一、多数据源问题
主要思路是把dataSource、sqlSesstionFactory、MapperScannerConfigurer在配置中区分开,各Mapper对应的包名、类名区分开
1 <?xml version="1.0" encoding="UTF-8"?> 2 <beans xmlns="http://www.springframework.org/schema/beans" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" 4 xmlns:tx="http://www.springframework.org/schema/tx" xmlns:jdbc="http://www.springframework.org/schema/jdbc" 5 xmlns:context="http://www.springframework.org/schema/context" 6 xsi:schemaLocation=" 7 http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd 8 http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd 9 http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc-3.0.xsd 10 http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.0.xsd 11 http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.0.xsd" 12 default-autowire="byName"> 13 14 <bean id="dataSource1" class="org.h2.jdbcx.JdbcConnectionPool" 15 destroy-method="dispose"> 16 <constructor-arg> 17 <bean class="org.h2.jdbcx.JdbcDataSource"> 18 <property name="URL" value="jdbc:h2:r:/h2db/awbprint/a"/> 19 <property name="user" value="sa"/> 20 <property name="password" value="sa"/> 21 </bean> 22 </constructor-arg> 23 </bean> 24 25 26 <bean id="dataSource2" class="org.h2.jdbcx.JdbcConnectionPool" 27 destroy-method="dispose"> 28 <constructor-arg> 29 <bean class="org.h2.jdbcx.JdbcDataSource"> 30 <property name="URL" value="jdbc:h2:r:/h2db/awbprint/b"/> 31 <property name="user" value="sa"/> 32 <property name="password" value="sa"/> 33 </bean> 34 </constructor-arg> 35 </bean> 36 37 <bean id="sqlSessionFactory1" class="org.mybatis.spring.SqlSessionFactoryBean"> 38 <property name="dataSource" ref="dataSource1"/> 39 <property name="configLocation" value="classpath:mybatis-config.xml"></property> 40 <property name="typeAliasesPackage" value="awbprint.mybatis.entity"></property> 41 <property name="mapperLocations" value="classpath:mybatis/a/**/*.xml"></property> 42 </bean> 43 44 <bean id="sqlSessionFactory2" class="org.mybatis.spring.SqlSessionFactoryBean"> 45 <property name="dataSource" ref="dataSource2"/> 46 <property name="configLocation" value="classpath:mybatis-config.xml"></property> 47 <property name="typeAliasesPackage" value="awbprint.mybatis.entity"></property> 48 <property name="mapperLocations" value="classpath:mybatis/b/**/*.xml"></property> 49 </bean> 50 51 <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> 52 <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory1"></property> 53 <property name="basePackage" value="awbprint.mybatis.mapper.a"/> 54 </bean> 55 56 <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> 57 <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory2"></property> 58 <property name="basePackage" value="awbprint.mybatis.mapper.b"/> 59 </bean> 60 61 62 </beans>
上面的配置,一个连h2的a数据库,一个连h2的b数据库,至于事务管理器,大家可参考这个思路,建二个,各管各的。
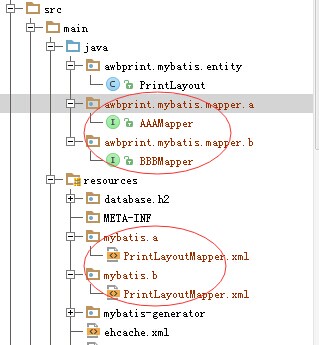
项目中mapper接口及映射文件均用包名区分开,如下图:
二、如何使用Map做为参数及动态条件生成
