事实表是维度建模的核心,紧紧围绕着业务过程来设计,通过描述度量来表达业务过程,包含了维度的引用和业务度量值。
上一篇文章我们讲了《维度表的设计》,今天我们聊一下事实表的设计。一样,我们的目录结构和内容参考了《阿里巴巴大数据之路》一书。
事实表的基础
概念
粒度
事实表中的每一条记录所表达的业务细节程度被称为粒度。
粒度由两种方式表述:
- 维度属性组合所表示的细节程度
- 所表示的具体业务含义
事实
用来描述业务过程的度量,一般是整形、浮点型的十进制数值。
- 可加:对任何维度进行汇总
- 半可加:只能对特定维度进行汇总,如库存,按照地点、商品维度汇总是有意义的,按时间汇总是无意义的
- 不可加:比率型,需要拆解为可加的度量来实现汇总,如商品购买率=> 购买人数,浏览人数
相对于维度表,事实表会显得更细长,变化速度也会比维度表快。
事实表中也是可以存储维度属性的,这种操作称为——维度退化,而相应的维度属性称为——退化维度。
事实表类型
- 事务事实表:按最细粒度来保存业务过程的数据,如购买商品事实表
- 周期快照事实表:按照固定的时间间隔(年、月、日),记录事实
- 累计快照事实表:覆盖整个业务生命周期,从开始到结束的累计事实,通常具有多个日期时间字段来记录关键的时间点,当生命周期发生变化,记录也会随之被修改。
设计原则
原则一:尽可能包含所有与业务过程相关的事实
事实表的设计目的是为了度量业务过程。所以分析哪些事实与业务过程有关,是设计中非常重要的关注点。在事实表中应尽量包含所有与该业务过程相关的事实,即使有冗余,但因为事实通常是数字型,带来存储开销不会很大!
原则二:只选择与业务过程相关的事实
在选择事实时,应该注意只选择与业务过程有关的事实。比如在下单的业务过程中,不应该存在支付金额这一个属于支付业务过程的事实。
原则三:不可加的事实拆分为可加的度量
如商品购买率 => 购买人数,浏览人数
原则四:在选择维度和事实之前必须先声明粒度
一般在设计事实表过程中,粒度定义越细越好,从最低级别的原子粒度开始能满足之后无法预期的用户需求。
在事实表中,通常通过业务描述来表述粒度(DWD),但对于聚集型的事实表(DWS),可通过单维度或者维度组合的方式来表述。
原则五:在同一个事实表中不能有多种不同粒度的事实
如下表,包含了小订单粒度、大订单粒度。大订单B1包含了小订单(L1001、L1002、L1003),很明显如果这两层不同粒度同时存在一张事实表,当汇总大订单付款金额时,会造成重复计算的问题。所以,大订单付款金额应该从此表删除。
|
小订单ID
|
大订单ID
|
小订单付款金额
|
小订单购买数量
|
大订单付款金额
|
|
L1001
|
B1
|
100
|
1
|
400
|
|
L1002
|
B1
|
100
|
2
|
400
|
|
L1003
|
B1
|
200
|
1
|
400
|
|
L1004
|
