snowflake做为一个轻量级的分布式id生成算法,已经被广泛使用,大致原理如下:
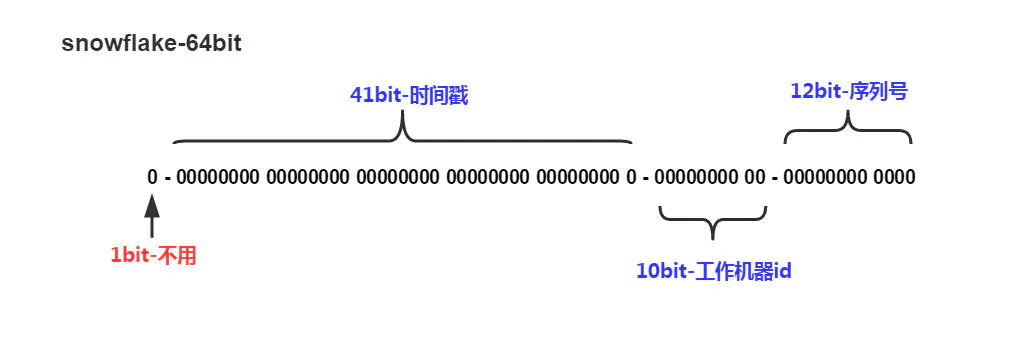
中间10位工作机器id(即:workerId),从图上可以知道,最多2^10次方,即1024台机器
最右侧12位序列号,2^12次方,即:4096
理论上,如果部署1024台机器,1ms内最多可生成1024*4096 = 4194304(约400万) 个id ,大多数应用场景中已经足够了。
根据这个思路,有很多语言版本的实现,下面是java版本:
public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 10; //机器标识占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long TIMESTMP_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
public SnowFlake(long machineId) {
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(0);
for (int i = 0; i < (1 << 12); i++) {
System.out.println(snowFlake.nextId());
}
}
}
结合前面提到的原理可知,集群部署环境下每台机器的应用启动时,初始化SnowFlake应该指定集群内唯一的workerId,否则如果每个机器上的workerId都一样,就有可能生成重复的id(即:相当于集群中,只有一个workerId,这样同1ms内,最多也就生成4096个id,这在高并发业务系统中,是很容易达到的)。
很多朋友都知道,机器上的ip可以转换成int数据,很容易想到,由于每台机器的ip不同(至少同1集群中不会重复),将ip转换出来的数字,对worker上限总数取模(注:worker总数只要小于1024即可,比如假设集群部署的机器,不会超过512台,就可以指定worker总数为 512),用这个取模的结果做为workerId似乎是一个不错的选择(事实上有的项目就是这么干的),上线后,大概率也能平稳运行。
但是!现在很多项目都是跑在云上(或k8s集群中),分布式环境中容器出现问题被重启是不可避免的,而且机器重启后通常ip也会变化。可能有一天会突然发现,snowflake生成的id出现了重复,但是代码并没有做过任何变更!
隐患就在于上面提到的ip取模算法,先给出ip转换成int的方法(网上copy来的):
public class IpUtils {
// 将127.0.0.1形式的IP地址转换成十进制整数,这里没有进行任何错误处理
public static long ipToLong(String strIp) {
long[] ip = new long[4];
// 先找到IP地址字符串中.的位置
int position1 = strIp.indexOf(".");
int position2 = strIp.indexOf(".", position1 + 1);
int position3 = strIp.indexOf(".", position2 + 1);
// 将每个.之间的字符串转换成整型
