Hadoop基础-MapReduce的工作原理第一弹
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识将为我们随后学习写MapReduce高级编程奠定基础。
一.剖析MapReduce作业运行机制
MapReduce是hadoop的编程模型,它的核心思想就是映射(Map)和化简(Reduce)。
1>.作业的提交
可以通过一个简单的方法调用来运行MapReduce作业:Job对象的submit() 方法。注意,也可以调用waitForCompletion(),它用于提交过的作业,并等待它的完成。submit()方法调用封装了大量的处理细节,稍后我们就会揭示Hadoop运行作业时锁采取的措施。
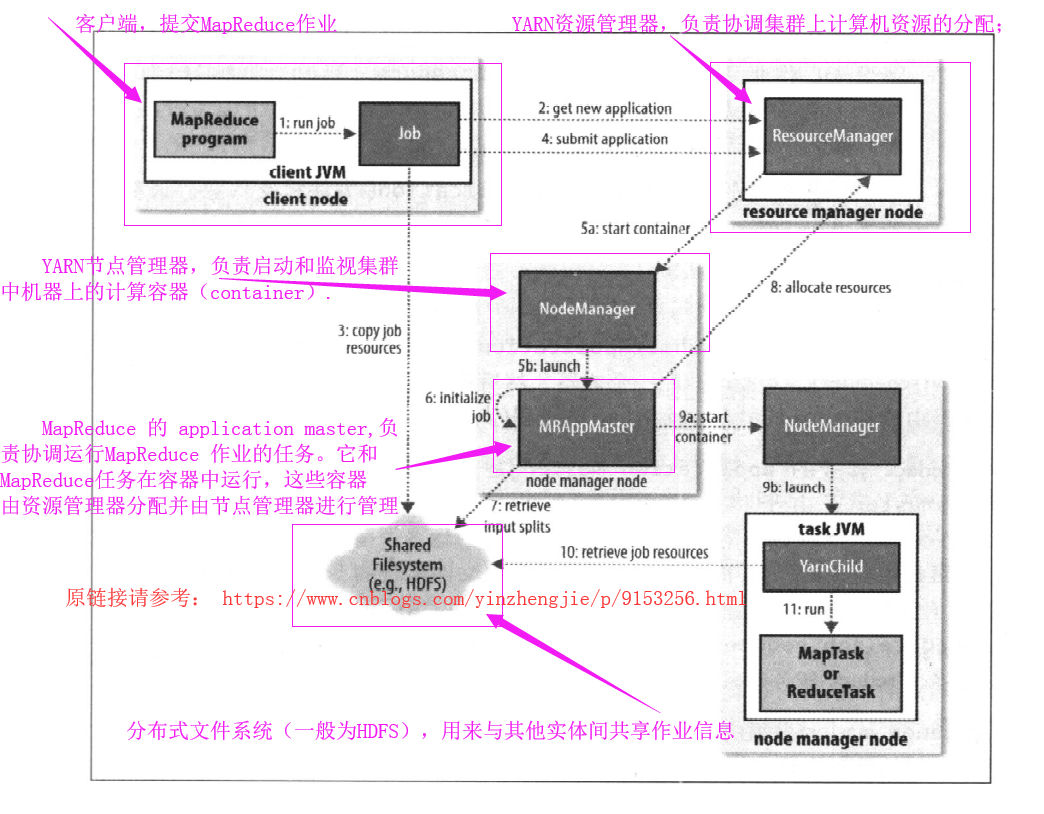
整个过程描述如上图所示,在最高层有以下5个独立的实体:
a>.客户端,提交MapReduce作业;
b>.YARN资源管理器,负责协调集群上计算机资源的分配;
c>.YARN节点管理器,负责启动和监视集群中机器上的计算容器(container);
d>.MapReduce 的 application master,负责协调运行MapReduce 作业的任务。它和MapReduce任务在容器中运行,这些容器由资源管理器分配并由节点管理器进行管理;
e>.分布式文件系统(一般为HDFS),用来与其他实体间共享作业信息;
2>.作业的初始化
资源管理器收到调用它的submitApplication()消息后,便将请求传递给YARN调度器(scheduler)。调度器分配一个容器,然后资源管理器在节点管理器的管理下在容器中启动application master 的进程(上图中的5a和5b)。
MapReduce作业的application master是一个Java应用程序,它的主类是MRAPPMaster。由于将接受来自任务的进度和完成报告(步骤6),因此application master对作业的初始化通过创建多个簿记对象以保持对作业进度的跟踪来完成的。接下来,它接受来自共享文件系统的,在客户端计算的输入分片(步骤七)。然后对每一个分片创建一个map任务对象以及由mapreduce.job.reduces属性(通过作业的setNumReduceTasks() 方法设置)确定的对多个reduce任务对象。任务ID在此时分配。
application master 必须决定如何运行构成MapReduce作业的各个任务。如果作业很小,就选择和自己在同一个JVM上运行任务。与在一个个节点上顺序运行这些任务相比,当application master 判断在新的容器中分配和运行任务的开销大于并行运行它们的开销时,就会发生一这一情况。这样的作业称为uberized,或者作为uber任务运行。
那个作业是小作业?默认情况下,小作业就是少于10个mapper且只有一个reduce且输入大小小于一个HDFS块的作业(通过设置mapreduce.job.ubertask.maxmaps,mapreduce.job.ubertask.maxreduces和mapreduce.job.ubertask.maxbytes可以改变这几个值)。必须明确启用Uber任务(对于单个作业,或者是对整个集群),具体方法是将mapreduce.job.ubertask.enble设置为true。
最后,在任何任务运行之前,application master 调用setupJob() 方法设置OutputCommitter。FileOutputCommitter为默认值,表示将建立作业的最终输出目录及任务输出的临时工作空间。
3>.任务的分配
如果作业不适合作为uber任务运行,那么application master就会为该作业中的所有map任务和reduce任务向资源管理器请求容器(步骤8)。首先为Map任务发出请求,该请求优先级要高于reduce任务的请求,这是因为所有的map任务必须在reduce的排序阶段能够启动前完成,直到有5%的map任务已经完成时,为reduce任务的请求才会发出。
reduce任务能够在集群中任务位置运行,但是map任务的请求有着数据本地化局限,这也是调度器锁关注的。在理想情况下,任务是数据本地化的(data local),意味着任务在分片驻留的同一节点上运行。可选的情况是,任务可能是机架本地化(rack local)的,即和分片在同一机架二分同一节点上运行。有一些任务既不是数据本地化,也不是机架本地化,它们会从别的机架,而不是运行所在的机架上获取自己的数据。对于一个特定的作业运行,可以通过查看作业计数器来确定在每个本地化层次上运行的任务的数量。
