luke查看工具
链接:https://pan.baidu.com/s/1a2HB__SQLkYhiVLu-6aXZw 提取码:6m86
Field域属性分类

准备依赖
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>
创建索引
准备的源数据
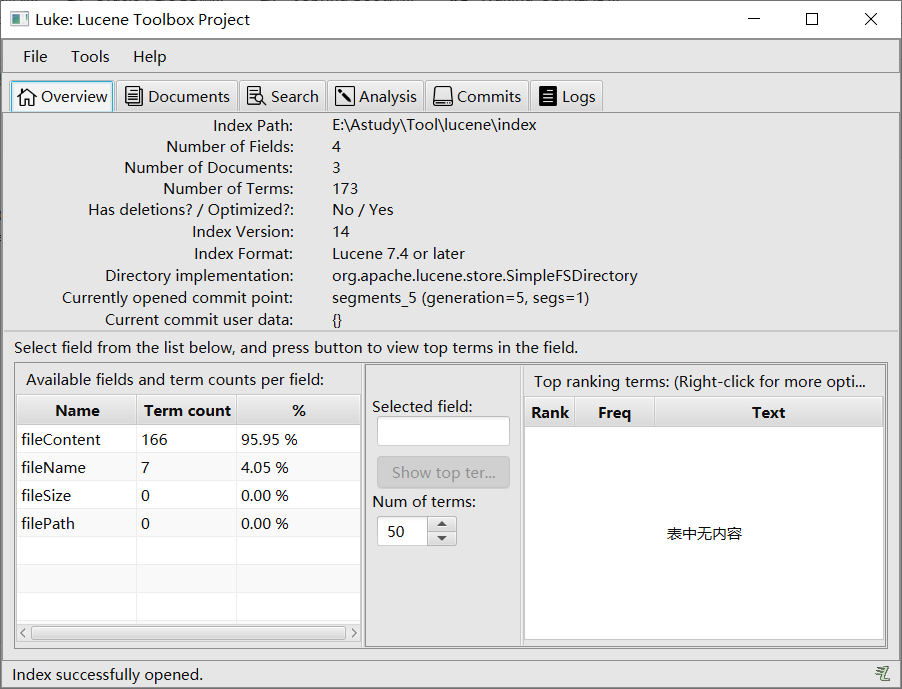
使用luke工具查看索引库

创建索引的代码
package com.yjc.test; import org.apache.commons.io.FileUtils; import org.apache.lucene.document.*; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.File; import java.io.IOException; /** * 创建索引 * */ public class CreateIndex { public static void main(String[] args) throws IOException { //指定索引库存放的路径 Directory directory = FSDirectory.open(new File("E:\Astudy\Tool\lucene\index").toPath()); //用于配置分词器 IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer()); IndexWriter indexWriter=new IndexWriter(directory,config); //原始文档的路径 File files =new File("E:\Astudy\Tool\lucene\data"); //遍历所有的文件 for (File f:files.listFiles()){ //文件名称 String fileName = f.getName(); System.out.println(fileName); //文件内容 String fileContent = FileUtils.readFileToString(f); //文件路径 String filePath = f.getPath(); //文件大小 long fileSize = FileUtils.sizeOf(f); //创建文件名域(方法参数:1.域的名称 2.域的内容 3.是否存储) Field fileNameField=new TextField("fileName",fileName,Field.Store.YES); //创建文件内容域 Field fileContentField=new TextField("fileContent",fileContent,Field.Store.YES); //文件路径域 Field filePathField=new StoredField("filePath",filePath); //创建文件大小域 Field fileSizeFieldStored=new StoredField("fileSize",fileSize); Field fileSizeFieldLongPoint=new LongPoint("fileSize",fileSize); //创建文档对象 Document document=new Document(); document.add(fileNameField); document.add(fileContentField); document.add(filePathField); document.add(fileSizeFieldStored); document.add(fileSizeFieldLongPoint); //创建索引并写入索引库 indexWriter.addDocument(document); } indexWriter.close(); } }
使用luke工具可以看出来一共有三个文档,四个域
删除索引
package com.yjc.test; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import java.io.File; import java.io.IOException; public class DeleteIndex { public static void main(String[] args) throws IOException { Directory directory = FSDirectory.open(new File("E:\Astudy\Tool\lucene\index").toPath()); IndexWriterConfig config = new IndexWriterConfig(); IndexWriter indexWriter=new IndexWriter(directory,config); //删除全部索引 indexWriter.deleteAll(); /* Query query = new TermQuery(new Term("fileContent", "c")); //根据查询条件删除对应的文档 indexWriter.deleteDocuments(query);*/ indexWriter.close(); } }
修改文档
就是将原文档删除,重新添加修改之后的文档
package com.yjc.test; import org.apache.lucene.document.*; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.Term; import org.apache.lucene.store.FSDirectory; import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.File; import java.io.IOException; public class UpdateIndex { public static void main(String[] args) throws IOException { //创建IndexWriter对象 参数一:索引库位置 参数二:指定配置 IndexWriter indexWriter=new IndexWriter(FSDirectory.open(new File("E:\Astudy\Tool\lucene\index").toPath()), new IndexWriterConfig(new IKAnalyzer())); //创建文档 Document document=new Document(); document.add(new TextField("fileName","new.txt", Field.Store.YES)); document.add(new StoredField("filePath","E:\Astudy\Tool\lucene\data")); document.add(new LongPoint("fileSize",699)); document.add(new StoredField("fileSize",699)); document.add(new TextField("fileContent","修改文档,就是将原文档删除,添加新的文档", Field.Store.YES)); //修改 参数一为条件 参数二为修改的文档值 indexWriter.updateDocument(new Term("fileName","test.txt"),document); //关闭 indexWriter.close(); } }
索引库查询
TermQuery:根据域和关键词进行搜索
package com.yjc.test; import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.search.*; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import java.io.File; import java.io.IOException; public class SearchIndex { public static void main(String[] args) throws IOException { //指定索引库存放的路径 Directory directory = FSDirectory.open(new File("E:\Astudy\Tool\lucene\index").toPath()); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher=new IndexSearcher(indexReader); //创建查询 //参数1为要搜索哪个域 2为搜索的关键字 Query query=new TermQuery(new Term("fileContent","lucene")); //执行查询 //参数1为查询对象 2为查询结果返回的最大值 TopDocs topDocs = indexSearcher.search(query, 10); //查询结果的总条数 System.out.println("总条数为:"+topDocs.totalHits); //遍历查询结果 for(ScoreDoc scoreDoc:topDocs.scoreDocs){ //scoreDoc.doc属性就是document对象的id Document document = indexSearcher.doc(scoreDoc.doc); System.out.println("文件名称----->"+document.get("fileName")); System.out.println("文件路径----->"+document.get("filePath")); System.out.println("文件大小----->"+document.get("fileSize")); System.out.println("文件内容----->"+document.get("fileContent")); System.out.println("==================这是一条分割线================================"); } indexReader.close(); } }

