Hadoop基础-HDFS集群中大数据开发常用的命令总结
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多,比如滚动编辑,融合镜像文件,目录的空间配额等运维操作,请参考我之前的笔记:https://www.cnblogs.com/yinzhengjie/p/9074730.html
1>.基本语法
[root@node105 ~]# hadoop fs

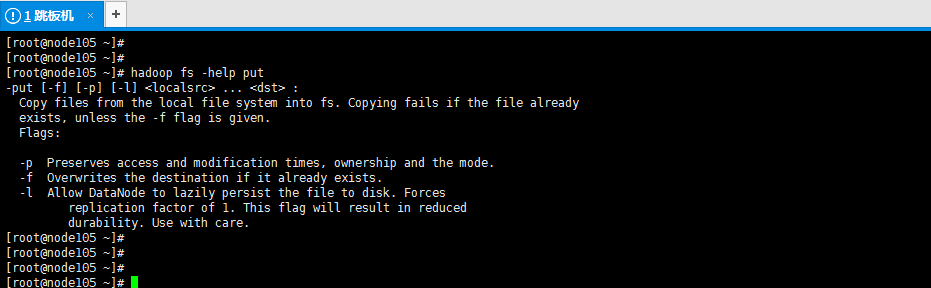
2>.查看hdfs的某个命令的帮助信息
[root@node105 ~]# hadoop fs -help put

3>.显示某个目录的信息
[root@node105 ~]# hadoop fs -ls /

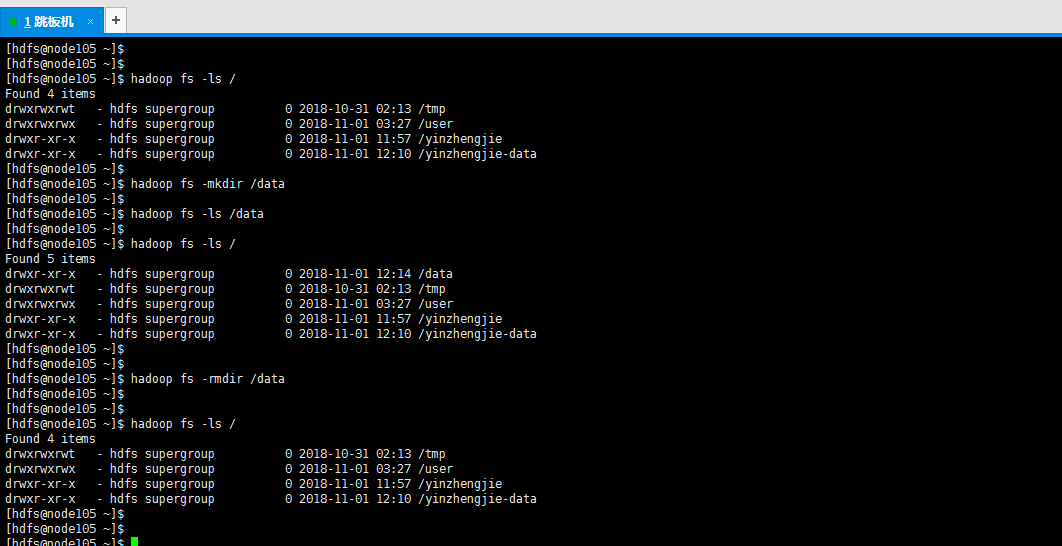
4>.在hdfs上创建目录
[hdfs@node105 ~]$ hadoop fs -mkdir /data

