1、定义:什么是LSTM?
首先,我们知道最基础的神经网络是【全连接神经网络】,keras里为,dense层。Dense就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。其中activation是逐元素计算的激活函数,kernel是本层的权值矩阵,bias为偏置向量,只有当use_bias=True才会添加。
然后是 卷积神经网络。卷积神经网络主要用在图片上,将一张很大的图片提取出图片的特征,其中还涉及了padding。
他们在处理【前一个输入】和【后一个输入】是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列;当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
这时,就需要用到深度学习领域中另一类非常重要神经网络:循环神经网络(Recurrent Neural Network)
但是传统的RNN有一个重大缺陷,就是在前向传播的过程当中会出现梯度消失的问题,梯度消失会导致一句话如果比较长,第一个字到后面的时候,都已经被忘记了。
所以引入了LSTM,LSTM相当于RNN的改进版。
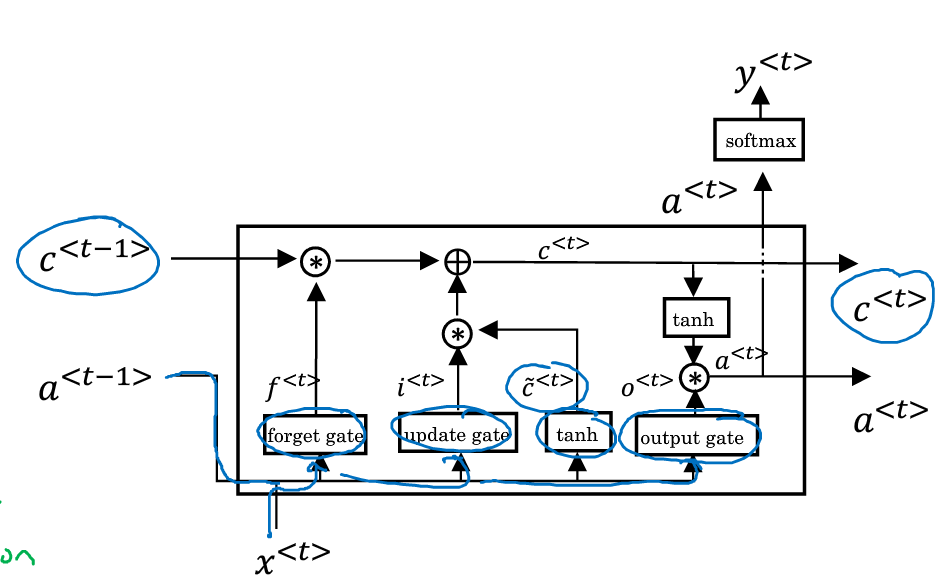
【注意】一个LSTM单元,也就是一层LSTM,我们在图示中经常会根据T展开,但是他们其实是同一层LSTM。
a<t>在其他地方经常写成h<t>,及隐藏层的输出
【keras中LSTM的参数】:
units: 是output size, 也就是hidden layer的神经元数量
#units: 是output size, 也就是hidden layer的神经元数量,也就是隐藏层输出的size
units = 2
from keras.models import Model
from keras.layers import Input
from keras.layers import LSTM
from numpy import array
# define model
inputs1 = Input(shape=(5, 1))
lstm1 = LSTM(units)(inputs1)
model = Model(inputs=inputs1, outputs=lstm1)
# define input data
data = array([0.1, 0.2, 0.3,0.4,0.5]).reshape((1,5,1))
# make and show prediction
print(model.predict(data))
#========================
#return_sequence=True (默认是False)
#则会输出每个时序输出的hidden_state_output
units = 2
from keras.models import Model
from keras.layers import Input
from keras.layers import LSTM
from numpy import array
# define model
inputs1 = Input(shape=(5, 1))
lstm1 = LSTM(units, return_sequences=True)(inputs1)
model = Model(inputs=inputs1, outputs=lstm1)
# define input data
data = array([0.1, 0.2, 0.3,0.4,0.5]).reshape((1,5,1))
# make and show prediction
print(model.predict(data))
#========================
#如果是return_state=True
【注意!!!!!!!!!】
LSTM的输出,称之为hidden_state。简写h,也就是NG说的a,但是这个其实非常容易混淆
因为LSTM还保留了另外一个记忆cell的状态,简写为c
一般来说,我们不需要接触c,但是在一些复杂模型,比如seq2seq的模型里,需要用t-1时刻的c来初始化t时刻的c
#如果是return_state=True,而return_sequence=True
#这个时候我们就知道,为什么上一个例子,同样的output需要输出两次。
#因为return_sequence=True,是针对于整个output,也就是
#lstm1 = LSTM(units, return_sequences=True)(inputs1)
#中的lstm1,而如果进行了return_state, 则state_h就是最后一刻的输出,而state_c是 c
from keras.models import Model
from keras.layers import Input
from keras.layers import LSTM
from numpy import array
# define model
inputs1 = Input(shape=(5, 1))
lstm1, state_h, state_c = LSTM(2, return_sequences=True, return_state=True)(inputs1)
model = Model(inputs=inputs1, outputs=[lstm1, state_h, state_c])
# define input data
data = array([0.1, 0.2, 0.3,0.4,0.5]).reshape((1,5,1))
# make and show prediction
print(model.predict(data))
#注意,predict data之后,输出的是3个东西
=============特别注释=================
1、state_c不是一个值,它的维度和state_h一样,是unit是数量
2、 上一次的状态 h(t-1)是怎么和下一次的输入 x(t) 结合(concat)起来的,这也是很多资料没有明白讲的地方,也很简单,concat, 直白的说就是把二者直接拼起来。
比如 x是28位的向量,h(t-1)是128位的,那么拼起来就是156位的向量,就是这么简单。