请求也为任务制定了内存需求和CPU数。在默认情况下,每个map任务和reduce任务都分配到1024MB的内存和一个虚拟的内核,这些值可以在每个作业的基础上进行配置,分别通过5个属性来设置,即“mapreduce.map.memeory.mb”,"mapreduce.reduce.memory.mb","mapreduce.map.cpu.vcores"和“mapreduce.reduce.cpu.vcoresp.memory.mb”。
4>.任务的执行
一旦资源管理器的调度器为任务分配一个特定节点上的容器,application master就通过与节点管理通信来哦启动容器(步骤9a和9b)。该任务由主类为YarnChild的一个Java应用程序执行。在它运行任务之前,首先将任务需要的资源本地化,包括作业的配置,JAR文件和所有来自分布式缓存的文件(步骤10)。最后,运行map任务或reduce任务(步骤11)。
YarnChild在指定的JVM中运行,因此用户定义的map或reduce函数(甚至是YarnChild)中的任何缺陷不会影响到节点管理器,例如导致其崩溃或挂起。
每个任务都能够执行搭建(setup)和提交(cimmit)动作,他们和任务本身在同一个JVM中运行,并由作业的OutputCommitter确定。对于基于文件的作业,提交动作将任务输出由临时位置搬迁到最终位置。提交协议确保当推测执行(speculative execution)被启用时,只有一个任务副本被提交,其它的都被取消。
Streaming运行特殊的map任务和reduce任务,目的是运行用户提供的可执行程序,并与之通信。Streaming任务使用标准输入和输出流与进程(可以用任何语言写)进行通信。在任务执行过程中,Java进程都会把输入键-值对传递给外部的进程,后者通过用户定义的map函数和reduce函数来执行它并把它输出键-值对传回Java进程。从节点管理的角度看,就像其子进程字节在运行map或reduce代码一样。
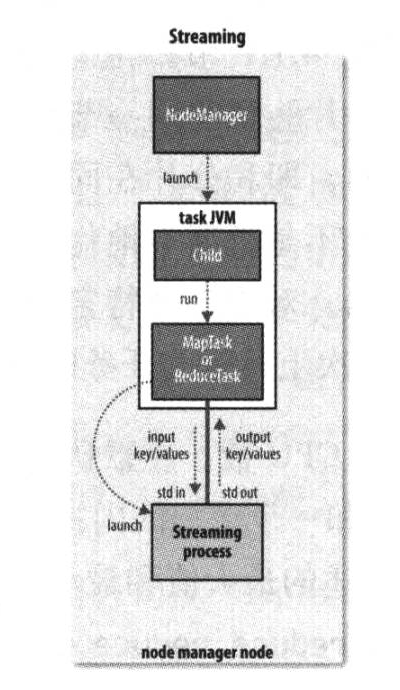
5>.进度和状态的更新
MapReduce作业是长时间运行的批量作业,运行时间范围从秒到小时。这可能是一个很长的时间段,所有对于用户而言,能够得知关于作业进展的一些反馈是很重要的。一个作业和它的每个任务都是一个状态(status),包括:作业或任务的状态(比如:运行中,成功完成,失败),map和reduce的进去,作业计数器的值,状态消息或描述(可以由用户代码来设置)。这些状态信息在作业期间不断改变,他们是如何与客户端通信的呢?
任务在运行时,对其进度(progress,即任务完成执百分比)保持追踪。对map任务,任务进度是已处理输入所占的比例。对reduce任务,情况稍微有点复杂,但系统仍然会估计已处理reduce输入的比例。整个过程分为三部分,与shuffle一般的输入,那么任务的进度便是5/6,这是因为已经完成复制和排序及阶段(每个占1/3),并且已经完成reduce阶段的一半(1/6)。
任务也是一组计数器,负责对任务运行过程中各个时间进行计数,这些计数其要么内置与框架中,例如已写入的map输出记录数,要么有用户自定义。
当map任务或reduce任务运行时,子进程和字节的父application master通过umbilical接口通信。每隔3秒钟,任务通过这个umbilical接口向自己的application master报告进度和状态(包括计数器),application master 会形成一个作业的汇聚试图(aggregate view)。
资源管理器的界面显示了所有运行中的应用程序,并且分别有链接指向这些应用各自的application master 的界面,这些界面展示了MapReduce作业的更多细节,包括其进度。
在作业期间,客户端每秒钟轮询一次 application master 以接受最新状态(轮询间隔通过 mapreduce.client.progressmonitor.pollinterval设置)。客户端也可以使用Job的getStatus()方法得到一个JobStatus的实例,后者包含作业的所有状态信息。对上述描述简单做一个图解如下:
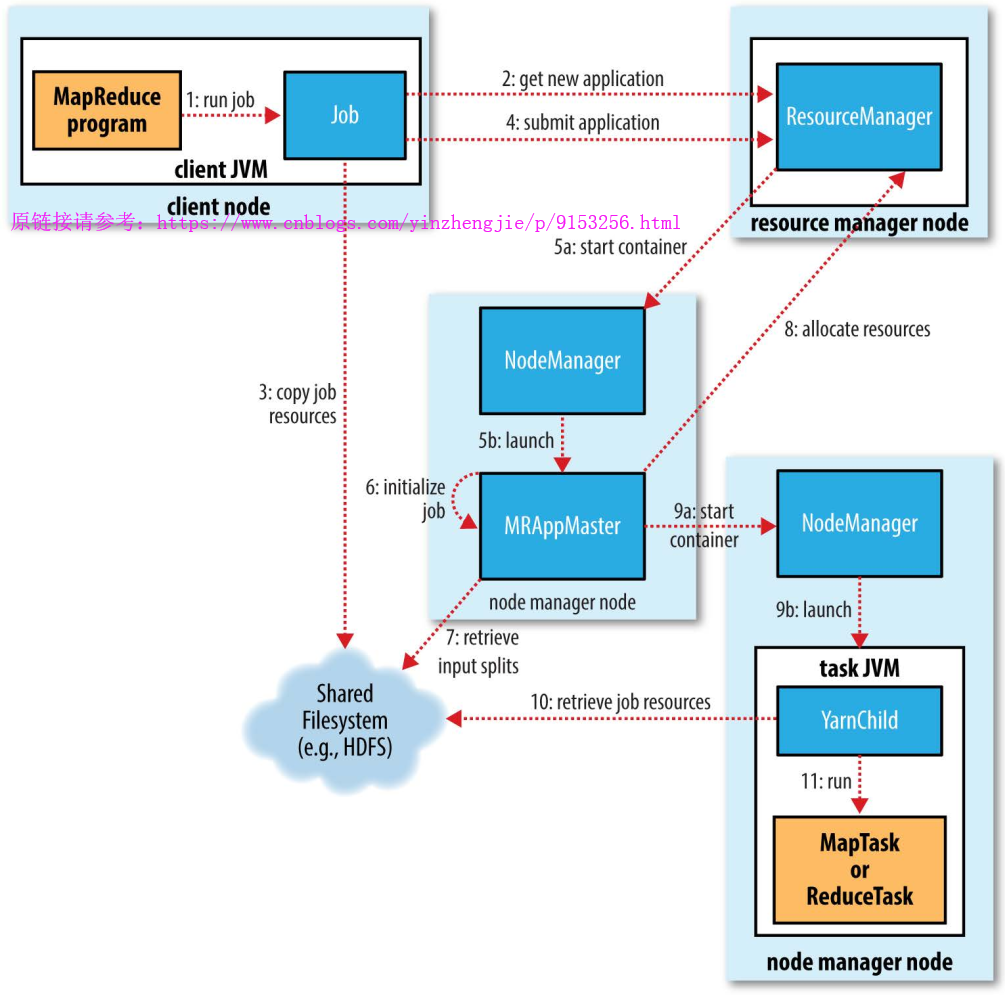
6>.作业的完成
当application master收到作业最后一个任务已经完成的通知后,便把作业的状态设置为“成功”。然后,在Job轮询状态时,便知道任务已成功完成,于是Job打印一条消息告知用户,然后从wairForCompletion()方法返回。Job的统计信息和计数值也在这个时候处处到控制台。
如果application master 有相应的设置,也会发送一个HTTP作业通知。希望收到回调指令的客户端可以通过"mapreduce.job.end-notification.url"属性啦进行这个项设置。
最后,作业完成是,application master 和任务容器清理其工作状态(这样中间输出将被删除),OutputCommitter的commitJob()方法会被调用。作业信息由作业历史服务器存档,以便日后用户需要时可以查询。