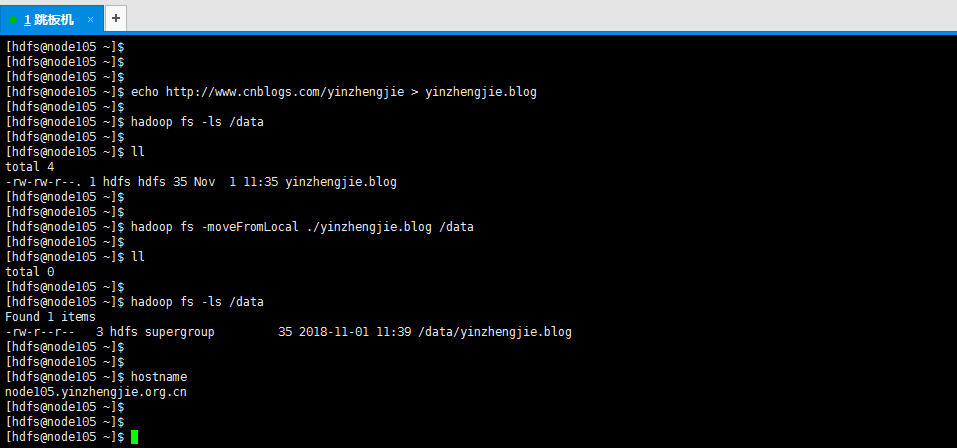
5>.将本地的文件剪切到hdfs集群上
6>.查看文件内容
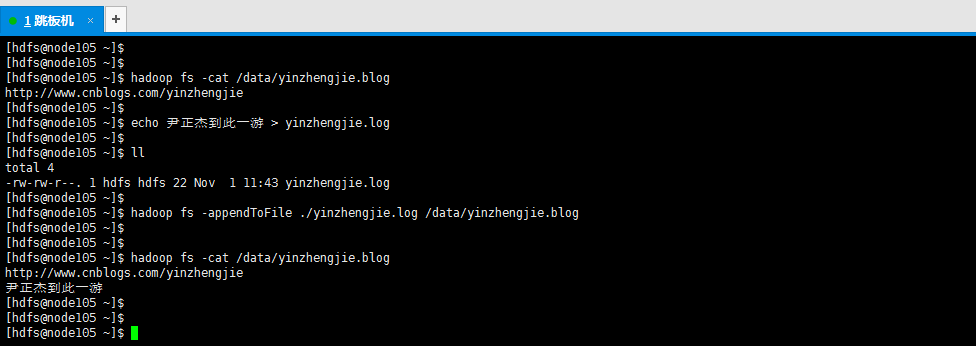
[hdfs@node105 ~]$ hadoop fs -cat /data/yinzhengjie.blog

7>.追加一个文件到hdfs中已经存在的一个文件末尾
[hdfs@node105 ~]$ hadoop fs -appendToFile ./yinzhengjie.log /data/yinzhengjie.blog
8>.显示一个文件的末尾
[hdfs@node105 ~]$ hadoop fs -tail /data/yinzhengjie.blog

