一、变量
Variables are used to store information to be referenced and manipulated in a computer program. They also provide a way of labeling data with a descriptive name, so our programs can be understood more clearly by the reader and ourselves. It is helpful to think of variables as containers that hold information. Their sole purpose is to label and store data in memory. This data can then be used throughout your program.
声明变量:
name = "Silence" #次代码声明了一个变量,变量名为: name,变量name的值为:"Silence"
tips:在Python中单行注释用 #注释内容
多行注释用 '''注释内容'''
变量定义的规则:
1、变量名只能是字母、数字或下划线的任意组合
2、变量名的第一个字符不能是数字
3、标识符名称是对大小写敏感的。例如, myname 和 myName 不是一个标识符。注意前者中的小写 n 和后者中的大写 N 。
tips:变量是标识符的例子。标识符是用来标识某样东西的名字。
4、以下关键字不能声明为变量名:
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
变量赋值:
name = "Silence_IOT"
name2 = name
print(name,name2)
二、字符编码
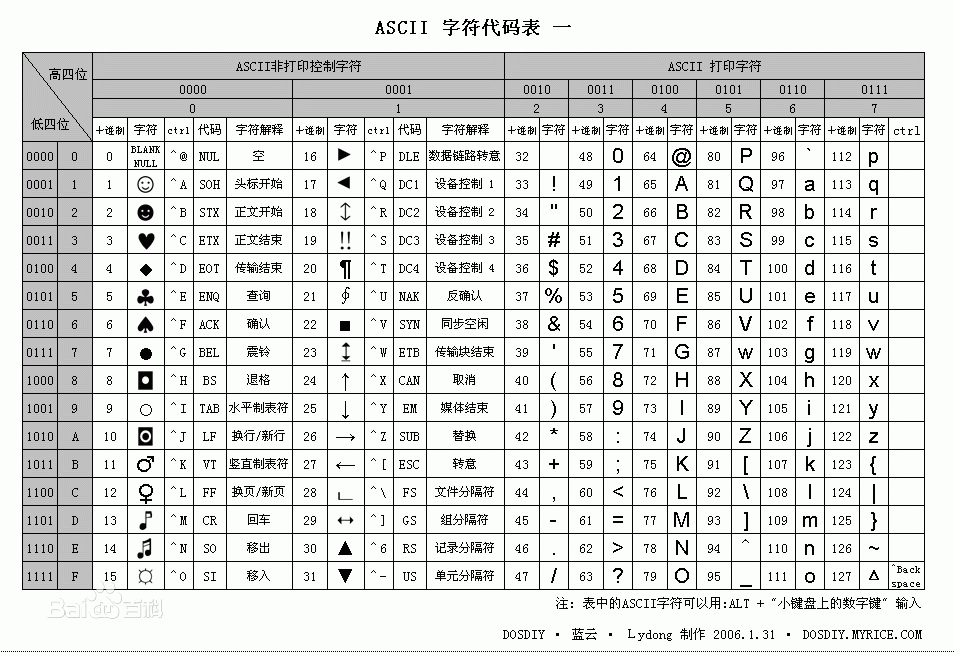
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
三、用户输入
name = input("What is your name?")
print("Hello ", name )
输入密码时,如果想要不可见(就像Linux里面输入密码的时候一样),需要利用getpass 模块中的 getpass方法,即:
import getpass # 将用户输入的内容赋值给 name 变量 pwd = getpass.getpass("请输入密码:") # 打印输入的内容 print(pwd)
tips:getpass模块在PyCharm中不好使(程序会卡住),其他地方绝对好使
四、.pyc文件
1、解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解
释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
2、简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
五、数据类型
1、数字
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 乘以10的-4次方。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,学过数学的人都知道。
int (整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。 注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
2、布尔值
真或假
1 或 0
True 或 False
3、字符串
特性:不可修改
username = input("username:")
password = input("password:")
age = int(input("age:")) #强制类型转换
print(type(age))
info = '''
------username %s-------
username:%s
password:%s
age:%d
''' % (username, username, password, age)
info2 = '''
------username2 {_username}-------
username:{_username}
password:{_password}
age:{_age}
'''.format(_username = username,
_password = password,
_age = age)
info3 = '''
------username3 {0}-------
username:{0}
password:{1}
age:{1}
'''.format(username, password, age)
print(info3)
print("{0}dada{1}".format(name, age))
ID = "001"
print("2015", ID, "3921") #这样也可以
个人推荐使用info3方式的格式打印!!!
