flume配置kafka channle的实战案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
最近在新公司负责大数据平台的建设,平台搭建完毕后,需要将云平台(我们公司使用的Ucloud的云服务器,大概320多台,还在扩容中),公司每个月光大数据服务费用就接近50万人民币。老板考虑成本问题,花了接近200万的前采购了50台服务器用于大数据平台的建设。我已经将集群部署好了,正准备将云上的环境原样搬到我的新平台上时,遇到了一系列的坑,我已经填了不少的坑。这不,关于flume的一个channel的选择也是一个坑。
我们知道常用的channel如下:
file channel的特点是:速度慢,支持容灾;
memory channel的特点是:速度快,断电丢数据,我们在Ucloud上使用的就是它;
kafka channel的特点是:高速缓存;
一.flume报错OOM
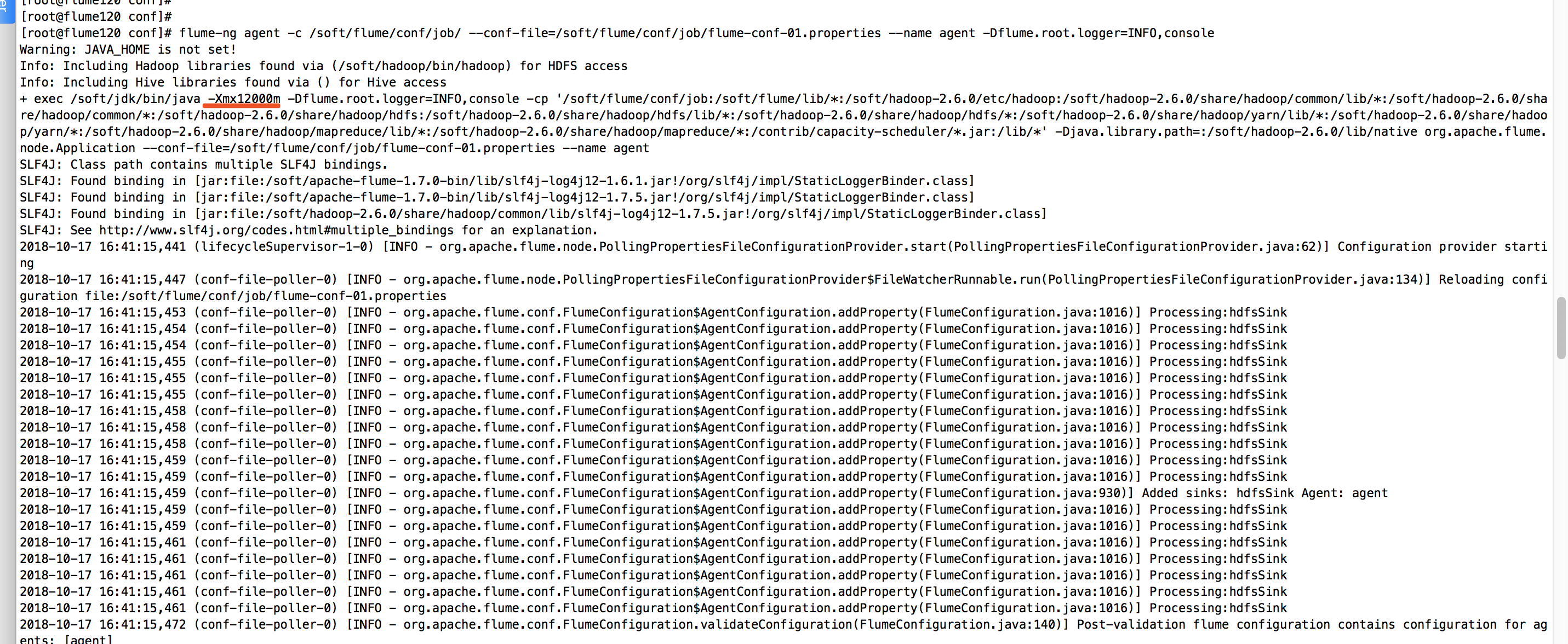
计划将kafka的数据通过flume抽取到hdfs上,真是flume略我千百变,我带flume如初恋啊。经过各种测试,我已经将flume的内存提升到12G,下面是我启动flume看到的信息,如下图:
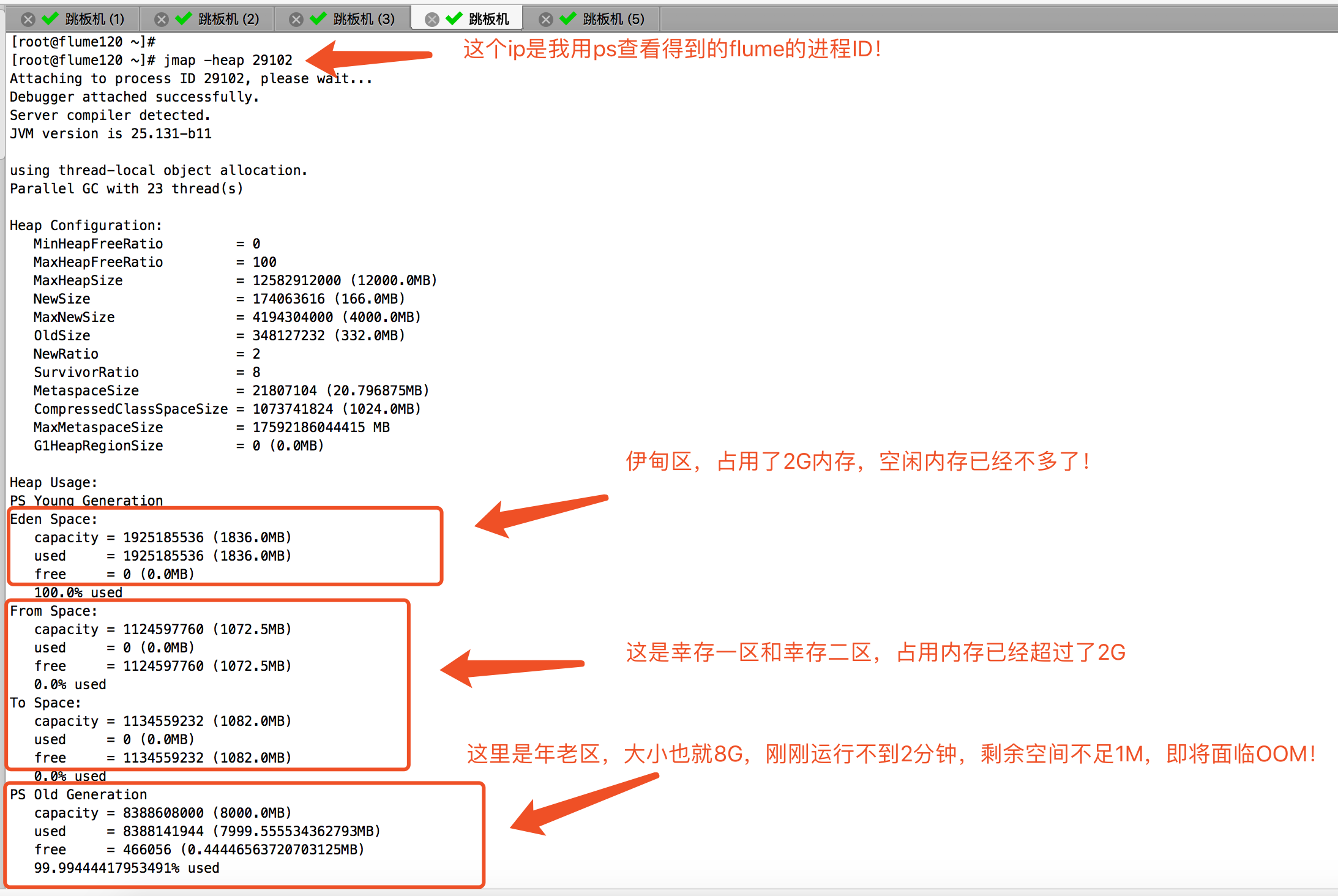
启动后,我开启了一个终端,查看JVM的内存使用情况,发现分分钟就给我吃满了!如下图:
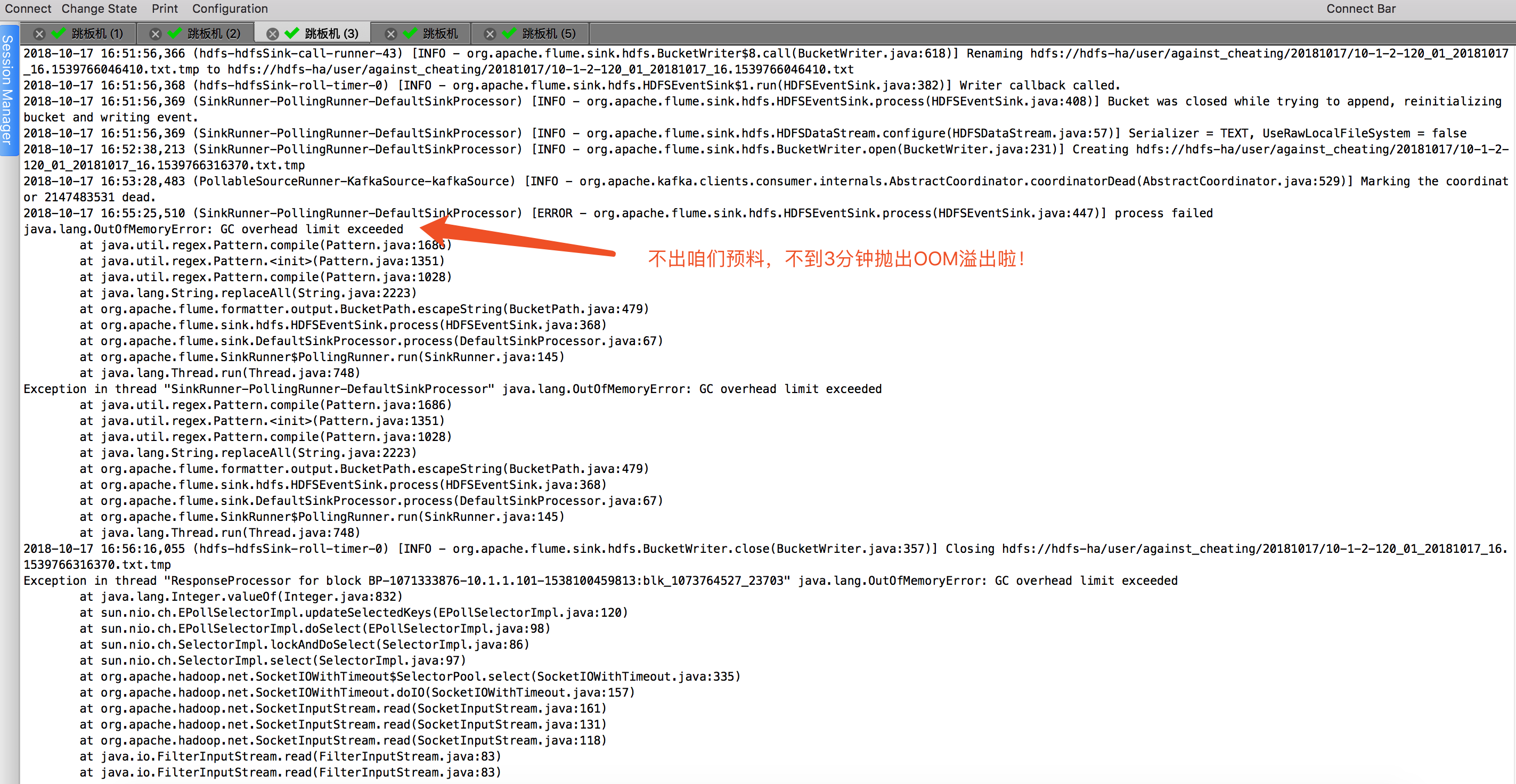
接下来,不到3分钟时间,flume就崩溃了,频繁抛出OOM的异常信息:
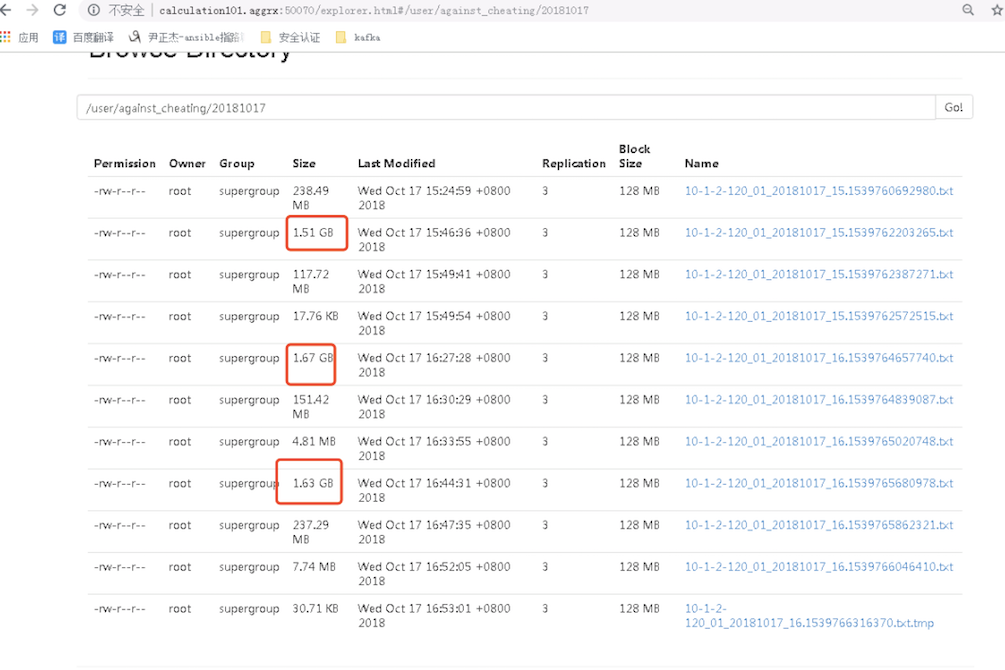
接下来,我们看一下hdfs集群中是否有数据,答案是肯定的,hdfs的确是有数据:
咋解决呢?大家可能说,你继续加大内存呗,12G不够,就给24G试试看!OK,我就JVM的堆内存调试到24G,启动程序:
在后端查看flume的进程ID:

查看JVM的运行情况,如下:

经过上面的改造后,我一致在等OOM,可惜一个小时过去了,始终没有抛出OOM异常,我有点小失落,也有点小开心。开心的是终于不崩溃了,失落的是还剩下4个G,那我原来打算在这台服务器上开启8个flume进程的计划是要泡汤了,因为是总大小总共才32G,有上面解决方案呢?查看官网,据说是有种基于Kafka channel的模式。也是本篇博客的想要说的主角。
