Apache Hadoop配置日志聚集实战案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.准备工作
1>.搭建完全分布式集群
博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12424192.html
2>.配置历史服务器
博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12430965.html
二.配置日志聚集实操案例
1>.日志聚集的功能
还记得上一篇博客我们分享如何配置历史服务器吗?我们在那篇博客给大家截图演示了一个job运行完成之后,会将数据存储在HDFS集群上,如果你没有指定日志存放路径默认放在HDFS集群的"/tmp"目录下。 综上所述,无论是一个Spark,Flink还是MapReduce的job在应用(比如:"application_1584002509171_0001")运行完成以后,将程序运行日志信息上传到HDFS系统上,这就是日志聚集的概念。 有了日志聚集每一台Gateway主机都可以访问HDFS集群,从而获取日志信息,可以方便查看到job的运行详情,方便运维或开发调试。 温馨提示: 开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
2>.开启日志聚集功能
[root@hadoop101.yinzhengjie.org.cn ~]# vim ${HADOOP_HOME}/etc/hadoop/yarn-site.xml [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# cat ${HADOOP_HOME}/etc/hadoop/yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>Reducer获取数据的方式</description> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop106.yinzhengjie.org.cn</value> <description>指定YARN的ResourceManager的地址</description> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description>启用或禁用日志聚合的配置,默认为false,即禁用,将该值设置为true,表示开启日志聚集功能使能</description> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> <description>删除聚合日志前要保留多长时间(默认单位是秒),默认值是"-1"表示禁用,请注意,将此值设置得太小,您将向Namenode发送垃圾邮件.</description> </property> <property> <name>yarn.log-aggregation.retain-check-interval-seconds</name> <value>3600</value> <description>单位为秒,检查聚合日志保留之间的时间.如果设置为0或负值,那么该值将被计算为聚合日志保留时间的十分之一;请注意,将此值设置得太小,您将向名称节点发送垃圾邮件.</description> </property> </configuration> [root@hadoop101.yinzhengjie.org.cn ~]#


[root@hadoop101.yinzhengjie.org.cn ~]# rsync-hadoop.sh ${HADOOP_HOME}/etc/hadoop/yarn-site.xml ******* [hadoop102.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/yarn-site.xml] ******* 命令执行成功 ******* [hadoop103.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/yarn-site.xml] ******* 命令执行成功 ******* [hadoop104.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/yarn-site.xml] ******* 命令执行成功 ******* [hadoop105.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/yarn-site.xml] ******* 命令执行成功 ******* [hadoop106.yinzhengjie.org.cn] node starts synchronizing [/yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/yarn-site.xml] ******* 命令执行成功 [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]#
3>.重启YARN和HistoryServer服务
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8737 NodeManager 9460 Jps 8198 DataNode hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8182 DataNode 8648 NodeManager 9372 Jps hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8456 SecondaryNameNode 9406 Jps hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8245 DataNode 8935 NodeManager 9751 Jps hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 15664 JobHistoryServer 16685 Jps 13214 NameNode hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 12427 ResourceManager 12893 JobHistoryServer 13438 Jps [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible rm -m shell -a 'stop-yarn.sh' hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> stopping yarn daemons stopping resourcemanager hadoop102.yinzhengjie.org.cn: stopping nodemanager hadoop102.yinzhengjie.org.cn: nodemanager did not stop gracefully after 5 seconds: killing with kill -9 hadoop104.yinzhengjie.org.cn: stopping nodemanager hadoop104.yinzhengjie.org.cn: nodemanager did not stop gracefully after 5 seconds: killing with kill -9 hadoop103.yinzhengjie.org.cn: stopping nodemanager hadoop103.yinzhengjie.org.cn: nodemanager did not stop gracefully after 5 seconds: killing with kill -9 no proxyserver to stop [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible rm -m shell -a 'mr-jobhistory-daemon.sh stop historyserver' hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> stopping historyserver [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible nn -m shell -a 'mr-jobhistory-daemon.sh stop historyserver' hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> stopping historyserver [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 17104 Jps 13214 NameNode hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8245 DataNode 9918 Jps hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8182 DataNode 9534 Jps hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9543 Jps 8456 SecondaryNameNode hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8198 DataNode 9623 Jps hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 13782 Jps [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible rm -m shell -a 'start-yarn.sh' hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> starting yarn daemons starting resourcemanager, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/yarn-root-resourcemanager-hadoop106.yinzhengjie.org.cn.out hadoop102.yinzhengjie.org.cn: starting nodemanager, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/yarn-root-nodemanager-hadoop102.yinzhengjie.org.cn.out hadoop103.yinzhengjie.org.cn: starting nodemanager, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/yarn-root-nodemanager-hadoop103.yinzhengjie.org.cn.out hadoop104.yinzhengjie.org.cn: starting nodemanager, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/yarn-root-nodemanager-hadoop104.yinzhengjie.org.cn.out [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible nn -m shell -a 'mr-jobhistory-daemon.sh start historyserver' hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> starting historyserver, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/mapred-root-historyserver-hadoop101.yinzhengjie.org.cn.out [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible