Hadoop生态圈-Kafka的旧API实现生产者-消费者
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.旧API实现生产者-消费者
1>.开启kafka集群


[yinzhengjie@s101 ~]$ more `which xkafka.sh` #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #判断用户是否传参 if [ $# -ne 1 ];then echo "无效参数,用法为: $0 {start|stop}" exit fi #获取用户输入的命令 cmd=$1 for (( i=102 ; i<=104 ; i++ )) ; do tput setaf 2 echo ========== s$i $cmd ================ tput setaf 9 case $cmd in start) ssh s$i "source /etc/profile ; kafka-server-start.sh -daemon /soft/kafka/config/server.properties" echo s$i "服务已启动" ;; stop) ssh s$i "source /etc/profile ; kafka-server-stop.sh" echo s$i "服务已停止" ;; *) echo "无效参数,用法为: $0 {start|stop}" exit ;; esac done [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ xkafka.sh start ========== s102 start ================ s102 服务已启动 ========== s103 start ================ s103 服务已启动 ========== s104 start ================ s104 服务已启动 [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ xcall.sh jps ============= s101 jps ============ 15173 Jps 命令执行成功 ============= s102 jps ============ 2841 QuorumPeerMain 6745 Kafka 6842 Jps 命令执行成功 ============= s103 jps ============ 6657 Jps 2821 QuorumPeerMain 6590 Kafka 命令执行成功 ============= s104 jps ============ 7920 Jps 2823 QuorumPeerMain 7853 Kafka 命令执行成功 ============= s105 jps ============ 12896 Jps 命令执行成功 [yinzhengjie@s101 ~]$ [yinzhengjie@s101 ~]$ more `which xcall.sh` #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #判断用户是否传参 if [ $# -lt 1 ];then echo "请输入参数" exit fi #获取用户输入的命令 cmd=$@ for (( i=101;i<=105;i++ )) do #使终端变绿色 tput setaf 2 echo ============= s$i $cmd ============ #使终端变回原来的颜色,即白灰色 tput setaf 7 #远程执行命令 ssh s$i $cmd #判断命令是否执行成功 if [ $? == 0 ];then echo "命令执行成功" fi done [yinzhengjie@s101 ~]$
