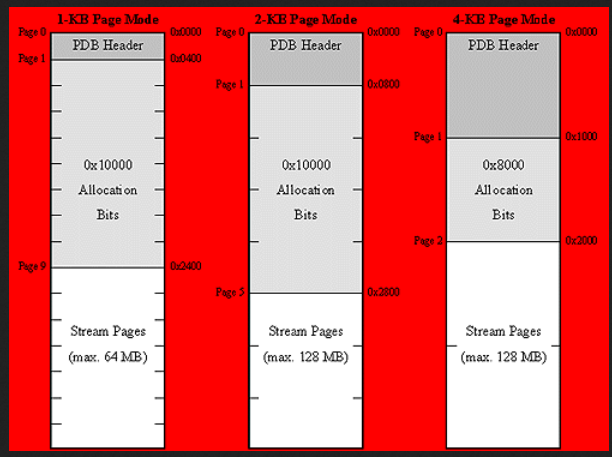
在1-KB页面模式下,PDB文件中最多可以存储64MB,这只是将分配位的数量乘以页面大小的结果。稍后我将展示,PDB页码存储为基于零的16位数量。因此,分配位表永远不会包含超过0[ts]10000位(8KB)。
PDB头总是占据第一个文件页,后面跟着一个或多个包含分配位的页。头的结构定义如清单1所示。前44个字节组成ID字符串PDB_SIGNATURE_200,指定文件类型和版本。撰写本文时,最新版本为2,这是Windows 2000符号文件和Visual C/C++调试信息所使用的版本。dPageSize成员指示应用于文件中所有页的页大小,wStartPage是分配位之后的第一个数据页的从零开始的页码。分配位表的大小始终可以通过从wStartPage中减去1(对于头页)并将结果乘以dPageSize来计算。wFilePages成员指定PDB文件中存储的页数,并且应该始终与文件大小(字节)除以页面大小相匹配。
Listing 1PDB File Header
#define PDB_SIGNATURE_200 "Microsoft C/C++ program database 2.00 x1AJG�" #define PDB_SIGNATURE_ 44 // size of signature (bytes) // ----------------------------------------------------------------- typedef struct _PDB_HEADER { BYTE abSignature [PDB_SIGNATURE_]; // PDB_SIGNATURE_200 DWORD dPageSize; // 0x0400, 0x0800, 0x1000 WORD wStartPage; // 0x0009, 0x0005, 0x0002 WORD wFilePages; // file size / dPageSize PDB_STREAM RootStream; // stream directory WORD awRootPages []; // pages containing PDB_ROOT } PDB_HEADER, *PPDB_HEADER, **PPPDB_HEADER;
RootStream成员是PDB_STREAM类型的另一个未记录的结构,如清单2所定义。这个结构出现在定义流的任何地方。这里,它指的是根流,其中包含文件中数据流的大小和位置。稍后,我们将在遍历根流中的数据流列表时重新访问它。在处理磁盘上的PDB文件时,只有PDB_流结构的dStreamSize成员感兴趣。pwStreamPages成员显然可以用作PDB读/写实用程序的草稿行,这些实用程序处理虚拟内存中的PDB信息。只需忽略这个值,因为它可能是一个假的地址,以前是有效的。
root stream结构后面紧跟着一个由根流使用的16位页码组成的数组。到目前为止,我看到的大多数PDB根流都不超过一个页面,因此awRootPages[]数组通常只包含一个条目。一个例外是ntoskrnl.exe的超大符号文件,它的根流跨越两个页面。
Listing 2 The Basic PDB Stream Structure
typedef struct _PDB_STREAM { DWORD dStreamSize; // in bytes, -1 = free stream PWORD pwStreamPages; // array of page numbers } PDB_STREAM, *PPDB_STREAM, **PPPDB_STREAM;
分配位不需要太多解释。每个位都与一个单独的页相关联,值为1表示对应的页当前可用。字节内的位按从最低有效位到最高有效位的顺序排列。也就是说,字节0的位0表示页0,字节0的位1表示页1,依此类推。注意,磁盘上PDB镜像的分配位不一定反映存储的数据流页的状态。如果检查两个Windows 2000符号文件,您将很快发现某些数据流页位于标记为“空闲”的页中,而某些标记为“正在使用”的页不是任何流的一部分。因此,分配表可能由PDB读写器从根流中的数据重建,并且只有在加载到虚拟内存中时才具有有意义的内容。
扫描根流
一旦找到组成根流的页面,就可以轻松访问数据流目录。根流由两个主要部分组成:
- 一个PDB_ROOT结构形式的可变长度头,如清单3所示
- 16位零基页码数组
PDB_ROOT结构的wCount成员声明存储的数据流的数量,因此定义aStreams[]数组中PDB_STREAM项的数量。清单3末尾的PDB_ROOT__()宏是一个方便的速记符号,用于计算给定数据流数量的根流头的总体大小。Windows 2000 PDB符号文件包含八个流,因此它们的头大小为4+(8*(4+4))=68字节。
Listing 3 PDB Root Stream Structure