9>.修改权限
[hdfs@node105 ~]$ hadoop fs -chmod 755 /data/yinzhengjie.blog

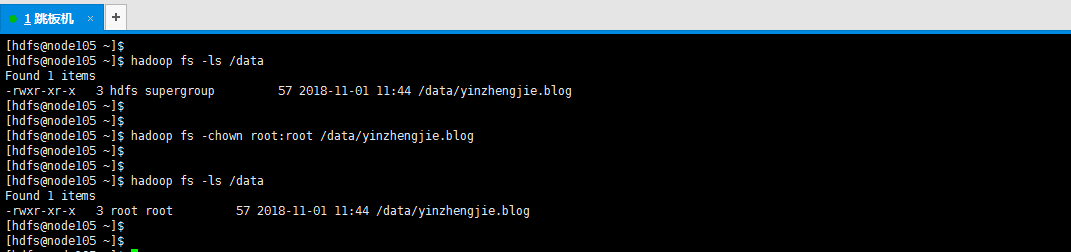
10>.修改文件的所属者
[hdfs@node105 ~]$ hadoop fs -chown root:root /data/yinzhengjie.blog
11>.从本地文件系统拷贝文件到hdfs集群中
[hdfs@node105 ~]$ hadoop fs -copyFromLocal ./yinzhengjie.log /data
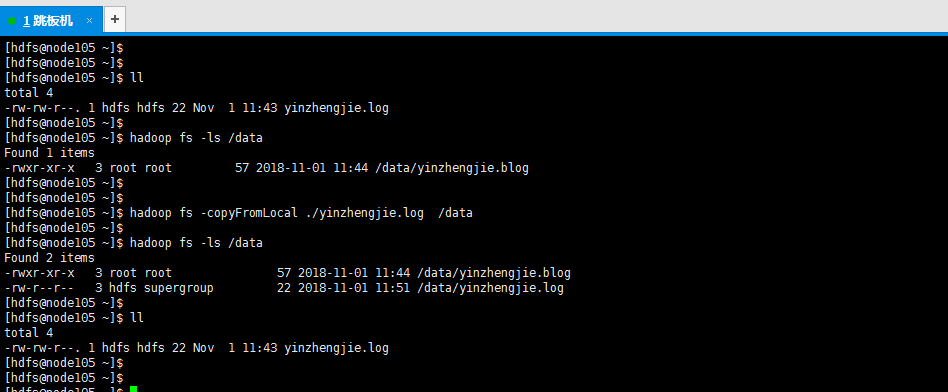
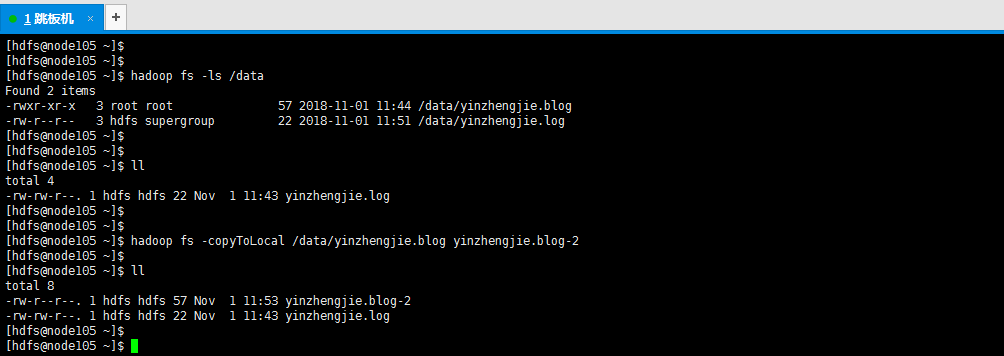
12>.从hdfs集群拷贝数据到本地
[hdfs@node105 ~]$ hadoop fs -copyToLocal /data/yinzhengjie.blog yinzhengjie.blog-2
13>.在hdfs集群中从一个目录拷贝到另外一个目录中
[hdfs@node105 ~]$ hadoop fs -cp /data/yinzhengjie.blog /yinzhengjie

14>.在hdfs就群中,从一个目录移动到另外一个目录
hdfs@node105 ~]$ hadoop fs -mv /yinzhengjie/yinzhengjie.blog /data/yinzhengjie.blog-2

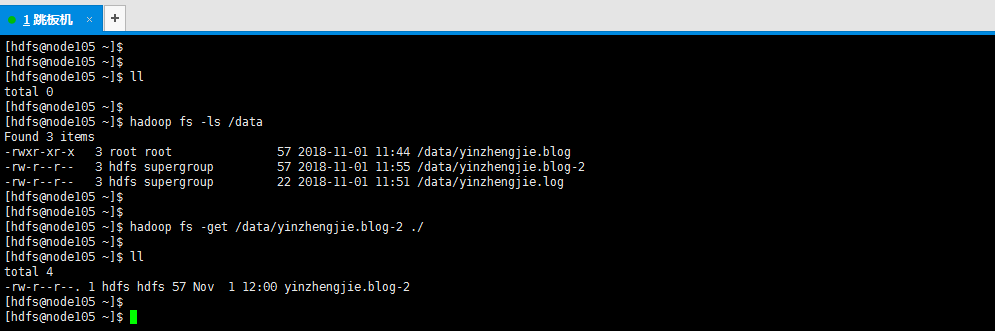
15>.下载文件到本地
[hdfs@node105 ~]$ hadoop fs -get /data/yinzhengjie.blog-2 ./
16>.将hdfs中多个文件的内容下载到本地并仅生成一个文件
[hdfs@node105 ~]$ hadoop fs -getmerge /yinzhengjie-data/* ./yinzhengjie.log