字符串常用功能:
name = "my name is Silence_IOT"
print(name.capitalize()) #首字母大写
print(name.count('i')) #求个数
print(name.center(50, '-')) #总共50个字符,把原字符串放中间,两边用-补齐
print(name.endswith("ei")) #判断是不是以“ei”结尾
print(name.find("name")) #返回索引
print(name[3:9]) #切片 返回第3个字符到第8个字符
print(name[3:]) #切片 返回从第3个字符到结束
#print(name[name.find("name"):]) #切片
#print(name.expandtabs(tabsize=30)) #
names = "my name is {name},{years} old"
print(names.format(name='alex', years=18))
print(names.format_map({"name": "Silence_IOT", 'years': '18'})) #单引号、双引号没多大区别
print("123ad".isalnum()) #判断是否为字母加数字
print("ad".isalpha()) #判断是否为纯英文字母
print("_ad".isidentifier()) #判断是否为合法标识符
print("123".isnumeric())
print("1".isdigit()) #判断是否为纯数字,有小数点都不行
print("123".isdecimal()) #判断是否为纯十进制数字
print("My Name Is".istitle()) #判断是否为标题,即每个单词第一个是否大写
print("MY NAME".isupper()) #判断是否都是大写
print("+".join(["asd", '2', '3'])) #结果asd+2+3
print(name.ljust(30, '+')) #结果my name is yanglei+++++++++++
print(name.rjust(30, '-')) #结果-----------my name is yanglei
print(name.lower()) #全部变小写
print(name.upper())
print("1
Alex".lstrip()) #从左边开始去掉空格和回车
print("Alex
1".rstrip()) #从右边开始去掉空格和回车
print("
Alex
".strip()) #去掉空格和回车
p = str.maketrans("adcdefghij", "0123456789") #加密
print(name.translate(p)) #结果my n0m4 8s y0n6l48
print("alex li".replace('li', 'L', 1)) #替换 #结果aLex Li
print("alex li".rfind('l')) #查找最右边出现的那个元素的下标值 #结果5
print("alex li".find('l'))
print("alex-li".split('-')) #分割 #结果 ['alex', 'li']
print("al20ex
li".splitlines()) #按换行符分割 #结果 ['alex', 'li']
print("Alex-Li".swapcase()) #大小写反转 #结果 aLEX-lI
print("alex li".title()) #把字符串变成title #结果 Alex Li
print("alex li".zfill()) #结果 0000000000000alex li
4、列表
创建列表:name_list = ['alex', 'seven', 'eric']
或
name_list = list(['alex', 'seven', 'eric'])列表基本操作:
import copy
#列表可以多层嵌套
names = ["YangLei", "ZhangYang",["YL", ["001010"], "OP"], "LiJie", "GuYun", "123"]
#增
names.append("Leijun") #插入列表最后面
names.insert(1, "MaYun") #将“MaYun”插入到下标为1的位置上
#删
names.remove("GuYun") #删除"GuYun"这一项
#del names[2] <--> names.pop(2) #带下标数字两者相等
names.pop() #不带下标数字,删除列表最后一个元素
#修改
names[2] = "123"
#查找
print(names)
print(names.index("123")) #查找某元素的位置
#print(names[names.index("123")])
print(names.count("123")) #查找某元素的数量 (列表里面的元素可以相同)
list = [1, 33, 44, 456, 33]
list.reverse() #反转列表元素的顺序
print(list) #[33, 456, 44, 33, 1]
list.sort() #排序,按照Ascll码排序
print(list) #[1, 33, 33, 44, 456]
names2 = [1,2,3,4]
list.extend(names2) #把集合names添加到集合list 里面
print(list) #[1, 33, 33, 44, 456, 1, 2, 3, 4]
list2 = ["YangLei", "ZhangYang",["YL", ["001010"], "OP"], "LiJie", "GuYun", "123"]
#names3 = copy.deepcopy(names) #深copy,数据全部不共享,就是完全复制一份独立的数据 要import copy模块
names3 = list2.copy() #浅copy,数据半共享,只复制第一层数据,第一层数据不变,深层的数据还是引用原始数据
list2[1] = "11111111"
list2[2][1] = "22222"
print(list2) #['YangLei', '11111111', ['YL', '22222', 'OP'], 'LiJie', 'GuYun', '123']