2>.编写生产者端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.kafka; 7 8 import kafka.javaapi.producer.Producer; 9 import kafka.producer.KeyedMessage; 10 import kafka.producer.ProducerConfig; 11 import java.util.Properties; 12 13 public class TestProducer { 14 15 16 public static void main(String[] args) throws Exception { 17 //初始化Java的Properties属性 18 Properties props = new Properties(); 19 //通过metadata.broker.list参数设置代理,其value对应的kafka服务器地址,如果有多个就用逗号(",")分隔。 20 props.put("metadata.broker.list", "s102:9092, s103:9092, s104:9092"); 21 //指定message的数据类型,将传输的数据都序列化成字符串(String),当然还有很多序列化方式(LongEncoder,NullEncoder,DefalutEmcoder,IntegerEncoder),比如默认为字节类型等等。 22 props.put("serializer.class", "kafka.serializer.StringEncoder"); 23 //包装java的prop,包装成ProducerConfig 24 ProducerConfig config = new ProducerConfig(props); 25 //使用producerConfig初始化producer 26 //<String, String> 中第一个为key类型(未接触到),第二个是value类型,真实数据 27 Producer<String, String> producer = new Producer<String, String>(config); 28 //定义kafka的主题 29 String topic = "yinzhengjie"; 30 for (int i = 1000; i < 2000; i++) { 31 KeyedMessage<String, String> data = new KeyedMessage<String, String>(topic, "BigData" + i); 32 producer.send(data); 33 Thread.sleep(500); 34 } 35 producer.close(); 36 } 37 }
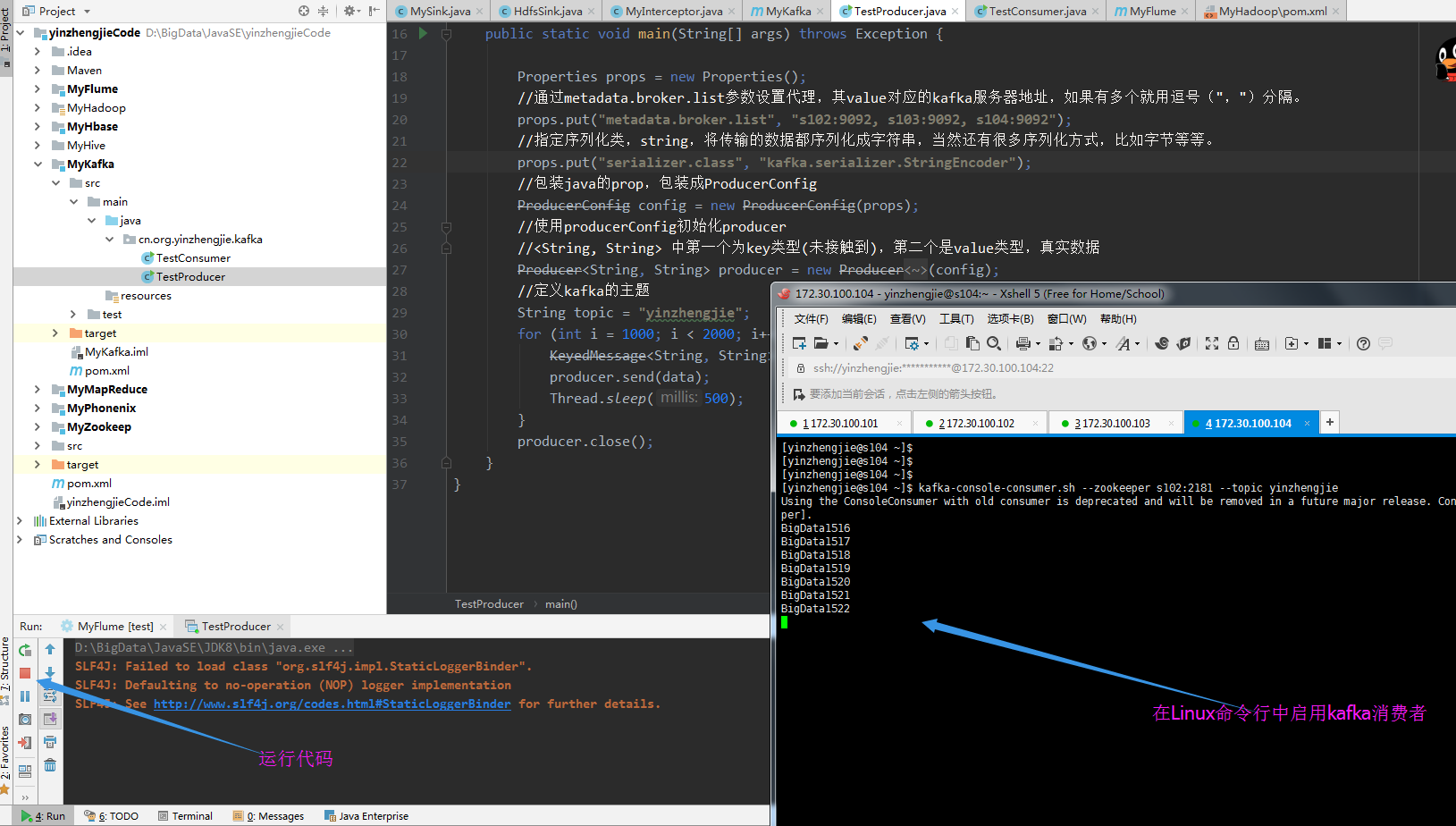
运行以上代码,并在Linux中断启用KafKa的消费者,截图如下:
3>.编写消费者端代码