二.分析OOM的解决方案
1>.分析为什么会抛OOM溢出
其实想象大家也知道,source是kafka,而sink是hdfs,他们两个的吞吐量闭着眼睛大家都知道谁是快谁慢。
hdfs集群的工作原理可知,它在写数据和读取数据时都会和NameNode这个服务器进行交互,需要一系列验证操作,最后读操作或者写操作依然不是和NameNode进行交互,而是client直接跟DataNode进行交互。
kafka则是基于partition来进行消费的,网上有些文章说partition的数越多,意味着kafka的吞吐量就越大,其实这个说法并不严谨,parition的数量应该小于集群的core总数,因为每个消费者基于paritition进行消费时,服务器都会开启一个线程去应酬,如果你一台服务器paritrion响应的特别多,设计到上下文切换反而不理想了。一个消费者可以去集群同时对多个partition进行消费。
以上的观点仅是我个人对Kafka和hdfs的理解,如果哪里有说的不对的话,欢迎各位大神之路!综上所述,我们都说kafka的速度要远远大于hdfs,kafka是顺序写入磁盘的,他的速度可达到300M/s,我们可以毫不客气的说,顺序写入磁盘相比随机写入内存的速度有过之而无不及。
好了,上面说了一堆的废话,咱们回归正题,为什么会OOM呢?原因很简单,我们形象的说:想必大家都喝过可乐吧,可乐的汽水瓶形状大家也应该清楚吧,我们将可乐瓶的瓶盖去掉,然后把可乐瓶的平底削去,我们假设我们在粗的一端(原来的瓶底)注水进去,然后水会送细的一端(原来的瓶盖)出去没毛病吧?理论上来说,如果粗的一端源源不断的网可乐瓶中注水,水也会远远不断的从小瓶盖中出去,但是当粗的一端流入端的速度远远高于流出端的速度,那么可乐瓶容器很快就会积累很多的水,知道把可能瓶注满水,当注满水以后,这个时候还要往里面注水的话,可乐瓶容器可能会变形,设置可能会将可能瓶撑爆。
如果你看懂了我上面的描述,那么你我们在结合kafka和hdfs,说一说,谁是瓶底,谁是瓶盖,谁是可乐瓶呢?我的理解是此时我们的瓶底的一端就是kafka,可乐瓶本身就是memory channel,瓶口那一端就是hdfs。那么瓶子被水撑满最终爆裂就好比咱们的OOM。
2>.编写flume的配置文件(该配置文件我是根据生产环境稍作改动,可供参考)