RangeQuery:范围搜索
前提是创建文档时保存范围
Field fileSizeFieldStored=new StoredField("fileSize",fileSize); Field fileSizeFieldLongPoint=new LongPoint("fileSize",fileSize); //创建文档对象 Document document=new Document(); document.add(fileSizeFieldStored); document.add(fileSizeFieldLongPoint);
package com.yjc.test; import org.apache.lucene.document.Document; import org.apache.lucene.document.LongPoint; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.search.*; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import java.io.File; import java.io.IOException; public class SearchIndex { public static void main(String[] args) throws IOException { //指定索引库存放的路径 Directory directory = FSDirectory.open(new File("E:\Astudy\Tool\lucene\index").toPath()); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher=new IndexSearcher(indexReader); //创建查询,参数一为要查找的域,23为大小区间 Query query = LongPoint.newRangeQuery("fileSize", 0, 1000); //执行查询 //参数1为查询对象 2为查询结果返回的最大值 TopDocs topDocs = indexSearcher.search(query, 10); //查询结果的总条数 System.out.println("总条数为:"+topDocs.totalHits); //遍历查询结果 for(ScoreDoc scoreDoc:topDocs.scoreDocs){ //scoreDoc.doc属性就是document对象的id Document document = indexSearcher.doc(scoreDoc.doc); System.out.println("文件名称----->"+document.get("fileName")); System.out.println("文件路径----->"+document.get("filePath")); System.out.println("文件大小----->"+document.get("fileSize")); System.out.println("文件内容----->"+document.get("fileContent")); System.out.println("==================这是一条分割线================================"); } indexReader.close(); } }
搜所结果如下

QueryParser:匹配一行数据,这一行数据会自动进行分词
QueryParser会把查询条件安装指定的方式进行分词,然后逐词查找
QueryParser需要导入特定的依赖,一般导入IKAnalyzer的依赖中就已经包含了
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>7.4.0</version> </dependency>
package com.yjc.test; import org.apache.lucene.document.Document; import org.apache.lucene.document.LongPoint; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.queryparser.classic.ParseException; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.*; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.File; import java.io.IOException; public class SearchIndex { public static void main(String[] args) throws IOException, ParseException { //指定索引库存放的路径 Directory directory = FSDirectory.open(new File("E:\Astudy\Tool\lucene\index").toPath()); IndexReader indexReader = DirectoryReader.open(directory); IndexSearcher indexSearcher=new IndexSearcher(indexReader); //创建查询 //参数1为要搜索哪个域 2为配置那种分析器 QueryParser queryParser = new QueryParser("fileContent",new IKAnalyzer()); //查询条件 Query query = queryParser.parse("lucene是一个开源框架"); //执行查询 //参数1为查询对象 2为查询结果返回的最大值 TopDocs topDocs = indexSearcher.search(query, 10); //查询结果的总条数 System.out.println("总条数为:"+topDocs.totalHits); //遍历查询结果 for(ScoreDoc scoreDoc:topDocs.scoreDocs){ //scoreDoc.doc属性就是document对象的id Document document = indexSearcher.doc(scoreDoc.doc); System.out.println("文件名称----->"+document.get("fileName")); System.out.println("文件路径----->"+document.get("filePath")); System.out.println("文件大小----->"+document.get("fileSize")); System.out.println("文件内容----->"+document.get("fileContent")); System.out.println("==================这是一条分割线================================"); } indexReader.close(); } }
查询结果