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/ 4 EMAIL:y1053419035@qq.com 5 */ 6 package cn.org.yinzhengjie.kafka; 7 8 import java.util.HashMap; 9 import java.util.List; 10 import java.util.Map; 11 import java.util.Properties; 12 import kafka.consumer.ConsumerConfig; 13 import kafka.consumer.ConsumerIterator; 14 import kafka.consumer.KafkaStream; 15 import kafka.javaapi.consumer.ConsumerConnector; 16 17 public class TestConsumer { 18 public static void main(String[] args) { 19 Properties props = new Properties(); 20 props.put("zookeeper.connect", "s102:2181,s103:2181,s104:2181"); 21 //设置组id名称 22 props.put("group.id", "yzj"); 23 //ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大 24 props.put("zookeeper.session.timeout.ms", "500"); 25 //定义ZooKeeper集群中leader和follower之间的同步时间 26 props.put("zookeeper.sync.time.ms", "250"); 27 //consumer向zookeeper提交offset的频率,单位是毫秒 28 props.put("auto.commit.interval.ms", "1000"); 29 //把props封装成一个ConsumerConfig对象 30 ConsumerConfig conf = new ConsumerConfig(props); 31 //创建出一个ConsumerConnector实例 32 ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(conf); 33 //定义一个集合,这个集合最终被被传入到consumer.createMessageStreams()方法中。 34 Map<String, Integer> topicMap = new HashMap<String, Integer>(); 35 //topicMap中指定第一个参数是主题,第二个参数是指定线程个数。 36 topicMap.put("yinzhengjie", new Integer(1)); 37 //通过consumer和topic获取到数据流,在Map中的第一个参数是:topic,第二个参数是:消息列表 38 Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreamsMap = consumer.createMessageStreams(topicMap); 39 //通过topic返回所有消息列表 40 List<KafkaStream<byte[], byte[]>> streamList = consumerStreamsMap.get("yinzhengjie"); 41 //迭代所有list,通过迭代器获取消息流中的k-v 42 for (final KafkaStream<byte[], byte[]> stream : streamList) { 43 ConsumerIterator<byte[], byte[]> consumerIte = stream.iterator(); 44 while (consumerIte.hasNext()) 45 System.out.println("Message from Single Topic :: "+ new String(consumerIte.next().message())); 46 } 47 } 48 }