typedef struct _PDB_ROOT { WORD wCount; // < PDB_STREAM_MAX WORD wReserved; // 0 PDB_STREAM aStreams []; // stream #0 reserved for stream table } PDB_ROOT, *PPDB_ROOT, **PPPDB_ROOT; #define PDB_ROOT_ sizeof (PDB_ROOT) #define PDB_ROOT__(_n) (PDB_ROOT_ + ((_n) * PDB_STREAM_))
页码数组紧跟在页眉之后。这种设计的一个问题是,不能随机访问数据流,因为根流没有在数组中指定数据流的起始索引。要定位与第三个流相关联的页码,您必须根据前两个流相对于当前PDB页大小的流大小计算它们占用的页数。这就是PDB_STREAM结构的pwStreamPages(见清单2)的用武之地——PDB文件处理器在将PDB数据加载到虚拟内存后只需要查找一次页码子集,并且可以设置每个流的pwStreamPages成员以指向其在数组中的第一个页码。请注意,这只是此结构成员可能的用途之一,而不一定是Microsoft为其设计的用途。
故事的其余部分很快就讲出来了:阅读任何感兴趣的数据流,就像之前阅读根流一样(也就是说,沿着页码列表走下去,然后通过将页码乘以页面大小来查找每个页面)。这不奇怪吗?尽管乍一看PDB文件格式看起来相当复杂,但经过仔细检查,它实际上处理起来相当简单。您只需要一个子例程,它接受一个页码数组,并连接它引用的所有页面。在剩下的部分中,我将展示一个PDB文件处理器的示例实现,它只做了这些工作。
分解PDB文件
示例“PDB File Exploder”w2k_pdbx.exe是一个基本的Win32控制台模式实用程序,它执行以下处理步骤:
- 首先,它分配一个足够大的虚拟内存块来保存整个PDB文件数据,并将文件从磁盘复制到内存。
- 在尝试任何解释之前,数据必须经过一个简单的验证测试,由清单4中的PdbValid()函数执行。给定一个指向内存块的指针,该内存块应该以PDB廑u头结构(函数参数pph)和从文件中读取的字节数(函数参数dData)开头,该函数首先确保至少有足够的空间用于完整的PDB廑u头结构。否则,访问其任何成员都可能导致异常。接下来,验证PDB V2.00签名的存在。最后,PdbValid()计算由页面计数和页面大小指示的数据字节数,并将结果与文件大小相匹配。当然,这个测试是非常原始的——一个好的PDB阅读器还应该考虑验证头部和根流中的所有页码是否在正确的范围内。
- 根据用户提供的命令开关,该实用程序将PDB文件的主要组件写入单独的文件。它识别选项h(提取头)、a(提取分配位)、r(提取根流)和d(提取数据流)。命令行可以包括多个PDB文件路径,对于每个文件,可以通过在选项ID前面加上加号或减号来打开或关闭这四个选项。例如,命令w2k_pdbx+hardD:WINNTsymbol sexe toskrnl.pdb将提取隐藏在Windows 2000内核符号文件中的所有有效pdb数据。
Listing 4 Simple PDB Sanity Check
BOOL PdbValid (PPDB_HEADER pph, DWORD dData) { return (pph != NULL) && (dData >= PDB_HEADER_) && (!lstrcmpA (pph->abSignature, PDB_SIGNATURE_200))&& ((DWORD) pph->wFilePages * pph->dPageSize == dData); }
如果指定了+h选项,则保存PDB_头部分,包括所有有效的根流页码。在这种情况下,w2k_pdbx.exe只需将第一个PDB页写入磁盘。如果假设有一个奇怪的场景,其中有65536个零长度数据流,那么根流的大小将是524292字节,或者在1KB模式下是513页。由于每个页码在头的awRootPages[]数组中占16位,因此头的大小显然将超过1024字节。如果数据流不是空的,情况会变得更糟。坦白地说,我现在不知道微软PDB工具是如何处理这个特殊情况的。但是,我怀疑你在现实生活中是否会遇到这样一个病态的文件。
代表+a选项保存分配位也非常简单。位数组所占用的页数由PDB_HEADER头的wStartPage成员减去1给出,再次假设头不超过一页限制。提取根流(command option+r)需要更多的工作,因为程序必须首先找出根流的大小。这种计算并不简单,因为大小取决于数据流的数量和大小,而且必须考虑根流可能跨越不一定连续的多个页面。清单5显示了一个可能的迭代解决方案。函数的作用是:使用一个三步近似过程来确定字节的确切大小,并将数据复制到一个连续的内存块中。
Listing 5 Copying the Root Stream