二.故障剖析(运行失败)
在现实情况中,用户代码错误不断,进程崩溃,机器故障,如此种种。使用Hadoop最主要的好处之一是它能处理此类故障并让你能够成功完成作业。我们需要考虑以下实体的失败:任务,application master,节点资源管理器和资源管理器。
1>.任务运行失败
首先考虑任务失败的情况。最常见的情况是map任务或reduce任务中的用户代码抛出运行异常。如果发生这种情况,人物JVM会在退出之前向其父application master发送错误报告。错误报告最后被记入用户日志。application master将此次任务尝试标记为failed(失败),并释放容器以便资源可以为其它任务使用。
2>.application master 运行失败
YARN中的应用程序在运行失败的时候有几次尝试机会,就像MapReduce任务在遇到硬件或网络故障时要进行几次尝试一样。运行MapReduce application master的最多尝试次数由MapReduce.am.max-attempts属性控制。默认值是2,即如果MapReduce application master 失败两次,便不会进行尝试,作业将失败。
3>.节点管理器运行失败
如果节点管理器由于崩溃或运行非常缓慢而失败,就会停止向资源管理器发送心跳信息(或发送频率很低)。如果10分钟了内可以通过属性yarn.resourcemanager.nm.livenss-monitor.expiry-interval-ms设置,以毫秒为单位)没有收到一条心跳信息,资源管理器将会通知停止心跳信息的节点管理器,并且将其从自己的节电池中移除以调度启用容器。
4>.资源管理器运行失败
资源资源器失败是非常严重的问题,没有资源管理器,作业和任务容器将无法启动。在默认的配置中,资源管理器是个单点故障,这是由于在机器失败的情况下(尽管不太可能发送),所有运行的作业都失败且不能被恢复。
三.shuffle和排序
MapReduce确保每个reducer的输入都是按键排序的。系统执行排序,将map输出作为输入传给reducer的过程称为shuffle(事实上,shuffle这个说法并不准确。因为在某些语境中,它只代表reduce任务获取map输出的这个部分过程)。在此,我们将学习shuffle是如何工作的,因为它有助于我们理解工作机制(如果需要优化MapReduce程序)。shuffle属于不断被优化和改进的代码库的一部分,因此下面的描述有必要隐藏一些细节。从许多方面来看,shuffle是MapReduce的“心脏”,是奇迹发送的地方。
1>.Map端
map函数开始产生输出时,并不是简单的将它写到磁盘吗。这个过程更复杂,他利用缓冲的方式写到内存并处于效率的考虑进行预排序。如下图所示:
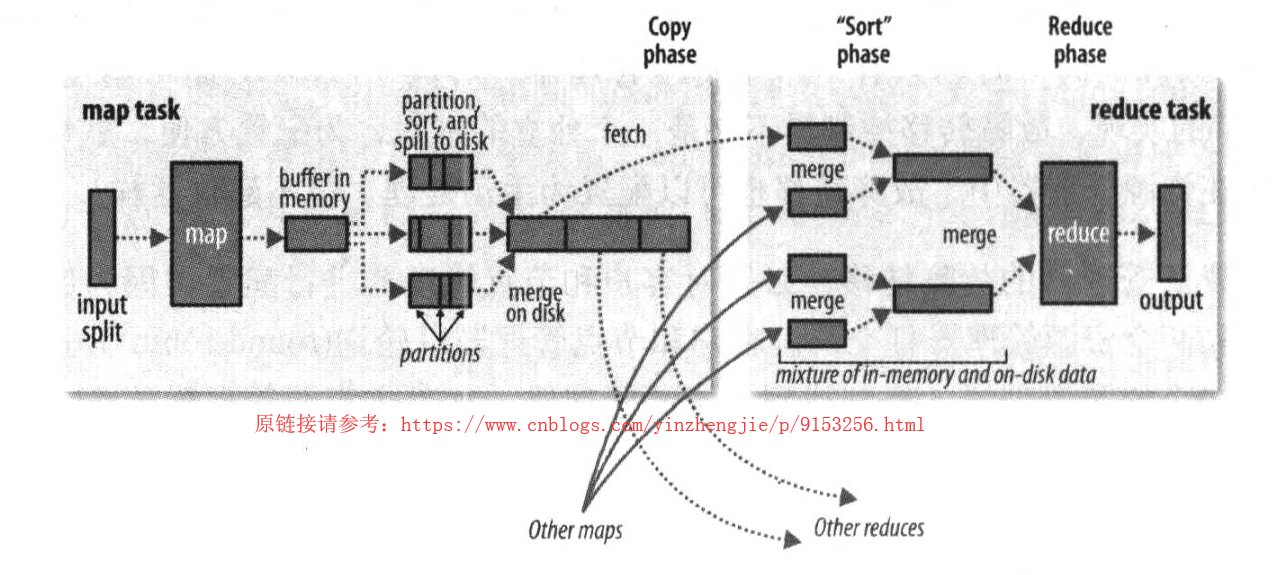
每个map任务都有一个环形内存缓冲区用于存储任务输出。在默认情况下,缓冲区的大小为100MB,这个值可以通过改变mapreduce.task.io.sort.mb属性来调整。一旦缓冲区内容达到阈值(mapreduce.mao.sort.spill.percent,在默认情况下,缓冲区的大小为100MB,这个值可以通过改变mapreduce.map.sort.spill.percent,默认为0.80,或者80%),一个后台线程便开始把内容溢出(spill)到磁盘。在溢出写到磁盘过程中,map输出继续写到缓冲区,但如果在此期间缓冲区被填满,map会被阻塞直到写磁盘过程完成。溢出写过程按轮询方式将缓冲区的内容写到mapreduce.cluster.local.dir属性在作业特定子目录下指定的目录中。
在写磁盘之前,线程首先根据数据最终要传的reducer把数据划分成相应的分区(partition)。在每个分区中,后台线程按键进行内存中排序,如果有一个combiner函数,它就在排序后的输出上运行。运行combiner函数使得map输出结果更紧凑,因此减少写到磁盘的数据和传递给reducer的数据。
每次内存缓冲区到溢出阈值,就会新建一个溢出文件(spill file),因此在map任务写完其最后一个输出记录之后,会有几个溢出文件。在任务完成之前, 溢出文件被合并成一个已分区且已排序的输出文件。配合mapreduce.task.io.sort.factor控制着依次最多合并多少流,默认值是10.
如果至少存在3个溢出文件(通过mapreduce.map.combine.minspills属性设置)时,则combiner就会在输出文件写到磁盘之前再次运行。前面曾将见过,combiner可以在输入上反复运行,但并不影响最终结果。如果只有1或2个溢出文件,那么由于map输出规模减少,因而不指的调用commbiner带来的开销,因此不会为该map输出再次运行combiner。