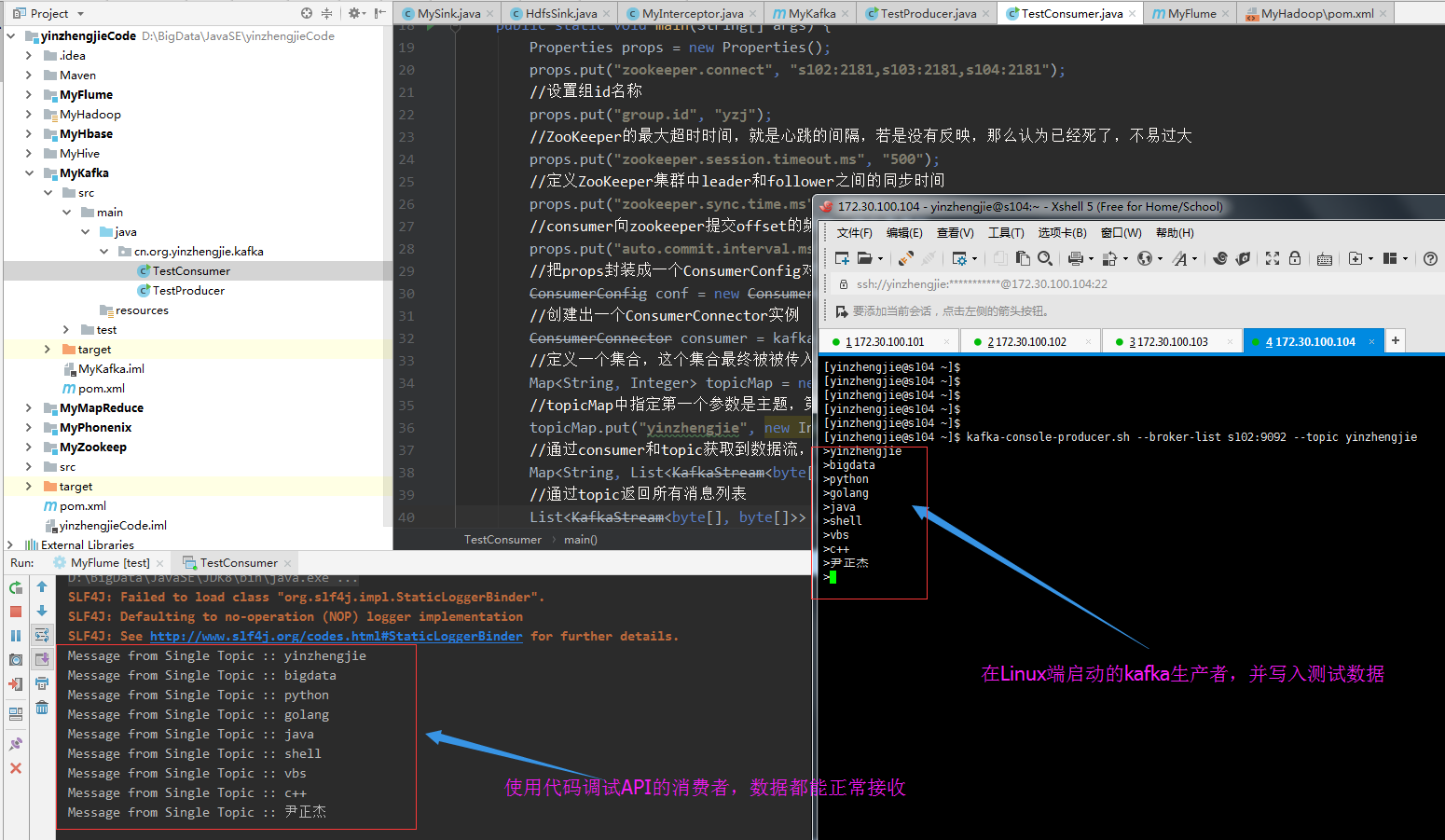
在Linux端启动生产者并运行以上代码,输出结果如下:
二.kafka的producer和Consumer配置(实战重点,调优手段)
1>.kafka的producer配置
1>.metadata.broker.list 答:kafka服务器地址,如果有多个就用逗号(",")分隔。
2>.serializer.class 答:指定message的数据类型。
3>.key.serializer.class 答:指定key的数据类型,key的作用,用作选择分区。默认kafka.serializer.DefaultEncoder(byte[]),常用的还有 "kafka.serializer.NullEncoder","kafka.serializer.NullEncoder","kafka.serializer.StringEncoder","kafka.serializer.IntegerEncoder" "kafka.serializer.LongEncoder"。 4>.producer.type 答:指定消息应该如何发送。比如async和sync。 //async 异步,将数据发在缓冲区,一并发送给broker,无序 100000条数据:3792 //sync 同步,正常发送,有序 100000条数据:31939ms
5>.batch.num.messages 答:指定异步发送中一个批次含有多少条数据,默认200,超过此值就会发送。
6>.queue.buffer.max.ms 答:队列的毫秒数,到达此值数据也会发送。 7>.request.required.acks 答:获取回值,有三种回值方式(并对着三种方式处理100000条数据的所用时间): //0意味着 producer不等待broker的回执,适用于最低延迟,不保证数据的完整性(3559) //1意味着 只接收分区中的leader回执(4421) //-1意味着 接收所有in-sync状态下的节点回执(6792)
8>.partitioner.class 答:指定分区函数类。 9>.compression.codec 答:指定压缩编解码器none, gzip, and snappy.
2>.kafka的Consumer配置
重复消费的手段: 设置从头消费 //--from-beginning //auto.offset.reset = smallest 手动控制消费偏移量 //通过修改zk数据 consumer/groupid/offsets/topic/partition 1>.group.id 答:指定消费者组id,没有指定会自动创建。 2>.consumer.id 答:指定消费者的id,没有指定会自动创建。 3>.zookeeper.connect 答:指定zookeeper客户端地址。 4>.client.id 答:指定自己的客户端id,没有指定会和group.id一样。 5>.zookeeper.session.timeout.ms 答:zk会话超时则抛异常。 6>.zookeeper.connection.timeout.ms 答:zk连接超时则抛异常。 7>.zookeeper.sync.time.ms 答:控制zk同步数据的时间。 8>.auto.commit.enable 答:自动提交消息的偏移量到zk。 9>.auto.commit.interval.ms 答:自动提交偏移量的间隔。 10>.auto.offset.reset 答:设置从哪里读取数据 //largest 读取最新数据 //smallest 读取zk中偏移量的数据 11>.consumer.timeout.ms 答:consumer超时抛异常,并关闭连接
3>.以上部分参数测试代码如下
三.