Lucene是什么?
Lucene是一个开源的全文检索引擎工具包但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene是近几年最受欢迎的免费Java信息检索程序库,Lucene与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
什么是全文检索?
1.数据的分类
结构化数据: 也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理
非结构化数据: 非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、XML, HTML、各类报表、图像和音频/视频信息等等。
2.非结构化数据查询方法
(1)顺序扫描法(Serial Scanning)
比如说要在一堆文件了找某一个字符串,如果一个文档一个文档的看,从头看到尾的方式看,直到找完所有的文件为止
(2)全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。安装这种方式进行搜索的过程就叫全文检索。
Lucene实现全文检索的流程
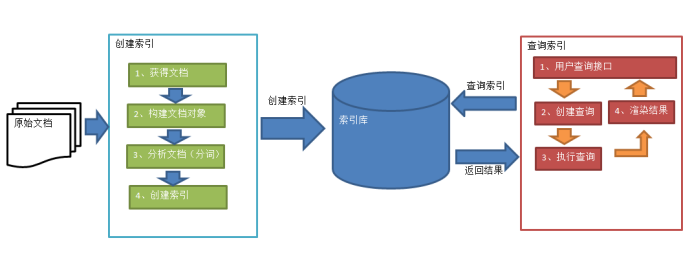
1.创建索引
1.1 获取文档
获得原始文档,要基于那些数据进行搜索,这些数据就是原始文档
如何获取原始文档:
1.搜索引擎:根据爬虫获得原始文档
2.站内搜索:基本上都是从数据库当中获取的,JDBC获取
3.磁盘文件:利用IO流读取
1.2 构建文档对象
每一个原始文档都是一个文档对象,比如磁盘文件,每一个文件就是一个文档对象,京东搜索,每一个商品就是一个文档对象
每一个文档对象当中包含多个域,域中存储文档信息,存储文档名称,文档路径,文档大小,文档内容,域中有两大部分:
域的名称name,域的值spring.txt key=value,每一个文档都有一个文档编号ID
1.3 分析文档(分词)
1.3.1 根据空格进行字符串拆分,得到单词列表
1.3.2 单词统一转换为小写或者大写,用户查询时,将查询内容也统一转换为大写或者小写
1.3.3 去掉标点
1.3.4 去除停用词(文档数据当中无意义的词,比如 the a )
1.3.5 得到分词结果之后,每一个关键词都封装成一个term对象,term对象包含两大部分:
1.关键词所在的域
2.关键词本身
不同的域查分出来相同的关键词是不同的term,比如从文件名和文件内容都拆分出来spring关键词,这两个spring是完全不同域的
1.4 创建索引
基于关键词列表创建一个索引,保存到索引库当中,一次创建多次使用
索引库:
1.索引
2.document对象
3.关键词和文档的对应关系,采用倒排索引结构
2.查询索引
2.1 用户查询接口:用户输入查询条件的地方,比如百度搜索框,jd商品搜索框
2.2 获取到关键词,获取到关键词后封装成一个查询对象
对象要的两个参数要查询的域,和要搜索的关键词
2.3 执行查询,根据查询的关键词和对应的域去查询
2.4 根据关键词和文档的对应关系,利用倒排索引结构,找到文档id,找到id后就能定位到文档
2.5 渲染结果
程序测试
引入maven依赖
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>7.4.0</version> </dependency> <!-- https://mvnrepository.com/artifact/commons-io/commons-io --> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.4</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>7.4.0</version> </dependency>
准备目标文件
创建索引
package com.yjc.test; import org.apache.commons.io.FileUtils; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.TextField; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.File; import java.io.IOException; /** * 创建索引 * */ public class CreateIndex { public static void main(String[] args) throws IOException { //指定索引库存放的路径 Directory directory = FSDirectory.open(new File("E:\Astudy\Tool\lucene\index").toPath()); //用于配置分词器 IndexWriterConfig config = new IndexWriterConfig(); IndexWriter indexWriter=new IndexWriter(directory,config); //原始文档的路径 File files =new File("E:\Astudy\Tool\lucene\data"); //遍历所有的文件 for (File f:files.listFiles()){ //文件名称 String fileName = f.getName(); System.out.println(fileName); //文件内容 String fileContent = FileUtils.readFileToString(f); //文件路径 String filePath = f.getPath(); //文件大小 long fileSize = FileUtils.sizeOf(f); //创建文件名域(方法参数:1.域的名称 2.域的内容 3.是否存储) Field fileNameField=new TextField("fileName",fileName,Field.Store.YES); //创建文件内容域 Field fileContentField=new TextField("fileContent",fileContent,Field.Store.YES); //文件路径域 Field filePathField=new TextField("filePath",filePath,Field.Store.YES); //创建文件大小域 Field fileSizeField=new TextField("fileSize",String.valueOf(fileSize),Field.Store.YES); //创建文档对象 Document document=new Document(); document.add(fileNameField); document.add(fileContentField); document.add(filePathField); document.add(fileSizeField); //创建索引并写入索引库 indexWriter.addDocument(document); } indexWriter.close(); } }
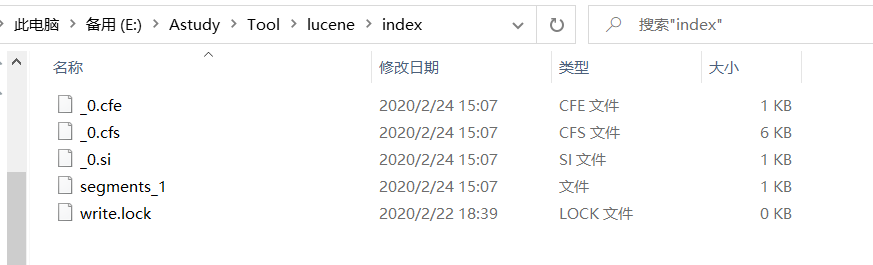
创建完成之后的效果大致如下
查询索引
package com.yjc.test; import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.search.*; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import java.io.File; import java.io.IOException; public class SearchIndex { public static void main(String[] args) throws IOException { //指定索引库存放的路径 Directory directory = FSDirectory.open(new File("E:\Astudy\Tool\lucene\index").toPath()); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher=new IndexSearcher(indexReader); //创建查询 //参数1为要搜索哪个域 2为搜索的关键字 Query query=new TermQuery(new Term("fileContent","lucene")); //执行查询 //参数1为查询对象 2为查询结果返回的最大值 TopDocs topDocs = indexSearcher.search(query, 10); //查询结果的总条数 System.out.println("总条数为:"+topDocs.totalHits); //遍历查询结果 for(ScoreDoc scoreDoc:topDocs.scoreDocs){ //scoreDoc.doc属性就是document对象的id Document document = indexSearcher.doc(scoreDoc.doc); System.out.println("文件名称----->"+document.get("fileName")); System.out.println("文件路径----->"+document.get("filePath")); System.out.println("文件大小----->"+document.get("fileSize")); System.out.println("文件内容----->"+document.get("fileContent")); System.out.println("==================这是一条分割线================================"); } indexReader.close(); } }
结果大致如下