在将压缩map输出的写到磁盘的过程中对它进行压缩往往是个很好的注意,因为这样写磁盘的速度更快,节约磁盘空间,并且减少传给reducer的数据量。在默认情况下,输出是不压缩的,但只要将mapreduce.map.output.compress设置为true,就可以轻松启用此功能。使用的压缩库由mapreduce.map.output.compress.codec指定,要想进一部了解压缩格式,请参考:https://www.cnblogs.com/yinzhengjie/p/9124038.html
reducer通过HTTP得到输出文件的分区。用于文件分区的工作线程的数量有任务的mapreduce.shuffle.max.threads属性控制,此设置针对的是每一个节点管理器,而不是针对每个map任务。默认值0将最大线程数设置为机器中处理器数据的两倍。
2>.Reduce端
现在转到处理过程的reduce部分。map输出文件位于运行map任务的tasktracker的本地磁盘(注意,尽管map输出经常写到map tasktracker的本地磁盘,但reduce输出并不这样),现在,tasktracker需要为分区文件运行reduce任务。并且,reduce任务需要集群上若干个map任务的map输出作为其特殊的分区文件。每个map任务的完成时间可能不同,因此在每个任务完成时,reduce任务就开始复制并取得map输出。默认值是5个线程,但这个默认值可以修改设置mapreduce.reduce.shuffle.parallecopies属性即可。
如果map 输出相当小,会被复制到reduce任务JVM的内存(缓冲区大小由mapreduce.reduce.shuffle.input.buffer.percent属性控制,指定用于此用户的堆空间的百分比),否则,map输出被复制到磁盘。一旦内存缓冲区达到阈值大小(由mapreduce.reduce.shuffle.merge.percent 决定)或达到map输出阈值(由mapreduce.reduce.merge.inmem.threshold控制),则合并后溢出写到磁盘中。如果指定combiner,则在合并期间运行它以降低写入磁盘的数据量。
随着磁盘的副本增多,后台进程会将他们合并为更大的,排序好的文件。这回味后面的合并绝对是哪个一些时间。注意,为了合并,压缩的map输出(通过map任务)都必须在内存中被解压。复制玩所有的map输出后,reduce任务进入排序阶段(更强档的说法是合并节点,因为排序是在map端进行的),这阶段 将合并map输出,维持其顺序排序。这是循环进行的。比如,如果有50个map输出,而合并因子是10(10为默认设置,由mapreduce.task.io.sort.factor属性设置,与map的合并相似),合并后将进行5趟。每趟将10个文件合并成一个文件,因此最后有5个中间文件。在最后阶段,即reduce阶段,直接把数据输入reduce函数,从而节省了一次磁盘的往返行程,并没有将这5个文件合并成一个已排序的文件作为最后一趟,最后的合并可以来自内核和磁盘片段。
在reduce阶段,对已排序出中每个键调用reduce函数。此阶段的输出直接写到输出文件系统,一般为HDFS。如果采用HDFS,由于节点管理器也运行数据节点,所以第一个块副本将写到本地磁盘。
四.MapReduce入门-WorldCount实现(windows开发环境)
1>.Map端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.wordcount; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Mapper; 12 13 import java.io.IOException; 14 15 /** 16 * 我们定义的map端类为WordCountMap,它需要继承“org.apache.hadoop.mapreduce.Mapper.Mapper”, 17 * 该Mapper有四个参数,前两个参数是指定map端输入key和value的数据类型,而后两个参数是指定map端输出 18 * key和value的数据类型。 19 */ 20 public class WordCountMap extends Mapper<LongWritable,Text,Text,IntWritable> { 21 22 /** 23 * 24 * @param key : 表示输入的key变量。 25 * @param value : 表示输入的value 26 * @param context : 表示map端的上下文,它是负责将map端数据传给reduce。 27 */ 28 @Override 29 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 30 31 //得到一行数据 32 String line = value.toString(); 33 //以空格切开一行的数据 34 String[] arr = line.split(" "); 35 for (String word:arr){ 36 //遍历arr中的每个元素,并对每个元素赋初值为1,然后在将数据传给reduce端 37 context.write(new Text(word),new IntWritable(1)); 38 } 39 } 40 }