rm -m shell -a 'mr-jobhistory-daemon.sh start historyserver' hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> starting historyserver, logging to /yinzhengjie/softwares/hadoop-2.10.0/logs/mapred-root-historyserver-hadoop106.yinzhengjie.org.cn.out [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# ansible all -m shell -a 'jps' hadoop101.yinzhengjie.org.cn | SUCCESS | rc=0 >> 17393 JobHistoryServer 17590 Jps 13214 NameNode hadoop103.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9969 NodeManager 8245 DataNode 10221 Jps hadoop105.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9670 Jps 8456 SecondaryNameNode hadoop104.yinzhengjie.org.cn | SUCCESS | rc=0 >> 9584 NodeManager 8182 DataNode 9836 Jps hadoop102.yinzhengjie.org.cn | SUCCESS | rc=0 >> 8198 DataNode 9926 Jps 9672 NodeManager hadoop106.yinzhengjie.org.cn | SUCCESS | rc=0 >> 13889 ResourceManager 14285 JobHistoryServer 14398 Jps [root@hadoop101.yinzhengjie.org.cn ~]#
4>.执行wordcount案例
[root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls / Found 4 items drwxr-xr-x - root supergroup 0 2020-03-12 16:20 /inputDir drwxr-xr-x - root supergroup 0 2020-03-12 16:54 /outputDir drwxrwx--- - root supergroup 0 2020-03-12 15:40 /tmp drwxrwx--- - root supergroup 0 2020-03-12 16:51 /yinzhengjie [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -rm -r /outputDir Deleted /outputDir [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls / Found 3 items drwxr-xr-x - root supergroup 0 2020-03-12 16:20 /inputDir drwxrwx--- - root supergroup 0 2020-03-12 15:40 /tmp drwxrwx--- - root supergroup 0 2020-03-12 16:51 /yinzhengjie [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls / Found 3 items drwxr-xr-x - root supergroup 0 2020-03-12 16:20 /inputDir drwxrwx--- - root supergroup 0 2020-03-12 15:40 /tmp drwxrwx--- - root supergroup 0 2020-03-12 16:51 /yinzhengjie [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls /inputDir Found 1 items -rw-r--r-- 3 root supergroup 60 2020-03-12 16:20 /inputDir/wc.txt [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls /inputDir/wc.txt -rw-r--r-- 3 root supergroup 60 2020-03-12 16:20 /inputDir/wc.txt [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -cat /inputDir/wc.txt yinzhengjie 18 bigdata bigdata java python java golang java [root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount /inputDir /outputDir
20/03/12 19:20:38 INFO client.RMProxy: Connecting to ResourceManager at hadoop106.yinzhengjie.org.cn/172.200.4.106:8032
20/03/12 19:20:39 INFO input.FileInputFormat: Total input files to process : 1
20/03/12 19:20:39 INFO mapreduce.JobSubmitter: number of splits:1
20/03/12 19:20:39 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
20/03/12 19:20:39 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1584011863930_0001