[root@flume120 ~]# cat /soft/flume/conf/job/flume-conf-01.properties #定义别名 agent.sources = kafkaSource agent.channels = fileChannel agent.sinks = hdfsSink #绑定关系 agent.sources.kafkaSource.channels = fileChannel agent.sinks.hdfsSink.channel = fileChannel #指定source源为kafka source agent.sources.kafkaSource.type = org.apache.flume.source.kafka.KafkaSource agent.sources.kafkaSource.kafka.bootstrap.servers = 10.1.3.116:9092,10.1.3.117:9092,10.1.3.118:9092,10.1.3.119:9092,10.1.3.120:9092 agent.sources.kafkaSource.topic = against_cheating_01 agent.sources.kafkaSource.groupId = 1 agent.sources.kafkaSource.kafka.consumer.timeout.ms = 70000 agent.sources.kafkaSource.kafka.consumer.request.timeout.ms = 80000 agent.sources.kafkaSource.kafka.consumer.fetch.max.wait.ms=7000 agent.sources.kafkaSource.kafka.consumer.offset.flush.interval.ms = 50000 agent.sources.kafkaSource.kafka.consumer.session.timeout.ms = 70000 agent.sources.kafkaSource.kafka.consumer.heartbeat.interval.ms = 60000 agent.sources.kafkaSource.kafka.consumer.enable.auto.commit = false agent.sources.kafkaSource.interceptors = i1 agent.sources.kafkaSource.interceptors.i1.userIp = true