1 <resultMap id="BaseResultMap" type="awbprint.mybatis.entity.PrintLayout"> 2 <id column="D_RECID" property="recid" jdbcType="DECIMAL"/> 3 <result column="D_USER_NAME" property="userName" jdbcType="VARCHAR"/> 4 <result column="D_NAME" property="name" jdbcType="VARCHAR"/> 5 <result column="D_TYPE" property="type" jdbcType="VARCHAR"/> 6 ... 7 8 </resultMap> 9 10 <sql id="Base_Column_List"> 11 D_RECID, D_USER_NAME, D_NAME, D_TYPE, ... 12 </sql> 13 14 <select id="select" resultMap="BaseResultMap" 15 parameterType="java.util.Map"> 16 select 17 <include refid="Base_Column_List"/> 18 from T_PRINT_LAYOUT 19 where D_USER_NAME = #{userName,jdbcType=VARCHAR} and D_TYPE = #{awbType,jdbcType=VARCHAR} 20 <if test="recId != null"> 21 and D_RECID = #{recId,jdbcType=DECIMAL} 22 </if> 23 <if test="ids != null"> 24 or D_RECID in 25 <foreach item="item" index="index" collection="ids" 26 open="(" separator="," close=")"> 27 #{item} 28 </foreach> 29 </if> 30 31 </select>
14-31演示了如何使用Map做为参数,动态传入查询条件,及List参数生成in(...)条件
java端代码示例:
1 PrintLayoutMapper mapper = context.getBean(PrintLayoutMapper.class); 2 3 Map<String, Object> map = new HashMap<String, Object>(); 4 map.put("userName", "ADMIN"); 5 map.put("awbType", "CARGOLABEL_MU"); 6 map.put("recId", 1); 7 8 List<Integer> ids = new ArrayList<Integer>(); 9 ids.add(0, 1); 10 ids.add(0, 2); 11 ids.add(0, 3); 12 13 map.put("ids", ids); 14 15 List<?> list = mapper.select(map);
其实PrintLayoutMapper接口的定义为:
1 public interface PrintLayoutMapper { 2 ... 3 4 List<PrintLayout> select(Map<String, Object> map); 5 }
最终生成的SQL语句为:
1 select D_RECID, D_USER_NAME, D_NAME, D_TYPE, ... from T_PRINT_LAYOUT where D_USER_NAME = ? and D_TYPE = ? and D_RECID = ? or D_RECID in ( ? , ? , ? )
三、兼容不同的数据库
1 <insert id="insert"> 2 <selectKey keyProperty="id" resultType="int" order="BEFORE"> 3 <if test="_databaseId == 'oracle'"> 4 select seq_users.nextval from dual 5 </if> 6 <if test="_databaseId == 'db2'"> 7 select nextval for seq_users from sysibm.sysdummy1" 8 </if> 9 </selectKey> 10 insert into users values (#{id}, #{name}) 11 </insert>
这是官方文档上的示例,演示了如何兼容oracle与db2这二种不同的数据库,来获取序列的下一个值
四、加强版的分支、选择判断
1 <select id="findActiveBlogLike" 2 resultType="Blog"> 3 SELECT * FROM BLOG WHERE state = ‘ACTIVE’ 4 <choose> 5 <when test="title != null"> 6 AND title like #{title} 7 </when> 8 <when test="author != null and author.name != null"> 9 AND author_name like #{author.name} 10 </when> 11 <otherwise> 12 AND featured = 1 13 </otherwise> 14 </choose> 15 </select>
这也是官方文档上的示例,因为<if>...</if>并没对应的<else>标签,所以要达到<if>...<else>...</else> </if>的效果,得借助<choose>、<when>、<otherwise>组合使用。
五、避免Where 空条件的尴尬
1 <select id="findActiveBlogLike" resultType="Blog"> 2 SELECT * FROM BLOG 3 WHERE 4 <if test="state != null"> 5 state = #{state} 6 </if> 7 </select>
如果state参数为空时,最终生成SQL语句为
1 SELECT * FROM BLOG 2 WHERE
执行会出错,当然,你可以在where 后加一个1=1,改成
1 <select id="findActiveBlogLike" resultType="Blog"> 2 SELECT * FROM BLOG 3 WHERE 1=1 4 <if test="state != null"> 5 and state = #{state} 6 </if> 7 </select>
但是这个做法不太“环保”(毕竟引入了一个垃圾条件),其实只要改成<where>...</where>即可
1 <select id="findActiveBlogLike" resultType="Blog"> 2 SELECT * FROM BLOG 3 <where> 4 <if test="state != null"> 5 and state = #{state} 6 </if> 7 </where> 8 </select>
六、$与#的区别
1 select * from T_PRINT_LAYOUT where D_RECID = ${recId}
最后生成的SQL为:
1 select * from T_PRINT_LAYOUT where D_RECID = 1
即:直接将参数值替换到了原来${recId}的位置,相当于硬拼SQL
1 select * from T_PRINT_LAYOUT where D_RECID = #{recid,jdbcType=DECIMAL}
最后生成的SQL为:
1 select * from T_PRINT_LAYOUT where D_RECID = ?