20/03/12 19:20:39 INFO conf.Configuration: resource-types.xml not found
20/03/12 19:20:39 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
20/03/12 19:20:39 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE
20/03/12 19:20:39 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE
20/03/12 19:20:39 INFO impl.YarnClientImpl: Submitted application application_1584011863930_0001
20/03/12 19:20:39 INFO mapreduce.Job: The url to track the job: http://hadoop106.yinzhengjie.org.cn:8088/proxy/application_1584011863930_0001/
20/03/12 19:20:39 INFO mapreduce.Job: Running job: job_1584011863930_0001
20/03/12 19:20:47 INFO mapreduce.Job: Job job_1584011863930_0001 running in uber mode : false
20/03/12 19:20:47 INFO mapreduce.Job: map 0% reduce 0%
20/03/12 19:20:52 INFO mapreduce.Job: map 100% reduce 0%
20/03/12 19:20:57 INFO mapreduce.Job: map 100% reduce 100%
20/03/12 19:20:57 INFO mapreduce.Job: Job job_1584011863930_0001 completed successfully
20/03/12 19:20:57 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=84
FILE: Number of bytes written=411077
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=181
HDFS: Number of bytes written=54
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2745
Total time spent by all reduces in occupied slots (ms)=2295
Total time spent by all map tasks (ms)=2745
Total time spent by all reduce tasks (ms)=2295
Total vcore-milliseconds taken by all map tasks=2745
Total vcore-milliseconds taken by all reduce tasks=2295
Total megabyte-milliseconds taken by all map tasks=2810880
Total megabyte-milliseconds taken by all reduce tasks=2350080
Map-Reduce Framework
Map input records=3
Map output records=9
Map output bytes=96
Map output materialized bytes=84
Input split bytes=121
Combine input records=9
Combine output records=6
Reduce input groups=6
Reduce shuffle bytes=84
Reduce input records=6
Reduce output records=6
Spilled Records=12
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=159
CPU time spent (ms)=1020
Physical memory (bytes) snapshot=501035008
Virtual memory (bytes) snapshot=4323725312
Total committed heap usage (bytes)=290455552
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=60
File Output Format Counters
Bytes Written=54
[root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]# hdfs dfs -ls /
Found 4 items
drwxr-xr-x - root supergroup 0 2020-03-12 19:20 /inputDir
drwxr-xr-x - root supergroup 0 2020-03-12 19:20 /outputDir
drwxrwx--- - root supergroup 0 2020-03-12 19:20 /tmp
drwxrwx--- - root supergroup 0 2020-03-12 16:51 /yinzhengjie
[root@hadoop101.yinzhengjie.org.cn ~]#
[root@hadoop101.yinzhengjie.org.cn ~]#
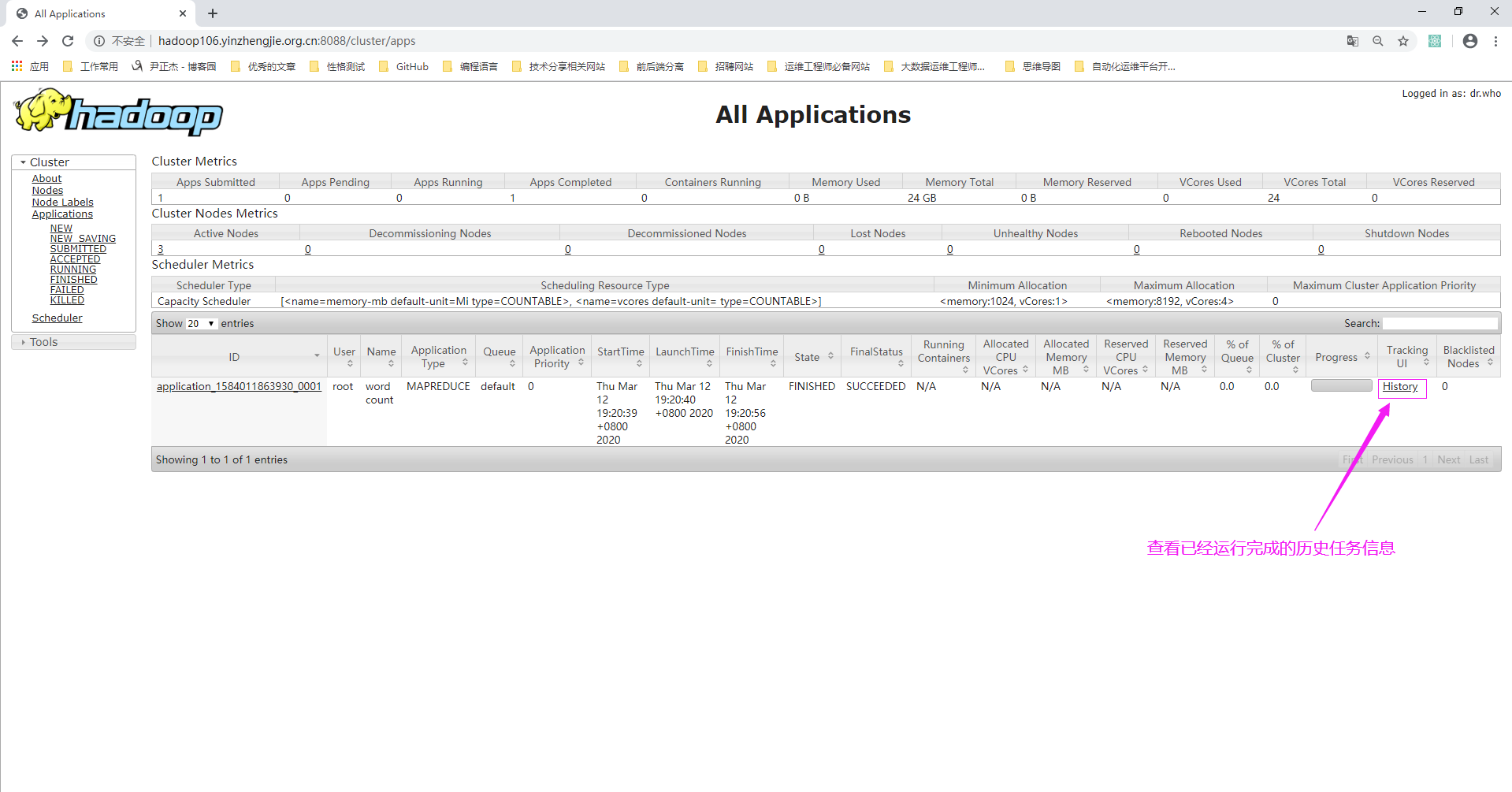
5>.点击“log”可以查看日志
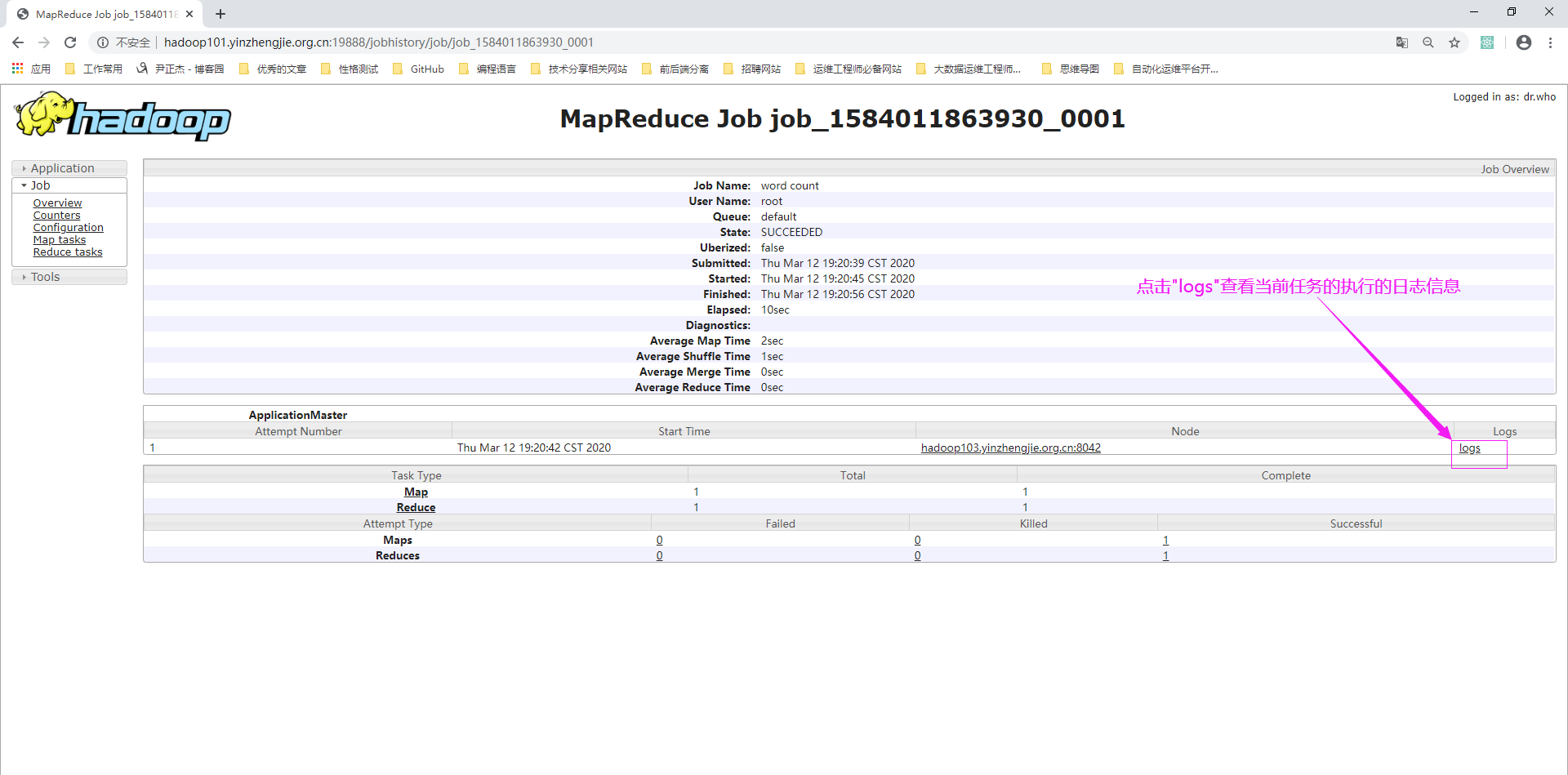
6>.在WebUI查看日志信息,如下图所示,点击"here"可以查看完整日志

7>.查看完整日志