agent.sources.kafkaSource.interceptors.i1.type = host #指定channel类型为kafka agent.channels.fileChannel.type = org.apache.flume.channel.kafka.KafkaChannel agent.channels.fileChannel.kafka.bootstrap.servers = 10.1.3.116:9092,10.1.3.117:9092,10.1.3.118:9092,10.1.3.119:9092,10.1.3.120:9092 agent.channels.fileChannel.kafka.topic = channel_against_cheating_01 agent.channels.fileChannel.kafka.consumer.group.id = flume-consumer-against_cheating_01 agent.channels.fileChannel.kafka.consumer.timeout.ms = 70000 agent.channels.fileChannel.kafka.consumer.request.timeout.ms = 80000 agent.channels.fileChannel.kafka.consumer.fetch.max.wait.ms=7000 agent.channels.fileChannel.kafka.consumer.offset.flush.interval.ms = 50000 agent.channels.fileChannel.kafka.consumer.session.timeout.ms = 70000 agent.channels.fileChannel.kafka.consumer.heartbeat.interval.ms = 60000 agent.channels.fileChannel.kafka.consumer.enable.auto.commit = false #指定sink的类型为hdfs agent.sinks.hdfsSink.type = hdfs agent.sinks.hdfsSink.hdfs.path = hdfs://hdfs-ha/user/against_cheating/%Y%m%d agent.sinks.hdfsSink.hdfs.filePrefix = 10-1-2-120_01_%Y%m%d_%H agent.sinks.hdfsSink.hdfs.fileSuffix = .txt agent.sinks.hdfsSink.hdfs.useLocalTimeStamp = true agent.sinks.hdfsSink.hdfs.writeFormat = Text agent.sinks.hdfsSink.hdfs.fileType=DataStream agent.sinks.hdfsSink.hdfs.rollCount = 0 agent.sinks.hdfsSink.hdfs.rollSize = 0 agent.sinks.hdfsSink.hdfs.rollInterval = 180 agent.sinks.hdfsSink.hdfs.batchSize = 100 agent.sinks.hdfsSink.hdfs.threadsPoolSize = 50 agent.sinks.hdfsSink.hdfs.idleTimeout = 0 agent.sinks.hdfsSink.hdfs.minBlockReplicas = 1 agent.sinks.hdfsSink.hdfs.callTimeout=100000 agent.sinks.hdfsSink.hdfs.request-timeout=100000 agent.sinks.hdfsSink.hdfs.connect-timeout=80000 [root@flume120 ~]#
3>.启动flume
[root@flume120 ~]# cd /soft/flume/shell/ [root@flume120 shell]# [root@flume120 shell]# ll total 20 -rwxr-xr-x 1 root root 850 Oct 18 14:44 start_flume_against_cheating_01.sh -rwxr-xr-x 1 root root 849 Oct 18 14:43 start_flume_against_cheating_02.sh -rwxr-xr-x 1 root root 850 Oct 18 14:42 start_flume_against_cheating_03.sh -rwxr-xr-x 1 root root 850 Oct 18 14:42 start_flume_against_cheating_04.sh -rwxr-xr-x 1 root root 850 Oct 18 14:58 start_flume_against_cheating_05.sh [root@flume120 shell]# [root@flume120 shell]# cat start_flume_against_cheating_01.sh #我们直接执行这个脚本就行,默认就可以执行啦! #!/bin/bash #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie #EMAIL:y1053419035@qq.com #Data:Thu Oct 18 11:26:06 CST 2018 #将监控数据发送给ganglia,需要指定ganglia服务器地址,使用请确认是否部署好ganglia服务! #nohup flume-ng agent -c /soft/flume/conf/job/ --conf-file=/soft/flume/conf/job/flume-conf-01.properties --name agent -Dflume.monitoring.type=ganglia -Dflume.monitoring.hosts=10.1.2.120:8649 -Dflume.root.logger=INFO,console >> /soft/flume/logs/flume-ganglia-01.log 2>&1 & #启动flume自身的监控参数,默认执行以下脚本 nohup flume-ng agent -c /soft/flume/conf/job/ --conf-file=/soft/flume/conf/job/flume-conf-01.properties --name agent -Dflume.monitoring.type=http -Dflume.monitoring.port=5201 -Dflume.root.logger=INFO,console >> /soft/flume/logs/flume-http-01.log 2>&1 & [root@flume120 shell]#
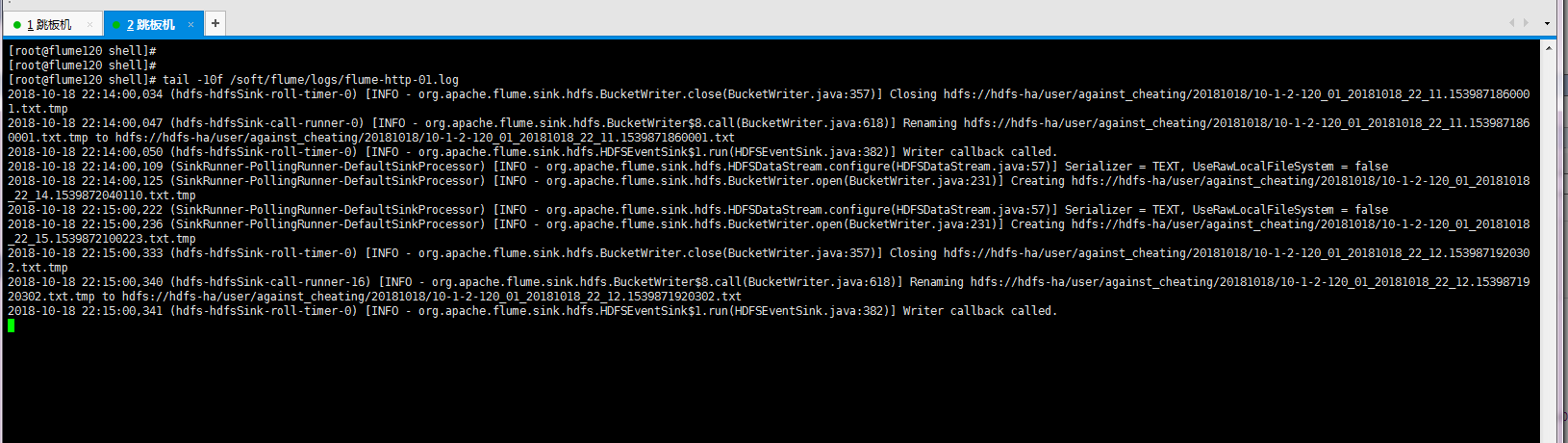
4>.查看日志([root@flume120 shell]# tail -10f /soft/flume/logs/flume-http-01.log)