ip[0] = Long.parseLong(strIp.substring(0, position1));
ip[1] = Long.parseLong(strIp.substring(position1 + 1, position2));
ip[2] = Long.parseLong(strIp.substring(position2 + 1, position3));
ip[3] = Long.parseLong(strIp.substring(position3 + 1));
return (ip[0] << 24) + (ip[1] << 16) + (ip[2] << 8) + ip[3];
}
// 将十进制整数形式转换成127.0.0.1形式的ip地址
public static String longToIP(long longIp) {
StringBuffer sb = new StringBuffer("");
// 直接右移24位
sb.append(String.valueOf((longIp >>> 24)));
sb.append(".");
// 将高8位置0,然后右移16位
sb.append(String.valueOf((longIp & 0x00FFFFFF) >>> 16));
sb.append(".");
// 将高16位置0,然后右移8位
sb.append(String.valueOf((longIp & 0x0000FFFF) >>> 8));
sb.append(".");
// 将高24位置0
sb.append(String.valueOf((longIp & 0x000000FF)));
return sb.toString();
}
}
如果worker总数最大为512,看看下面2个ip,按前面的思路,取模后的结果如何:
long p1 = IpUtils.ipToLong("10.47.130.37");
long p2 = IpUtils.ipToLong("10.96.184.37");
int workerCount = 512;
System.out.println(p1 % workerCount);
System.out.println(p2 % workerCount);
将得到2个37,也就是这2台机器生成相同的workerId,所以它俩在并发高的情况下,有就较大概率生成相同的id,而且这个bug还挺难查的,可能机器一重启,又正常了(因为ip变了),如果只是偶尔出现,还会让人误以为是“时钟回拨”问题。
那么,合理的做法应该如何设置workerId呢?可以借助redis,对集群内的机器在应用启动时做一个workerId的全局登记,流程图如下:
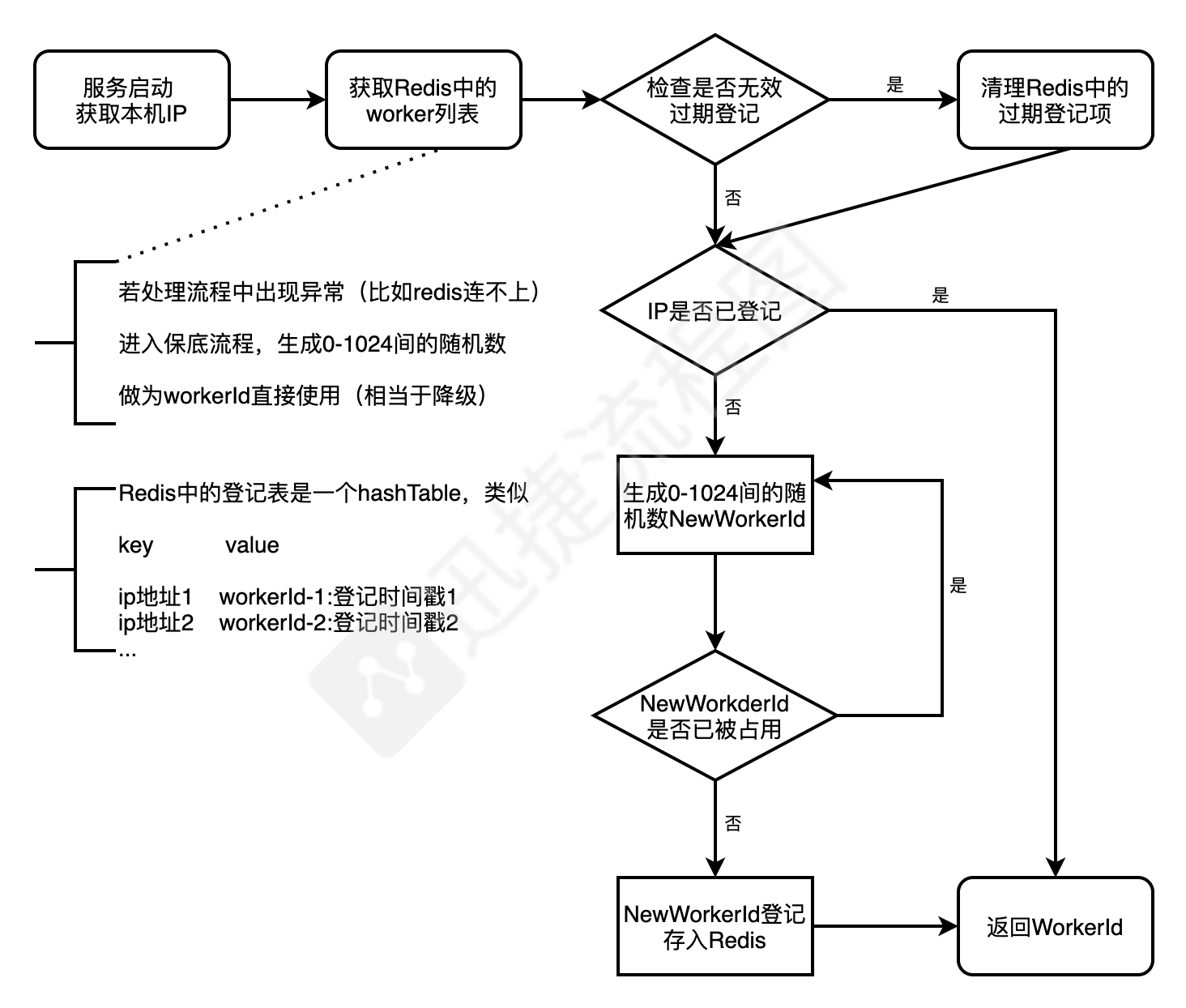
注1:因为容器随时可能被销毁,如果机器没了,登记表里的记录就没用了,相当于成了脏数据,所以检查过程中,有一步清理过期记录就是用来干这个的(判断是否过期记录,可借助“登记时间戳”来判断,比如3个月前登记的认为是无效的)
注2:意外情况下,比如启动时正好redis发生故障连不上,可以考虑降级为随机生成1个workerId先用着(视业务场景酌情而定)
最后,顺便提一句,如果考虑到时钟回拨问题,可以使用一些大厂的改进版本,比如百度的uid-generator ,或美团的leaf