即:#{...}被识别为一个SQL参数
七、大量数据的批量insert
大量数据(条数>10000)做insert时,如果按常规方式,每条insert into table(...) values(...);来提交,速度巨慢。改善性能的思路是多条insert批量提交。
oracle环境中,有一种批量insert的小技巧,原理是 insert into ... select from ...,套在mybatis上,变形为:
1 INSERT INTO T_TEST 2 (ID, COL_A, COL_B) 3 SELECT SEQ_TEST.NEXTVAL, A.* 4 FROM ( 5 SELECT 'A1', 'B1' FROM DUAL 6 UNION ALL SELECT 'A2', 'B2' FROM DUAL 7 UNION ALL SELECT 'A3', 'B3' FROM DUAL 8 UNION ALL SELECT 'A4', 'B4' FROM DUAL 9 UNION ALL SELECT 'A5', 'B5' FROM DUAL 10 UNION ALL SELECT 'A6', 'B6' FROM DUAL 11 ) A
中间的部分非常有规律,可以用foreach标签生成,参考下面的片段:
1 <insert id="insertBatch2" parameterType="ctas.entity.SharkFlt"> 2 <selectKey keyProperty="recId" order="BEFORE" resultType="Long"> 3 select SEQ_CTAS_SHARK_FLT.nextval as recId from dual 4 </selectKey> 5 insert into CTAS_SHARK_FLT (<include refid="Base_Column_List"/>) SELECT SEQ_TEST.NEXTVAL, A.* 6 FROM ( 7 <foreach collection="list" item="item" index="index" open="" close="" separator="union all"> 8 select #{item.awbType,jdbcType=VARCHAR}, #{item.awbPre,jdbcType=VARCHAR},... from dual 9 </foreach> 10 ) A 11 </insert>
即使这样,也不能直接run,oracle中一次执行的sql语句长度是有限制的,如果最后拼出来的sql字符串过长,会导致执行失败,所以java端还要做一个分段处理,参考下面的处理:
1 List<SharkFlt> data = new ArrayList<SharkFlt>(); 2 for (TSharkFlt f : sharkFlts) { 3 data.add(getSharkFlt(f)); 4 } 5 6 System.out.println(data.size()); 7 8 long beginTime = System.currentTimeMillis(); 9 System.out.println("开始插入..."); 10 SqlSessionFactory sqlSessionFactory = ctx.getBean(SqlSessionFactory.class); 11 SqlSession session = null; 12 try { 13 session = sqlSessionFactory.openSession(ExecutorType.BATCH, false); 14 int a = 2000;//每次提交2000条 15 int loop = (int) Math.ceil(data.size() / (double) a); 16 17 List<SharkFlt> tempList = new ArrayList<SharkFlt>(a); 18 int start, stop; 19 for (int i = 0; i < loop; i++) { 20 tempList.clear(); 21 start = i * a; 22 stop = Math.min(i * a + a - 1, data.size() - 1); 23 System.out.println("range:" + start + " - " + stop); 24 for (int j = start; j <= stop; j++) { 25 tempList.add(data.get(j)); 26 } 27 session.insert("ctas.importer.writer.mybatis.mappper.SharkFltMapper.insertBatch2", tempList); 28 session.commit(); 29 session.clearCache(); 30 System.out.println("已经插入" + (stop + 1) + " 条"); 31 } 32 } catch (Exception e) { 33 e.printStackTrace(); 34 session.rollback(); 35 } finally { 36 if (session != null) { 37 session.close(); 38 } 39 } 40 long endTime = System.currentTimeMillis(); 41 System.out.println("插入完成,耗时 " + (endTime - beginTime) + " 毫秒!");