2>.Reduce端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.wordcount; 7 8 import org.apache.hadoop.io.IntWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import java.io.IOException; 12 13 /** 14 * 我们定义的reduce端类为WordCountReduce,它需要继承“org.apache.hadoop.mapreduce.Reducer.Reducer”, 15 * 该Reducer有四个参数,前两个参数是指定map端输入key和value的数据类型,而后两个参数是指定map端输出 16 * key和value的数据类型。 17 */ 18 public class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable> { 19 /** 20 * 21 * @param key : 表示输入的key变量。 22 * @param values : 表示输入的value,这个变量是可迭代的,因此传递的是多个值。 23 * @param context : 表示reduce端的上下文,它是负责将reduce端数据传给调用者(调用者可以传递的数据输出到文件,也可以输出到下一个MapReduce程序。 24 */ 25 @Override 26 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 27 //定义一个单词计数器 28 Integer count = 0; 29 //由于输入端只有一个key,因此value的所有值都属于这个key的,我们需要做的是对value进行遍历并将所有数据进行相加操作,最终的结果就得到了同一个key的出现的次数。 30 for (IntWritable value : values){ 31 //获取到value的get方法获取到value的值。 32 count += value.get(); 33 } 34 //我们将key原封不动的返回,并将key的values的所有int类型的参数进行折叠,最终返回单词书以及该单词总共出现的次数。 35 context.write(key,new IntWritable(count)); 36 } 37 }
3>.App端代码
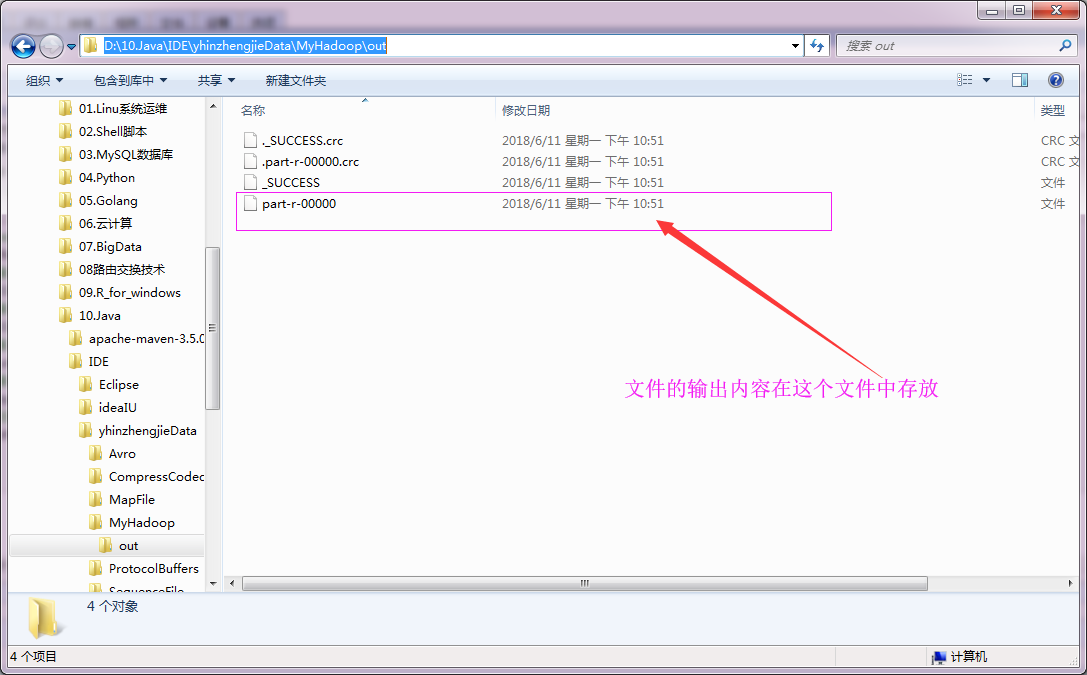
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.mapreduce.wordcount; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.IntWritable; 11 import org.apache.hadoop.io.Text; 12 import org.apache.hadoop.mapreduce.Job; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 16 import java.io.IOException; 17 18 public class WordCountApp { 19 20 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 21 //实例化一个Configuration,它会自动去加载本地的core-site.xml配置文件的fs.defaultFS属性。(该文件放在项目的resources目录即可。) 22 Configuration conf = new Configuration(); 23 //将hdfs写入的路径定义在本地,需要修改默认为文件系统,这样就可以覆盖到之前在core-site.xml配置文件读取到的数据。 24 conf.set("fs.defaultFS","file:///"); 25 //创建一个任务对象job,别忘记把conf穿进去哟! 