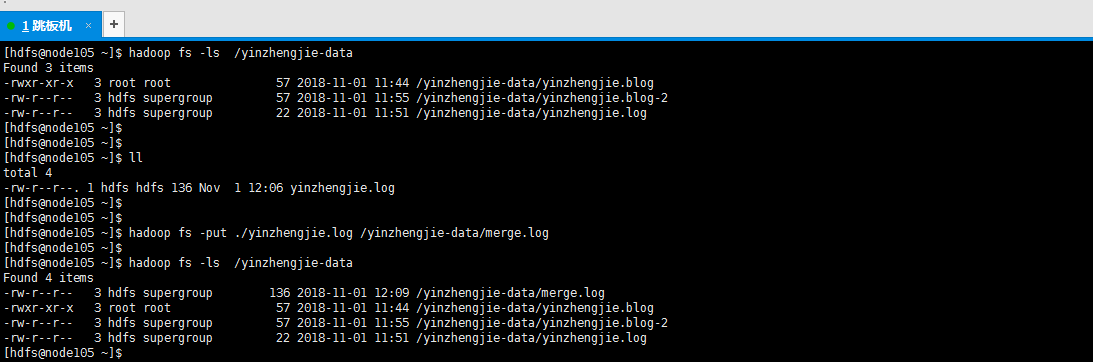
17>.将本地文件上传的hdfs指定目录并改名
[hdfs@node105 ~]$ hadoop fs -put ./yinzhengjie.log /yinzhengjie-data/merge.log
18>.删除hdfs集群中国的某个文件或文件夹
[hdfs@node105 ~]$ hadoop fs -rm /yinzhengjie-data/yinzhengjie.blog-2
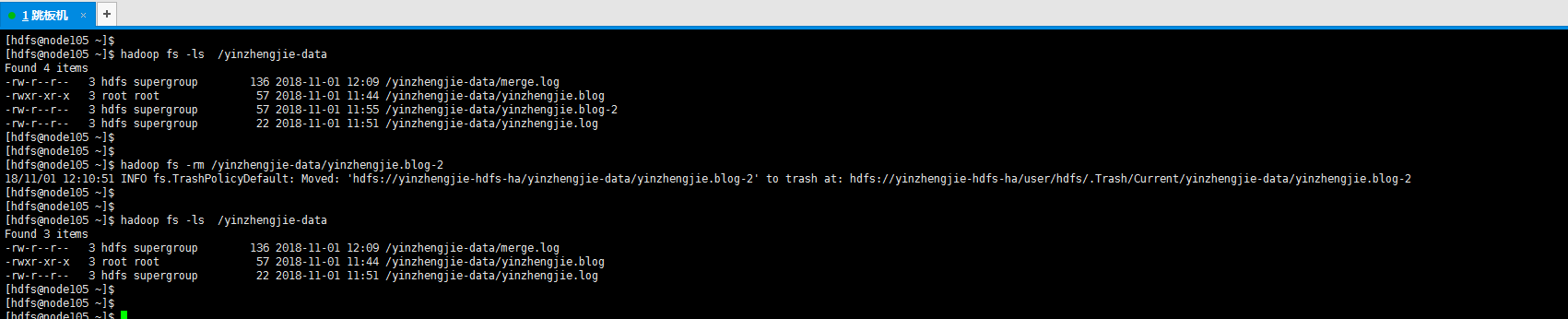
19>.删除空的文件夹
[hdfs@node105 ~]$ hadoop fs -rmdir /data
20>.统计hdfs文件系统可用空间信息
[root@calculation101 ~]# hadoop fs -df -h /

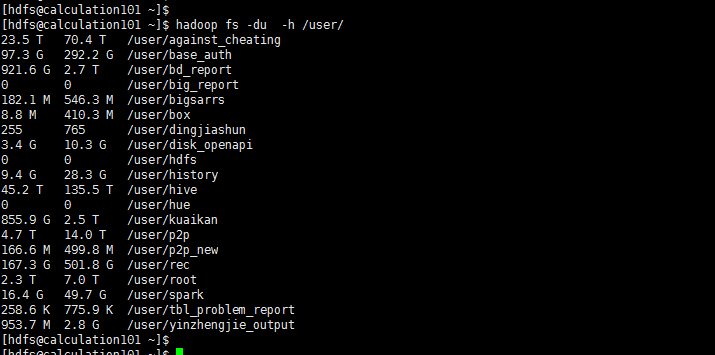
21>.统计文件夹的大小信息
[hdfs@calculation101 ~]$ hadoop fs -du -h /user/
22>.设置hdfs文件中的副本数量
[root@calculation101 ~]# hadoop fs -setrep 10 /user/yinzhengjie_output/part-m-00000