13,27-29这几行是关键,这一段逻辑会经常使用,为了重用,可以封装一下:
1 /** 2 * 批量提交数据 3 * @param sqlSessionFactory 4 * @param mybatisSQLId SQL语句在Mapper XML文件中的ID 5 * @param commitCountEveryTime 每次提交的记录数 6 * @param list 要提交的数据列表 7 * @param logger 日志记录器 8 */ 9 private <T> void batchCommit(SqlSessionFactory sqlSessionFactory, String mybatisSQLId, int commitCountEveryTime, List<T> list, Logger logger) { 10 SqlSession session = null; 11 try { 12 session = sqlSessionFactory.openSession(ExecutorType.BATCH, false); 13 int commitCount = (int) Math.ceil(list.size() / (double) commitCountEveryTime); 14 List<T> tempList = new ArrayList<T>(commitCountEveryTime); 15 int start, stop; 16 Long startTime = System.currentTimeMillis(); 17 for (int i = 0; i < commitCount; i++) { 18 tempList.clear(); 19 start = i * commitCountEveryTime; 20 stop = Math.min(i * commitCountEveryTime + commitCountEveryTime - 1, list.size() - 1); 21 for (int j = start; j <= stop; j++) { 22 tempList.add(list.get(j)); 23 } 24 session.insert(mybatisSQLId, tempList); 25 session.commit(); 26 session.clearCache(); 27 } 28 Long endTime = System.currentTimeMillis(); 29 logger.debug("batchCommit耗时:" + (endTime - startTime) + "毫秒"); 30 } catch (Exception e) { 31 logger.error("batchCommit error!", e); 32 e.printStackTrace(); 33 session.rollback(); 34 } finally { 35 if (session != null) { 36 session.close(); 37 } 38 } 39 }
对应的,如果是批量update,也是类似的思路,只不过要注意一点:oracle环境中,多条语句提交的sql语句为
begin
update xxx set xxx =xxx ;
update xxx set xxx =xxx;
end;
用mytais拼的时候,参考下面的写法:
1 <update id="updateBatch" parameterType="java.util.List"> 2 <foreach collection="list" item="item" index="index" open="begin" close="end;" > 3 update xxx set x=#{item.x,jdbcType=VARCHAR} where x =#{item.x,jdbcType=VARCHAR}; 4 </foreach> 5 </update>
关于批量提交的性能,Oracle环境下,我大概测试了一下:
insert into ... select xxx
union all select yyy
union all select zzz;
最快,其次是
begin
insert into ... values ...;
insert into ... values ...;
end;
当然最慢是逐条insert提交,最后谈下Spring与mybatis集成后,AOP事务管理 对 批量提交的影响 ,通常情况下,我们会这样配置AOP事务管理:
1 <tx:advice id="txAdvice" transaction-manager="transactionManager"> 2 <tx:attributes> 3 <tx:method name="do*" read-only="false" rollback-for="java.lang.Exception"/> 4 <tx:method name="*" propagation="SUPPORTS" read-only="true"/> 5 </tx:attributes> 6 </tx:advice> 7 8 <aop:config> 9 <aop:pointcut id="pc" expression="execution(* ctas.service.*.*(..))"/> 10 <aop:advisor pointcut-ref="pc" advice-ref="txAdvice"/> 11 </aop:config>
