通过zabbix自带模板监控windowsPC机器
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
欢迎加入:高级运维工程师之路 598432640
相信有很多跟我一样的朋友,对zabbix会搭建,就是不会配置,在这里我要感谢我的朋友曹艳飞,他帮助我如何去使用模板,我也会举一反三的去套用别的模板了,我把他给我共享的整理了一下文档,供大家参考。
客户端配置
一.首先配置好客户端,建议参考我的另外一片链接,那里面详细介绍了如何配置客户端,我就不用在这里反复强调了http://www.cnblogs.com/yinzhengjie/p/6140966.html
服务端配置(基本上都是图形说明)
一 .找到zabbix自带的模板
1.点击自动发现
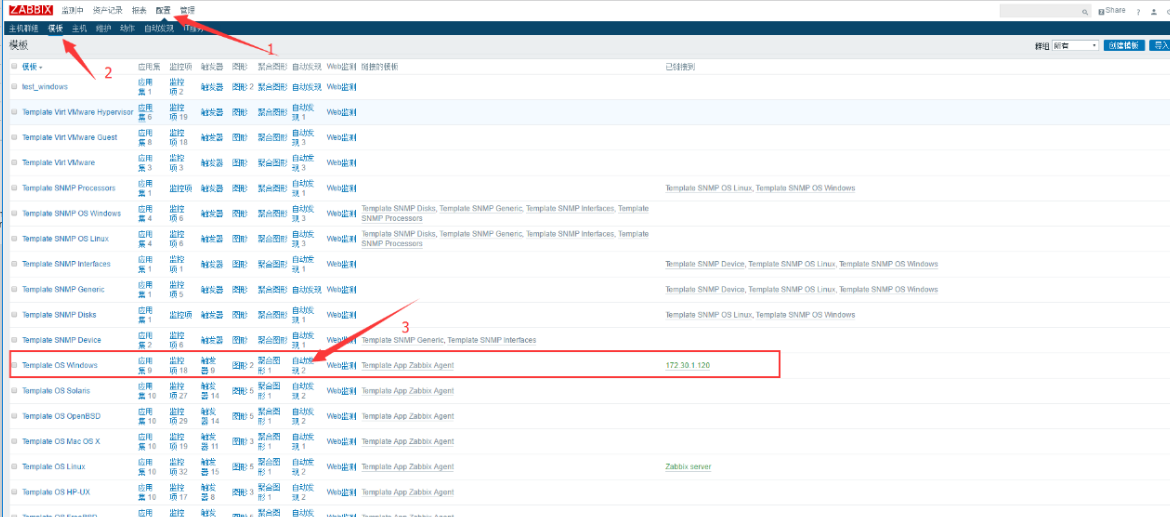

2.查看自动发现规则


3.将发现时间修改成1分钟,(这里我们是测试,生产环境中不要这么干~对服务器会有负担,尤其是规模比较大的公司)点击更新。将上面2个自动发现规则时间都要改哟


既然有现成的模板,我们需要做的就是直接link对应的主机就好~批量部署再好不过了。
4.创建主机




5.link模板,点击添加即可

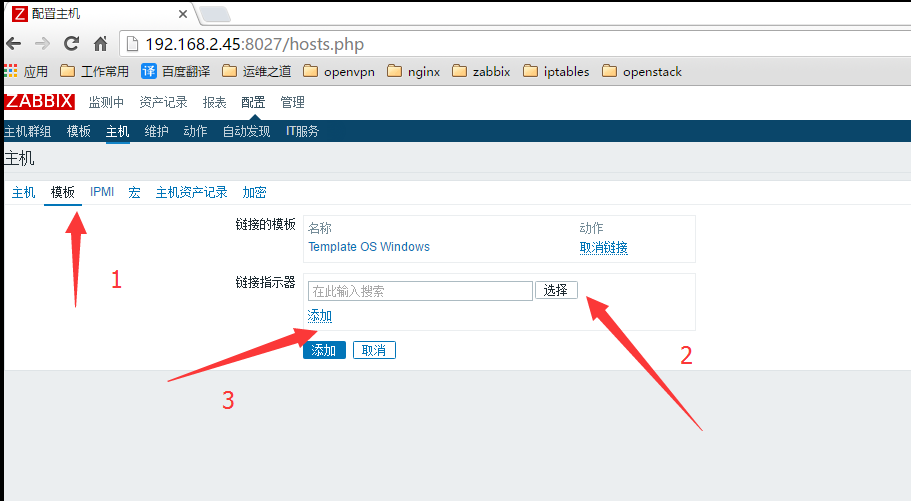
6.配置完毕后建议刷新一下主页


7.查看图像,默认监控4个方向(磁盘使用情况,CPU负载,内存使用情况,网卡流量【注意,这里的网卡可不止一张哟,他包含了你所有的适配器,包括虚拟的网卡】)

好了,至于怎么链接linux的相信大家也会玩了吧~方法是一样的~

后记:
不过通过实验结果大家有看到了,系统自带的监控根本就无法满足我们的需求,比如我们对服务的监控,对磁盘的健康状态的监控等等。那么如何实现对这些的监控呢?欢迎zabbix大神为我们指点迷经,
让我们少走弯路!欢迎加入:高级运维工程师之路 598432640