B2
|
123
|
4
|
123
|
|
L1005
|
B3
|
143
|
1
|
143
|
|
L1006
|
B4
|
53
|
3
|
53
|
原则六:事实的单位要保持一致
如金额统一成元或者分。
原则七:对事实的null值要处理
null值在特定的SQL查询引擎中是无法做汇总、比较或者过滤处理的,所以需要统一用零值填充。
原则八:使用退化维度提高事实表的可用性
维度退化到事实表最能提高使用表的效率,应尽量把常用、多用的维度属性退化到事实表中。比如,在事实表中增加商品维度表(商品名称),在查询商品名称汇总信息时就不需要再关联商品维表,减少I/O。
设计方法
- 确定业务需求和事实表的类型
进行详细的需求分析,分析业务整个生命周期,明确关键业务步骤,筛选与需求相关的业务过程。
- 声明粒度
尽量选择原子粒度
- 确定维度
粒度声明后,也意味着确定了主键,对应的维度组合跟相关维度字段也可以确定了
- 确定事实
确定“这个过程的度量有什么”,拆分不可加事实
- 冗余维度
维度尽可能退化到事实表中
事务事实表
设计过程
任何类型的时间都可以理解为一种事务。
针对这些食物构建事实表,用以跟踪自定义业务过程的个体行为,提供丰富的分析能力,作为数据仓库原子的明细数据。
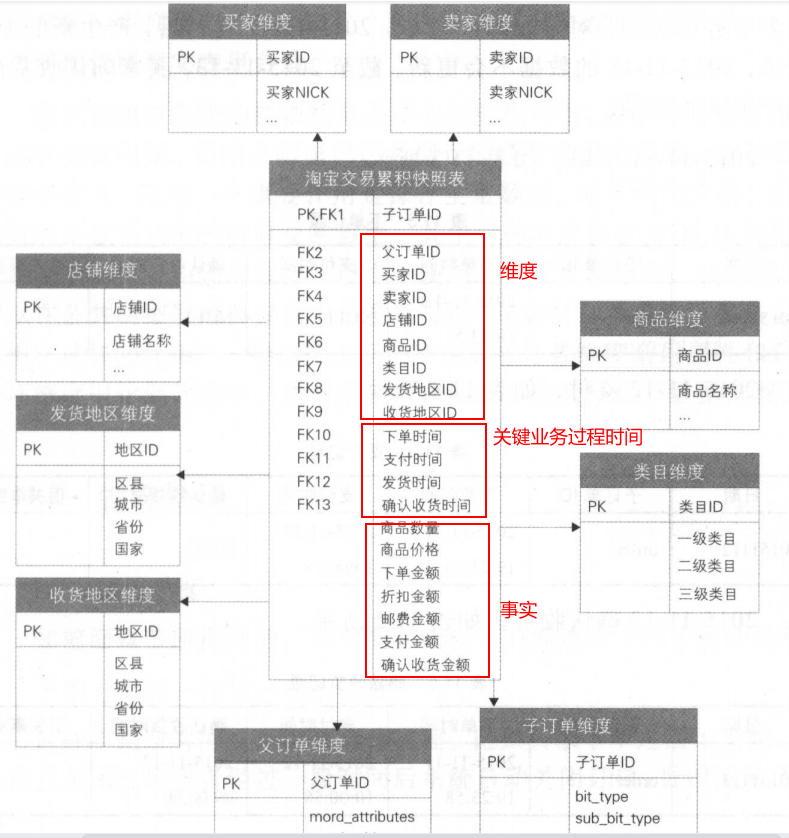
下面以淘宝交易事务事实表为例,阐述事务事实表的设计过程。
选择业务过程
订单的流转过程:创建订单 》 买家付款 》 卖家发货 》 买家确认收货
对应 下单,支付,发货,成功 四个业务过程,这四个业务过程是交易中最重要的时间节点。
确定数据粒度
目前在淘宝下单交易时,有两种方式购买,
一是选定商品直接购买,这样会产生一个订单;
二是选择多种商品加入购物车后,再一起结算,这样每一种商品都会产生一个小订单,同时针对同一个店铺会额外产生一个大订单(由于是同一个店铺购买,所以大订单会承载了物流信息、店铺优惠信息等)。
我们选择子订单为数据粒度。
确定维度
维度包含:买家、卖家、商品、商品类目、发货地区、收货地区、大订单维度以及杂项维度。
所以我们可以简单把事实表理解为一下结构:
事实表 = 主键 + 度量 + 相关维度ID和退化维度
确定事实
以淘宝交易事务事实表为例,选定三个业务过程:下单、支付和成功完结,不同的业务过程有不同的事实。
下单:下单金额、下单数量、下单分摊金额,下单优惠金额支付:支付金额、分摊邮费、折扣金额、红包金额、积分金额成功完结:确认收货金额
由于是小订单维度,所以大订单产生的金额需要分摊回子订单上,如:邮费、店铺折扣等。具体会在父子事实的处理方式中详述。
冗余维度
将买卖家星级、标签、店铺名称、商品类型、商品特征、商品属性、类目层级等维度属性都冗余到事实表中,提高对事实表进行过滤查询、统计聚合的效率。

单事务事实表