26 Job job = Job.getInstance(conf); 27 //给任务起个名字 28 job.setJobName("WordCount"); 29 //指定main函数所在的类,也就是当前所在的类名 30 job.setJarByClass(WordCountApp.class); 31 //指定map的类名,这里指定咱们自定义的map程序即可 32 job.setMapperClass(WordCountMap.class); 33 //指定reduce的类名,这里指定咱们自定义的reduce程序即可 34 job.setReducerClass(WordCountReduce.class); 35 //设置输出key的数据类型 36 job.setOutputKeyClass(Text.class); 37 //设置输出value的数据类型 38 job.setOutputValueClass(IntWritable.class); 39 //设置输入路径,需要传递两个参数,即任务对象(job)以及输入路径 40 FileInputFormat.addInputPath(job,new Path("D:\10.Java\IDE\yhinzhengjieData\MyHadoop\world.txt")); 41 //设置输出路径,需要传递两个参数,即任务对象(job)以及输出路径 42 FileOutputFormat.setOutputPath(job,new Path("D:\10.Java\IDE\yhinzhengjieData\MyHadoop\out")); 43 //等待任务执行结束,将里面的值设置为true。 44 job.waitForCompletion(true); 45 } 46 }
4>.输出文件


The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Apache 1 Hadoop 1 It 1 Rather 1 The 1 a 3 across 1 allows 1 and 2 application 1 at 1 be 1 cluster 1 clusters 1 computation 1 computers 1 computers, 1 data 1 deliver 1 delivering 1 designed 2 detect 1 distributed 1 each 2 failures 1 failures. 1 for 1 framework 1 from 1 handle 1 hardware 1 high-availability, 1 highly-available 1 is 3 itself 1 large 1 layer, 1 library 2 local 1 machines, 1 may 1 models. 1 of 6 offering 1 on 2 processing 1 programming 1 prone 1 rely 1 scale 1 servers 1 service 1 sets 1 simple 1 single 1 so 1 software 1 storage. 1 than 1 that 1 the 3 thousands 1 to 5 top 1 up 1 using 1 which 1
五.集群运行MR程序(Linux开发环境)
1 /*
2 @author :yinzhengjie
3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
4 EMAIL:y1053419035@qq.com
5 */
6 package cn.org.yinzhengjie.mapreduce.wordcount;
7
8 import org.apache.hadoop.io.IntWritable;
9 import org.apache.hadoop.io.LongWritable;
10 import org.apache.hadoop.io.Text;
11 import org.apache.hadoop.mapreduce.Mapper;
12
13 import java.io.IOException;
14
15 public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
16 @Override
17 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
18
19 //得到一行数据
20 String line = value.toString();
21
22 String[] arr = line.split(" ");
23
24 for(String word : arr){
25 context.write(new Text(word), new IntWritable(1));
26 }
27 }
28 }
1 /*
2 @author :yinzhengjie
3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