print(names3) #['YangLei', 'ZhangYang', ['YL', '22222', 'OP'], 'LiJie', 'GuYun', '123']
list3 = [1, 44, 44, 545, 246, 4566, 55]
print(list3[0:-1:2]) #切片[起始位置:结尾位置:间隔项数(n-1)] [1, 44, 246]
print(list3[::3]) #每隔2项去一次 [1, 545, 55]
print(list3[-1]) #打印倒数第1个 55
print(list3[0], list3[3]) #打印第一个和第三个 1 545
print(list3[0:3]) #切片 顾头不顾尾原则 [1, 44, 44]
print(list3[1:3]) #切片 [44, 44]
print(list3[-3:-1]) #还能倒着切 [246, 4566]
print(list3[-3:]) #切片 [246, 4566, 55]
5、元组
俗称不可变列表
创建元组:
ID = (11, 22, 33, 44, 55)
或
ID = tuple((11, 22, 33, 44, 55))
它只有2个方法,一个是count,一个是index,完毕。
6、字典
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
字典的特性:
- dict是无序的
- key必须是唯一的,so 天生去重
person = {"name": "mr.wu", 'age': 18}
或
person = dict({"name": "mr.wu", 'age': 18})
字典的基本操作:
info = {
'stu001': "LeiJun",
"stu002": "MaYun",
'stu003': "Alex"
}
for i in info:
print(i, info[i]) #最推荐使用的,循环打印字典
'''
for k,v in info.items():
print(k,v)
'''
b = {
"stu001": "Alex",
1: 2,
3: 5
}
info.update(b) #将字典b更新到字典info
print(info) #{3: 5, 1: 2, 'stu002': 'MaYun', 'stu001': 'Alex', 'stu003': 'Alex'}
print(info.items())#dict_items([(3, 5), (1, 2), ('stu002', 'MaYun'), ('stu001', 'Alex'), ('stu003', 'Alex')])
c = dict.fromkeys([1, 2, 3], "test") #初始化新字典,1,2,3共享一个内存地址,value都是“test”
print(c) #{1: 'test', 2: 'test', 3: 'test'}
dict1 = {
"stu001": "YL",
1: 2,
3: 5
}
print(dict1.keys()) #打印所有的keys dict_keys([3, 1, 'stu001'])
print(dict1.values()) #打印所有的values dict_values([5, 2, 'YL'])
#首先查找,stu004,若有则返回原来字典里面stu004对应的value,没有则创建一个键值对,并返回值
print(dict1.setdefault("stu004", "YL")) #YL
print(dict1) #{'stu001': 'YL', 'stu004': 'YL', 3: 5, 1: 2}
dict1["stu001"] = "LJ" #有Key,则修改value
dict1["stu005"] = "1234565" #无Key,则创建新的键值对
print(dict1) #{'stu005': '1234565', 1: 2, 'stu004': 'YL', 3: 5, 'stu001': 'LJ'}
#del dict1["stu001"] #删除
dict1.pop("stu005")
print(dict1)
dict1.popitem() #随便删除一个
print(dict1)
#print(dict1["stu002"]) #没有就报错
print(dict1.get("stu006")) #没有就返回None 安全获取的方法
print("stu006" in dict1) #查找是否有stu003,有就返回True
7、集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
集合常用操作:
list_1 = [1, 4, 5, 4, 7, 3, 6, 7, 6]
list_1 = set(list_1) #将列表转换为集合
list_2 = set([1, 5, 7, 6, 9, 11, 33]) #创建一个数值集合, 集合是无序的
list_5 = set("Hello") #创建一个唯一字符的集合
print(list_1.intersection(list_2)) #求交集
print(list_1 & list_2) #交集
print(list_1.union(list_2)) #求并集
print(list_1 | list_2) #并集
print(list_1 - list_2) #差集
print(list_1.difference(list_2)) #求差集 list_1中有,list_2中没有的元素
print(list_2.difference(list_1))
list_3 = set([1, 3, 7])
print(list_3.issubset(list_1)) #判断list_3是不是list_1的子集
print(list_1.issuperset(list_3)) #判断list_1是不是list_3的父集
#并集-差集=对称差集
print(list_1.symmetric_difference(list_2)) #项在两个集合中,但不会同时出现在二者中
print(list_1 ^ list_2) #对称差集 项在两个集合中,但不会同时出现在二者中
list_4 = set([2, 4, 6])
print(list_3.isdisjoint(list_4)) #如果两个集合没有交集返回 True
#print(list_1.add(999)) 错误的写法
list_1.add(999) #添加一个项
list_1.update([123, 345, 455]) #添加多个项
print(list_1)