1.MapReduce 理解
- 拆分成 map 过程与 reduce 过程;
- map 可以理解为sql 中的 group by 操作, reduce相当于group by 后的聚合计算 ;
- 一个map 必须对应一个 reduce
- map后会存在 hdfs 中,然后再进行 reduce
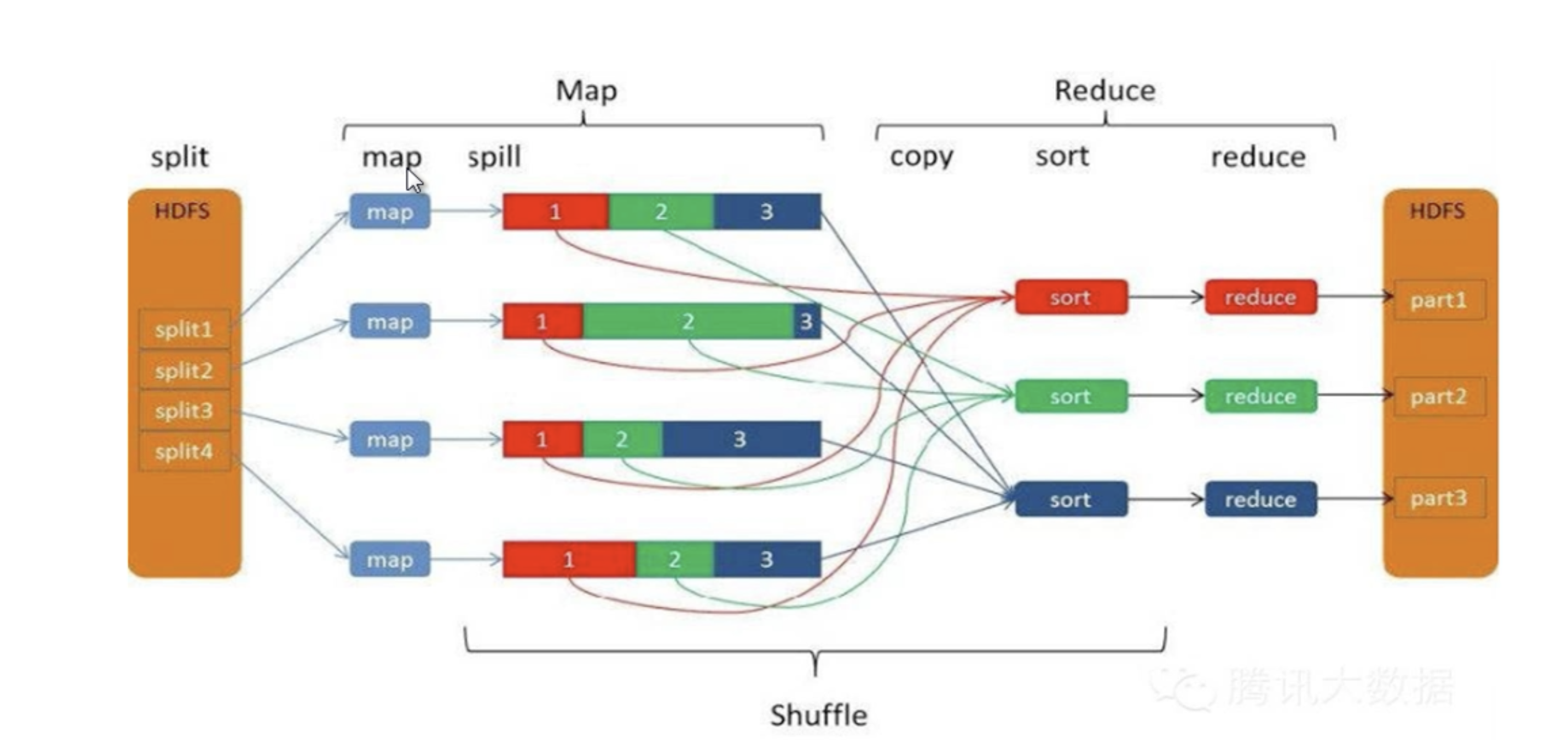
2.MapReduce 与 spark 对比
- 用hdfs来作为中间介质(map后的结果存储),spark是用内存来作为中间介质
- MapReduce不的支持流水线作业(就是reduce 必须等待map完后才能工作,不能像流水线一样,一边map,一边reduce)
- 不支持DAG计算 (MapReduce 一个Map对应一个Reduce, spark中 可以一次map多次 reduce)