上面图11.5中遗留一个问题:对于事实表中能否包含多个业务过程(下单、支付),还没有给出定论。
如果我们将业务过程分开处理那就是单事务事实表,参考以下形式:

我们会发现其实下单和支付业务的维度是一样的,只有度量不一样。
那我们是否能把两个业务过程合并起来?答案是可以的。
多事务事实表
讲不同的事实合并到同一个事实表中(一个事实表包含多个业务过程)。
合并后,针对度量我们有两种处理方式
- 不同的事实按照不同的字段存放
- 新增一个Flag标识业务过程,事实存放到同一个字段
确定业务过程和数据粒度
下单、支付、成功完结都有相同的数据粒度,都是子订单粒度,合适放到同一个事实表中。
确定维度
依然还是买家、卖家、商品、商品类目、发货地区、收货地区等
确定事实
多事务事实表最重要的是,如何处理多个事实。上面也说了两种方法。
采用方法一,用多个度量去保存且一个业务过程杂项维度标记,如:是否当天下单、是否当天支付、是否当天成功完结,标签之间互不相干。

采用方法二,统一一个度量保存,且一个业务过程增加一个标签标记。
如收藏商品事务事实表,增加一个标记【收藏事件类型 1=收藏,2=删除】来区分。不过收藏事务事实表,无事实,一般用于统计收藏或者删除的次数。
什么时候使用多事务事实表
- 当不同业务过程的度量比较相似、差异不大时,可以采用第二种多事务事实表的设计方式,使用同 个字段来表示 数据。但这种方式存在 个问题一一在同一个周期内会存在多条记录。
- 当不同业务过程的度量差异较大时,可以选择第一种事务事实表的设计方式,将不同业务过程的度量使用不同字段冗余到表中,非当前业务过程则置零表示。这种方式所存在的问题是度量字段零值较多。
两种事实表对比

事实的设计准则
- 事实完整性:事实表包含与其描述的过程有关的所有事实。如淘宝交易事务事实表中的支付业务,包含支付金额、支付邮费、支付红包、支付积分、支付折扣
- 事实一致性:统一、预先、尽可能地算好一些公式类的指标
- 事实可加性
周期快照事实表
特性
用快照采样状态
以预订的时间间隔采样状态度量(如:自然年初截止当日的下单金额),联合一个或者多个维度定义事实表的粒度。
快照粒度
周期+某个维度(如:商家的每月汇总事实、商家累计交易事实)
密度与稀疏性
周期快照事实表与事务型事实表关键区别在于:密度。事务事实表是稀疏的(有发生才会记录),而周期快照事实表是稠密的(无论发生与否都记录)。
半可加性
周期快照事实表中收集到的状态度量都是半可加的。(如:商家累计的下单金额)
产出方式
- 从事务型事实表汇总产出
- 从ODS(或操作性系统数据)产出
实例
设计周期快照事实表有两个步骤
- 确定快照粒度
- 确定采样的状态度量
单维度的日快照事实表
1. 确定粒度
采样周期为每日,针对卖家、买家、商品、类目、地区等维度构建周期快照事实表。如卖家历史至今汇总事实表,商品自然月至今汇总事实表。
2. 确定状态度量