这样,ctas.service(及子包)下的所有方法都被拦截,而且只有do开头的方法,具有可写的事务(即:能insert/update/delete记录),而其它方法是只读事务(即:只能select数据),但是我们前面谈到的批量提交操作,都是写代码手动提交的,不需要spring管理,所以配置中需要将某些方法排除,可以约定self开头的方法,由开发者自己管理事务,不需要spring代为管理,上面的配置要改成:
1 <aop:config> 2 <aop:pointcut id="pc" expression="execution(* ctas.service.*.*(..)) and !execution(* ctas.service.*.self*(..)))"/> 3 <aop:advisor pointcut-ref="pc" advice-ref="txAdvice"/> 4 </aop:config>
通过 and !execution(...) 将self开头的方法排除就可以了,前面的批量操作代码写到selfXXX方法中。
关于批量提交,还有一种情况:父子表的批量插入。思路还是一样的,但是SQL的写法有点区别,原理参考下面的语句(Oracle环境)
1 DECLARE 2 BASE_ID INTEGER; 3 DETAIL_ID INTEGER; 4 BEGIN 5 --第1组记录 6 SELECT SEQ_T_BASE.NEXTVAL INTO BASE_ID FROM DUAL; 7 INSERT INTO T_BASE (ID, FEE) VALUES (BASE_ID, ?); 8 9 SELECT SEQ_T_DETAIL.NEXTVAL INTO DETAIL_ID FROM DUAL; 10 INSERT INTO T_DETAIL (ID, BASE_ID, FEE) VALUES (DETAIL_ID, BASE_ID, ?); 11 SELECT SEQ_T_DETAIL.NEXTVAL INTO DETAIL_ID FROM DUAL; 12 INSERT INTO T_DETAIL (ID, BASE_ID, FEE) VALUES (DETAIL_ID, BASE_ID, ?); 13 14 --第2组记录 15 SELECT SEQ_T_BASE.NEXTVAL INTO BASE_ID FROM DUAL; 16 INSERT INTO T_BASE (ID, FEE) VALUES (BASE_ID, ?); 17 18 SELECT SEQ_T_DETAIL.NEXTVAL INTO DETAIL_ID FROM DUAL; 19 INSERT INTO T_DETAIL (ID, BASE_ID, FEE) VALUES (DETAIL_ID, BASE_ID, ?); 20 SELECT SEQ_T_DETAIL.NEXTVAL INTO DETAIL_ID FROM DUAL; 21 INSERT INTO T_DETAIL (ID, BASE_ID, FEE) VALUES (DETAIL_ID, BASE_ID, ?); 22 23 --... 24 END;
xml映射文件中的写法:
1 <insert id="insertBatch" parameterType="java.util.List"> 2 DECLARE 3 base_id INTEGER ; 4 detail_id INTEGER ; 5 <foreach collection="list" item="item" index="index" open="begin" close="end;"> 6 select seq_t_base.nextval into base_id from dual; 7 insert into t_base(id, fee) values(base_id, #{item.baseEntity.fee,jdbcType=DECIMAL}); 8 <foreach collection="item.details" item="detail" index="index"> 9 select seq_t_detail.nextval into detail_id from dual; 10 insert into t_detail(id, base_id, fee) values(detail_id,base_id,#{detail.fee,jdbcType=DECIMAL}); 11 </foreach> 12 </foreach> 13 </insert>
List中的Dto定义
1 public class BaseDetailDto { 2 3 private TBase baseEntity; 4 5 private List<TDetail> details; 6 7 public TBase getBaseEntity() { 8 return baseEntity; 9 } 10 11 public void setBaseEntity(TBase baseEntity) { 12 this.baseEntity = baseEntity; 13 } 14 15 16 public List<TDetail> getDetails() { 17 return details; 18 } 19 20 public void setDetails(List<TDetail> details) { 21 this.details = details; 22 } 23 }