4 EMAIL:y1053419035@qq.com
5 */
6 package cn.org.yinzhengjie.mapreduce.wordcount;
7
8 import org.apache.hadoop.io.IntWritable;
9 import org.apache.hadoop.io.Text;
10 import org.apache.hadoop.mapreduce.Reducer;
11
12 import java.io.IOException;
13
14 public class WordCountReduce extends Reducer<Text, IntWritable , Text, IntWritable> {
15 @Override
16 protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
17 Integer sum = 0;
18 for(IntWritable value : values){
19 sum += value.get();
20 }
21 context.write(key, new IntWritable(sum));
22 }
23 }
1 /*
2 @author :yinzhengjie
3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
4 EMAIL:y1053419035@qq.com
5 */
6 package cn.org.yinzhengjie.mapreduce.wordcount;
7
8 import org.apache.hadoop.conf.Configuration;
9 import org.apache.hadoop.fs.Path;
10 import org.apache.hadoop.io.IntWritable;
11 import org.apache.hadoop.io.Text;
12 import org.apache.hadoop.mapreduce.Job;
13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
15
16
17 public class WordCountApp {
18 public static void main(String[] args) throws Exception {
19
20 Configuration conf = new Configuration();
21
22 Job job = Job.getInstance(conf);
23
24 job.setJobName("Wordcount");
25 job.setJarByClass(WordCountApp.class);
26
27 job.setMapperClass(WordCountMap.class);
28 job.setReducerClass(WordCountReduce.class);
29
30 job.setOutputKeyClass(Text.class);
31 job.setOutputValueClass(IntWritable.class);
32
33 FileInputFormat.addInputPath(job, new Path(args[0]));
34 FileOutputFormat.setOutputPath(job, new Path(args[1]));
35
36 job.waitForCompletion(true);
37
38 }
39
40 }
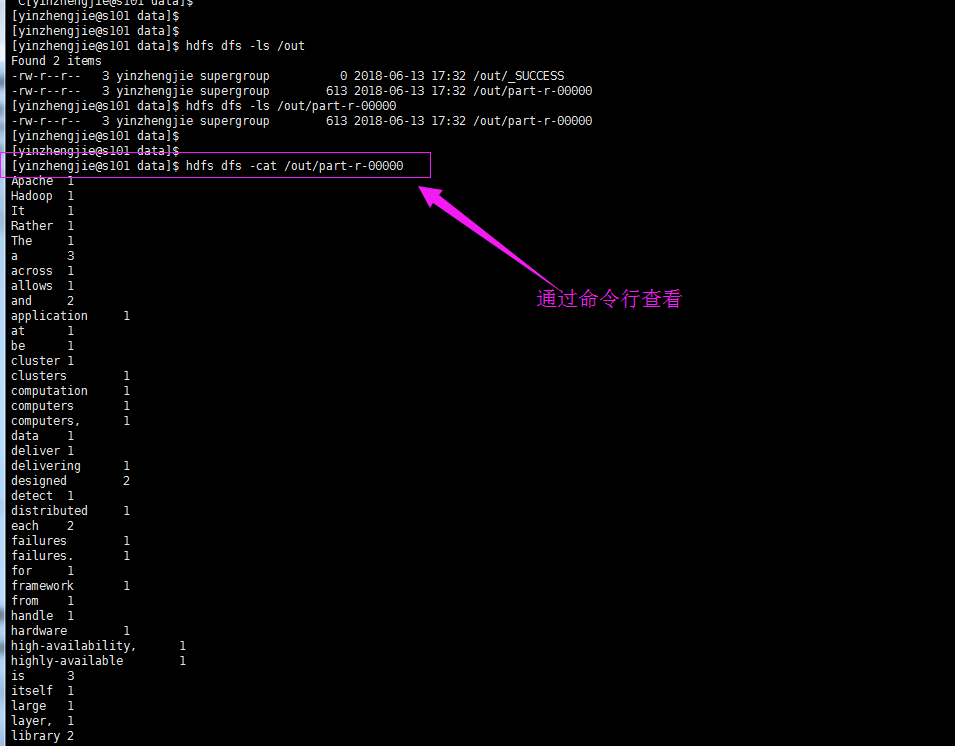
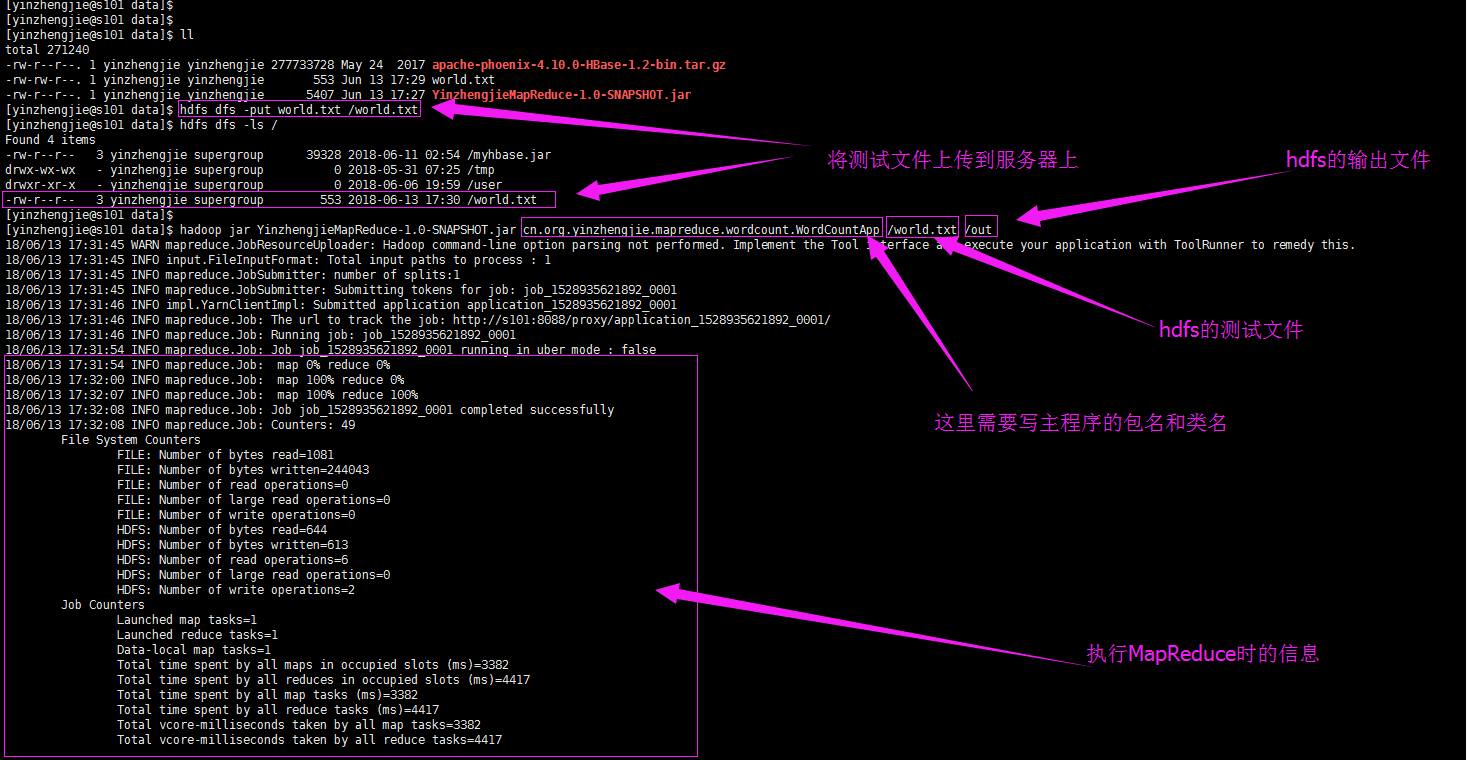
将以上代码打包后,上传到服务器端,然后执行hadoop的命令就可以执行脚本了。具体输出如下:
[yinzhengjie@s101 data]$ hadoop jar YinzhengjieMapReduce-1.0-SNAPSHOT.jar cn.org.yinzhengjie.mapreduce.wordcount.WordCountApp /world.txt /out
18/06/13 17:31:45 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/06/13 17:31:45 INFO input.FileInputFormat: Total input paths to process : 1
18/06/13 17:31:45 INFO mapreduce.JobSubmitter: number of splits:1
18/06/13 17:31:45 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528935621892_0001