【卖家历史至今汇总事实表】(业务日期,卖家ID,历史截止至当日的下单金额,历史截止至当日的下单买家数)

同样,商品日快照事实表

多维度的日快照事实表
多维度快照事实表其实是在单维度快照事实表中增加维度,如买卖家历史至今快照事实表。
注意事项
1. 事务与周期快照一般是成对出现的。
2. 附加事实:
- 有可能会在周期事实表中增加上一个周期的状态度量
- 一般会有:历史至当日、自然年至当日、季度至当日、财年至当日等配套出现
累积事实表
累积事实表,一般用于满足求事件之间的时长这种需求的。
设计过程
建模过程与事务事实表相同,适用于维度建模的步骤。
特点
- 数据会不断更新
- 有多个关键业务过程的日期(代表了生命周期)
特殊处理
如果出现关键业务过程非线性的情况(如下单后就关闭订单,而非走正常的下单-支付-发货-确认发货),那就从业务需求角度,确定好关键过程后再做累积事实表的设计。
物理实现
- 走全量表,一天一个全量分区,但是数据量大的情况会保存很多永远不会再更新的历史数据,不理想
- 走全量表的变化形式,归定每天保存前N天内的数据,超过的那部分归档处理,也不怎么理想
- 规定生命周期代表结束的业务过程,如订单结束/订单关闭,每天的分区存放当天结束的数据,然后设计一个无限大的分区(如:9999-12-31),来保存截止当天尚未走向生命周期结束的数据。理想,但是这种实现方式难点是如何确定订单结束。
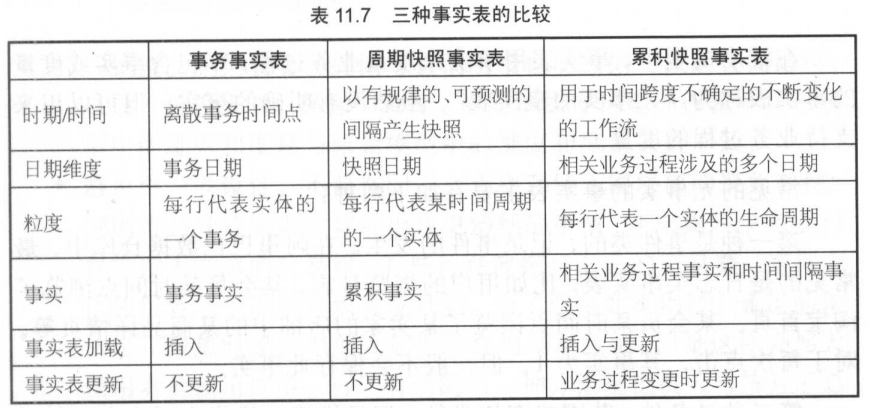
三种事实表比较
无事实的事实表
一般有两种
- 事件类:如收藏购物车、浏览页面、点击等,其事实为1,但一般不保存
- 条件、范围、资格类:记录维度之间多对多的关系,如:客户和销售人员的分配情况,产品的促销范围等
聚集型事实表
聚集型(汇总型)事实表的出现,其实就是为了解决数据仓库性能问题。其实绝大部分数据都可以直接通过加工明细数据得出,但是我们会发现,每个企业都会有自己固定的、必须会看的数据,这部分数据如果经常看,数仓开发要经常查,数据分析也经常做重复的事情,那就有必要把这些数据根据固定维度固化到聚集型事实表中。一般来说,聚集只针对明细层而言,所以聚集不跨域、不跨越事实(意思是得按照明细层的原子指标,按照业务需求加工出多个衍生指标)。
聚集的原则
- 一致性:必须保证聚集后的数据与明细数据有一致的查询结果
- 避免单一表设计:一个表内的行不能存不同粒度的聚集数据。如有些行存放天汇总数据、有些行存放月汇总数据。应把天、月汇总数据分两列存放,列明必须标注好注释。
- 聚集粒度可以不同:聚集不需保持与明细粒度数据一样的粒度
聚集的步骤
- 确定维度
- 确定一致性上钻
- 确定事实
聚集的补充说明
- 聚集不跨越事实:事实都是从明细层过来的(注意别走偏了,聚集不跨越事实,但可包含同一个事实的不同度量)
- 聚集的问题:聚集是把常用的,固定粒度的数据沉淀下来。万一数据粒度改变,表需要重新做