PPDB_ROOT PdbRoot (PPDB_HEADER pph, PDWORD pdBytes) { DWORD dBytes, i, n; PPDB_ROOT ppr = NULL; if ((ppr = PdbRead (pph, PDB_ROOT_, pph->awRootPages)) != NULL) { dBytes = PDB_ROOT__ ((DWORD) ppr->wCount); free (ppr); if ((ppr = PdbRead (pph, dBytes, pph->awRootPages)) != NULL) { for (n = i = 0; i < (DWORD) ppr->wCount; i++) { n += PdbPages (pph, ppr->aStreams [i].dStreamSize); } dBytes += n * sizeof (WORD); free (ppr); ppr = PdbRead (pph, dBytes, pph->awRootPages); } } *pdBytes = (ppr != NULL ? dBytes : 0); return ppr; }
- 第一种近似是基于这样一个事实:根流从PDBúu根结构的固定大小部分开始,该部分始终适合于单个页面。因此,PdbRoot()使用清单6中定义的通用PdbRead()函数加载第一个根流页面。PdbRead()是w2k_pdbx.exe实用程序的一种工作程序,它将页面从PDB内存映像复制到一个连续的内存块,给定一个页码数组和要复制的字节数。它依赖于清单6顶部的PdbPages()函数,该函数根据流大小(字节)和当前页面大小计算流页面的数量。
- 在步骤2中,PDB ROOT()可以计算PDB_根结构的大小,包括所有astream[]条目,但不包括以下页码数组。虽然不太可能,但这些数据可能已经超过一页。在1KB页面模式下,只要流目录包含128个或更多数据流,就会发生这种情况。然而,PdbRead()来拯救它,并在内存中构建一个忠实且连续的副本。
- 现在,PDB_根结构的整个PDB_流数组都在内存中,通过将每个数据流占用的页数相加,很容易找出根流的总体大小,从而得到PDB_根数据之后所需的页数数组的大小。同样,PdbRead()用于将所有根流页面重新洗牌到新分配的内存块中。
Listing 6 Joining Stream Pages In a Contiguous Memory Block
DWORD PdbPages (PPDB_HEADER pph, DWORD dBytes) { return (dBytes ? (((dBytes-1) / pph->dPageSize) + 1) : 0); } // ----------------------------------------------------------------- PVOID PdbRead (PPDB_HEADER pph, DWORD dBytes, PWORD pwPages) { DWORD i, j; DWORD dPages = PdbPages (pph, dBytes); PVOID pPages = malloc (dPages * pph->dPageSize); if (pPages != NULL) { for (i = 0; i < dPages; i++) { j = pwPages [i]; CopyMemory ((PBYTE) pPages + (i * pph->dPageSize), (PBYTE) pph + (j * pph->dPageSize), pph->dPageSize); } } return pPages; }
到现在为止,我们差不多完成了。一旦根流被组装到内存中,保存数据流几乎是微不足道的。正如您可能已经猜到的,PdbRead()函数再次完成了这项艰巨的工作。清单7显示了PdbStream()函数,该函数生成由基于零的数据流索引标识的数据流的虚拟内存副本。在调用PdbRead()之前,该函数通过循环流目录查找与请求流相关联的页码子数组,并将此指针作为其第三个参数传递给PdbRead()。PdbStream()通过其输出参数pdBytes返回流的大小。
Listing 7 Copying Data Streams
PVOID PdbStream (PPDB_HEADER pph, PPDB_ROOT ppr, DWORD dStream, PDWORD pdBytes) { DWORD dBytes, i; PWORD pwPages; PVOID pPages = NULL; if (dStream < (DWORD) ppr->wCount) { pwPages = (PWORD) ((PBYTE) ppr + PDB_ROOT__ ((DWORD) ppr->wCount)); for (i = 0; i < dStream; i++) { pwPages += PdbPages (pph, ppr->aStreams [i].dStreamSize); } dBytes = ppr->aStreams [dStream].dStreamSize; pPages = PdbRead (pph, dBytes, pwPages); } *pdBytes = (pPages != NULL ? dBytes : 0); return pPages; }