18/06/13 17:31:46 INFO impl.YarnClientImpl: Submitted application application_1528935621892_0001
18/06/13 17:31:46 INFO mapreduce.Job: The url to track the job: http://s101:8088/proxy/application_1528935621892_0001/
18/06/13 17:31:46 INFO mapreduce.Job: Running job: job_1528935621892_0001
18/06/13 17:31:54 INFO mapreduce.Job: Job job_1528935621892_0001 running in uber mode : false
18/06/13 17:31:54 INFO mapreduce.Job: map 0% reduce 0%
18/06/13 17:32:00 INFO mapreduce.Job: map 100% reduce 0%
18/06/13 17:32:07 INFO mapreduce.Job: map 100% reduce 100%
18/06/13 17:32:08 INFO mapreduce.Job: Job job_1528935621892_0001 completed successfully
18/06/13 17:32:08 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1081
FILE: Number of bytes written=244043
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=644
HDFS: Number of bytes written=613
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3382
Total time spent by all reduces in occupied slots (ms)=4417
Total time spent by all map tasks (ms)=3382
Total time spent by all reduce tasks (ms)=4417
Total vcore-milliseconds taken by all map tasks=3382
Total vcore-milliseconds taken by all reduce tasks=4417
Total megabyte-milliseconds taken by all map tasks=3463168
Total megabyte-milliseconds taken by all reduce tasks=4523008
Map-Reduce Framework
Map input records=1
Map output records=87
Map output bytes=901
Map output materialized bytes=1081
Input split bytes=91
Combine input records=0
Combine output records=0
Reduce input groups=67
Reduce shuffle bytes=1081
Reduce input records=87
Reduce output records=67
Spilled Records=174
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=205
CPU time spent (ms)=1570
Physical memory (bytes) snapshot=363290624
Virtual memory (bytes) snapshot=4190236672
Total committed heap usage (bytes)=211574784
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=553
File Output Format Counters
Bytes Written=613
[yinzhengjie@s101 data]$
执行代码之后,我们可以去hdfs的WebUI查看结果如下:
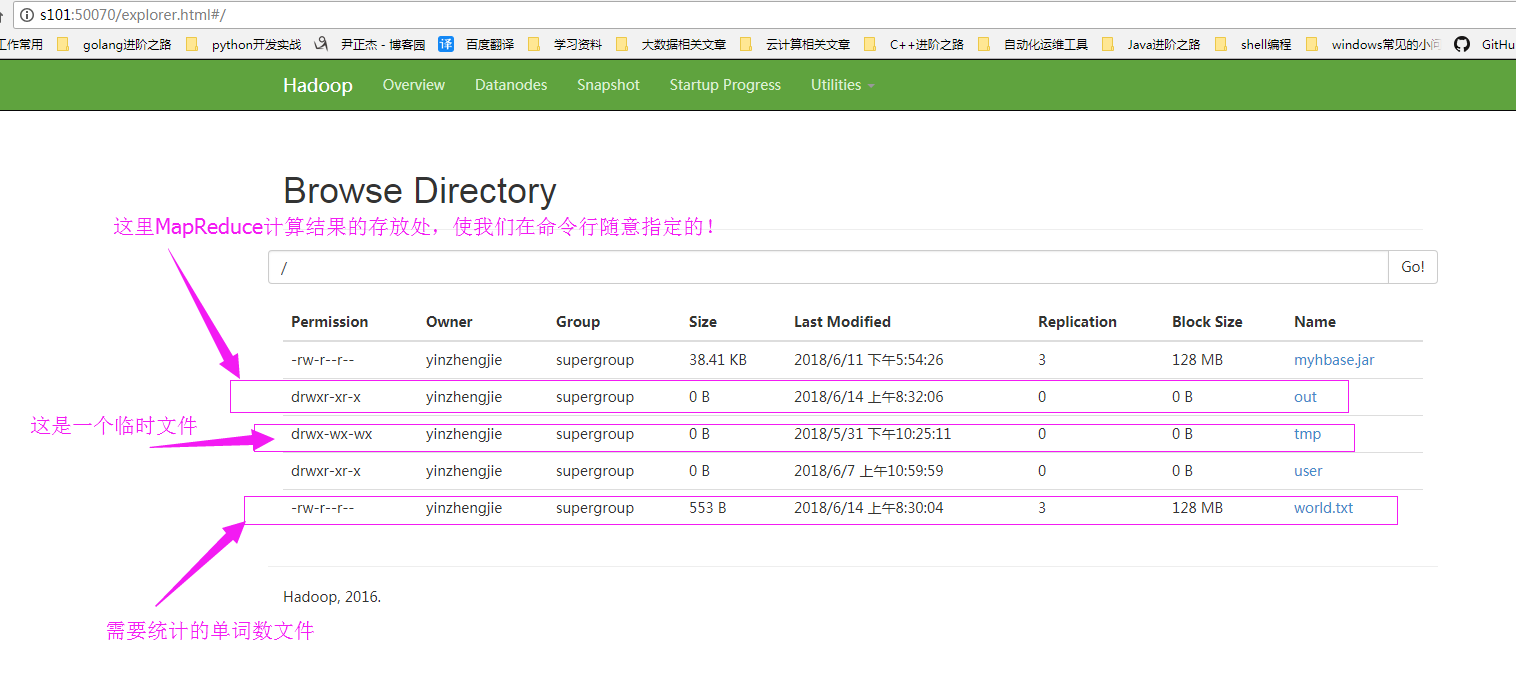
找到我们的文件,然后下载它,查看文件内容:
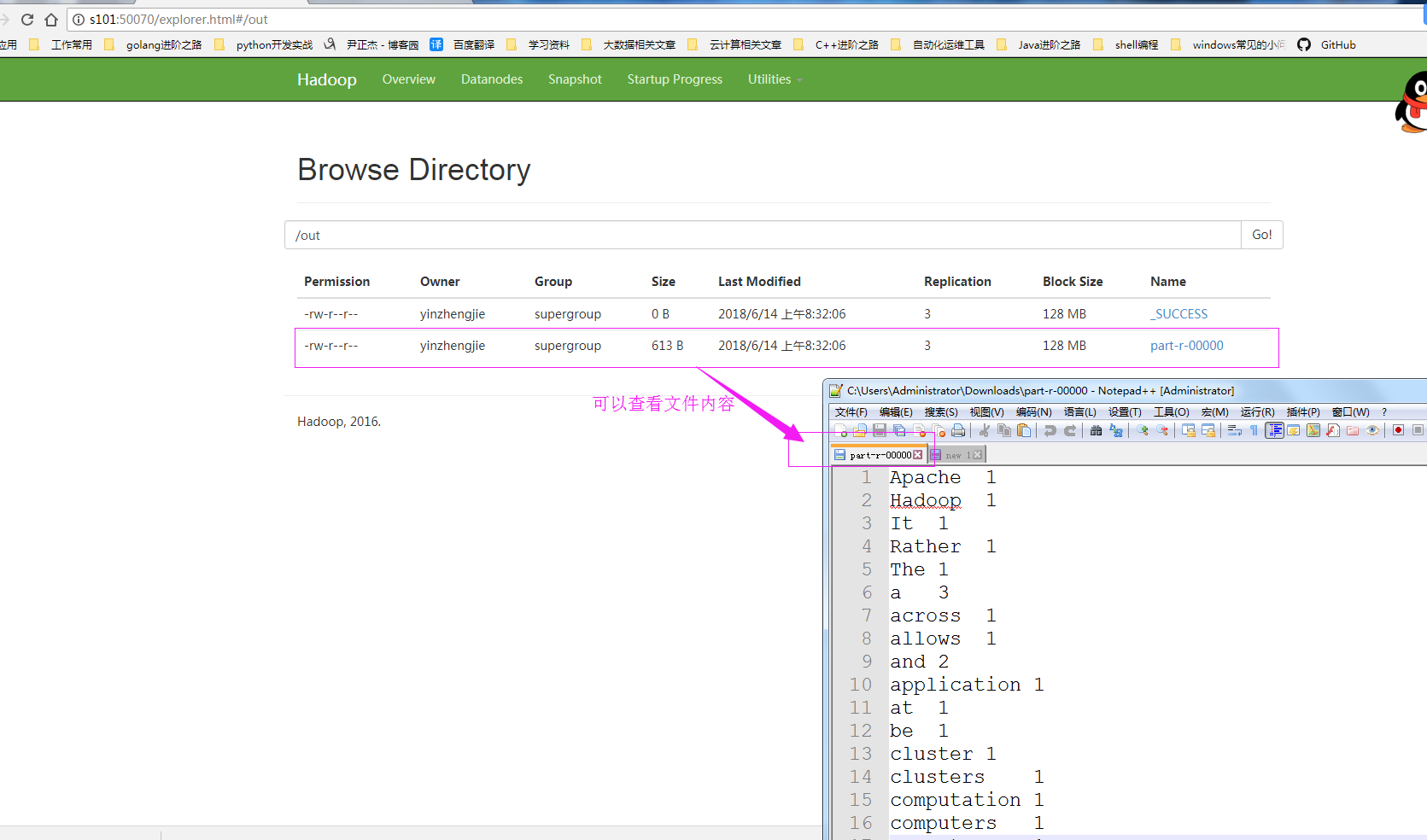
当然,如果你不想下载,也可以通过命令行查看的哟!