如果w2k_pdbx.exe实用程序在没有任何命令参数的情况下运行,它将显示示例1中所示的帮助屏幕。默认情况下,各种输出文件都会写入当前目录。但是,可以通过显式指定目标目录来重写此设置。这可以是带或不带尾随反斜杠的相对或绝对路径。无论如何,该目录必须存在,并且路径规范必须以斜杠字符作为前缀。
Example 1: The w2k_pdbx.exe Command Help Screen
D: mp>w2k_pdbx // w2k_pdbx.exe // SBS Program Database Exploder V1.00 // 07-07-2001 Sven B. Schreiber // sbs@orgon.com Usage: w2k_pdbx { [+-hard] [/<target>] <PDB path> } + enable subsequent options - disable subsequent options h extract header a extract allocation bits r extract root stream d extract data streams Target paths: +h <target><PDB file>.header +a <target><PDB file>.alloc +r <target><PDB file>.root +d <target><PDB file>.<###> <###> = 0-based stream number. If /<target> is omitted, the files are written to the current directory.
示例2是w2k_pdbx.exe实用程序的另一个示例运行,这次指定了所有可用选项(+h、+a、+r和+d)以及命令行上ntoskrnl.exe符号文件的路径。在写入输出文件之前,w2k_pdbx.exe显示从文件头和根流提取的PDB文件属性的摘要。
Example 2: Parsing the ntoskrnl.exe Symbol File
w2k_pdbx +hard e:winntsymbolsexe toskrnl.pdb // w2k_pdbx.exe // SBS Program Database Exploder V1.00 // 07-07-2001 Sven B. Schreiber // sbs@orgon.com Properties of "e:winntsymbolsexe toskrnl.pdb": 67108864 bytes maximum size 738304 bytes allocated 706239 bytes used by 8 data streams 1456 bytes used by the root stream 1024 bytes per page 721 pages allocated 694 pages used by 8 data streams 2 pages used by the root stream Saving "ntoskrnl.pdb.header"... 1024 bytes Saving "ntoskrnl.pdb.alloc"... 8192 bytes Saving "ntoskrnl.pdb.root"... 1456 bytes Saving "ntoskrnl.pdb.000"... 1456 bytes Saving "ntoskrnl.pdb.001"... 58 bytes Saving "ntoskrnl.pdb.002"... 56 bytes Saving "ntoskrnl.pdb.003"... 262825 bytes Saving "ntoskrnl.pdb.004"... 0 bytes Saving "ntoskrnl.pdb.005"... 16388 bytes Saving "ntoskrnl.pdb.006"... 106164 bytes Saving "ntoskrnl.pdb.007"... 319292 bytes
示例代码存档
上面清单中没有包含的w2k_pdbx.exe中的代码或多或少属于样板类型。分析命令行,计算选项开关,最后调用清单4-7中的函数。如果你对这些血腥细节感兴趣,点击这里下载示例代码存档,并查看源文件W2KYPDPBX.C和W2KYPDPBX.H。这个ZIP存档包含所有需要编译的项目文件,并将代码与微软Visual C/C++ 6链接。