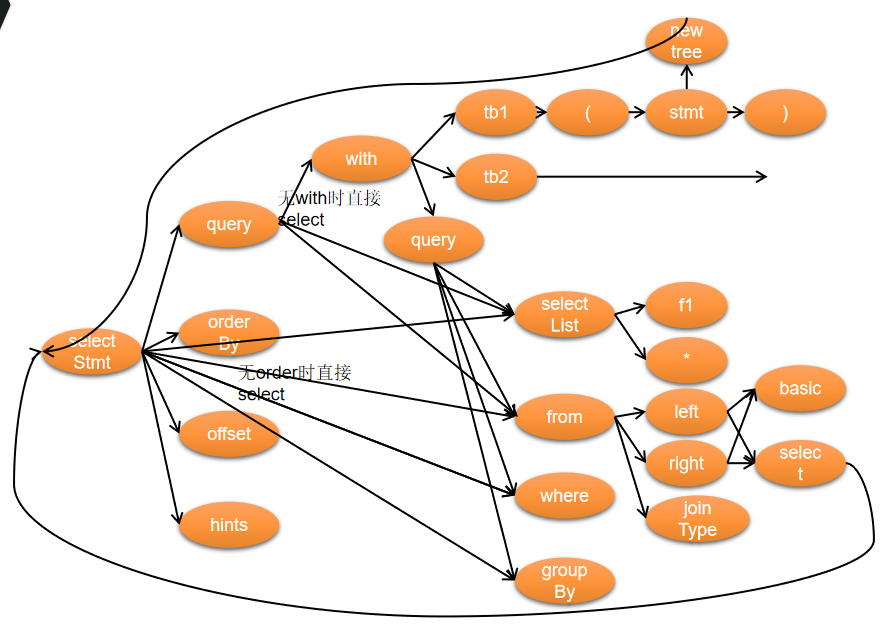
语法解析有个核心目标,那就是需要构建抽象语法树。虽然说语法解析框架可以很容易的识别出各节点的结构,但还需要我们按照自行需求,转换成期望的树结构,才能够方便使用。
基本上,所有的表达式,都会进行嵌套组合,从而才能够发挥其强大的作用。但,往往我们在做解析的时候,又是线性的解析。所以,最初,我们能得到的必然是一个个token列表。所以,如何将一个个平铺的列表,转换成树状结构,将会是一个比较重要的话题。我们今天就来看看calcite中的其中一非常小的点,它是如何将一个list转换为tree的吧。
1. 工具类入口
calcite 树的转化过程: list -> tree,是一个相对独立的过程,所以被写到工具类中去了。其最终结果是用 SqlNode 承载的。
// org.apache.calcite.sql.parser.SqlParserUtil#toTree /** * Converts a list of {expression, operator, expression, ...} into a tree, * taking operator precedence and associativity into account. */ public static @Nullable SqlNode toTree(List<@Nullable Object> list) { if (list.size() == 1 && list.get(0) instanceof SqlNode) { // Short-cut for the simple common case return (SqlNode) list.get(0); } LOGGER.trace("Attempting to reduce {}", list); final OldTokenSequenceImpl tokenSequence = new OldTokenSequenceImpl(list); final SqlNode node = toTreeEx(tokenSequence, 0, 0, SqlKind.OTHER); LOGGER.debug("Reduced {}", node); return node; } // org.apache.calcite.sql.parser.SqlParserUtil#toTreeEx /** * Converts a list of {expression, operator, expression, ...} into a tree, * taking operator precedence and associativity into account. * * @param list List of operands and operators. This list is modified as * expressions are reduced. * @param start Position of first operand in the list. Anything to the * left of this (besides the immediately preceding operand) * is ignored. Generally use value 1. * @param minPrec Minimum precedence to consider. If the method encounters * an operator of lower precedence, it doesn't reduce any * further. * @param stopperKind If not {@link SqlKind#OTHER}, stop reading the list if * we encounter a token of this kind. * @return the root node of the tree which the list condenses into */ public static SqlNode toTreeEx(SqlSpecialOperator.TokenSequence list, int start, final int minPrec, final SqlKind stopperKind) { PrecedenceClimbingParser parser = list.parser(start, token -> { if (token instanceof PrecedenceClimbingParser.Op) { PrecedenceClimbingParser.Op tokenOp = (PrecedenceClimbingParser.Op) token; final SqlOperator op = ((ToTreeListItem) tokenOp.o()).op; return stopperKind != SqlKind.OTHER && op.kind == stopperKind || minPrec > 0 && op.getLeftPrec() < minPrec; } else { return false; } }); final int beforeSize = parser.all().size(); // 将list形式的token转换成树形式的token parser.partialParse(); final int afterSize = parser.all().size(); // 将树形token转换成SqlNode表示 final SqlNode node = convert(parser.all().get(0)); // 将转换掉的token占位全部清空,将在第一个位置处替换为 SqlNode list.replaceSublist(start, start + beforeSize - afterSize + 1, node); return node; } // org.apache.calcite.sql.parser.SqlParserUtil#convert private static SqlNode convert(PrecedenceClimbingParser.Token token) { switch (token.type) { case ATOM: return requireNonNull((SqlNode) token.o); case CALL: final PrecedenceClimbingParser.Call call = (PrecedenceClimbingParser.Call) token; final List<@Nullable SqlNode> list = new ArrayList<>(); for (PrecedenceClimbingParser.Token arg : call.args) { list.add(convert(arg)); } final ToTreeListItem item = (ToTreeListItem) call.op.o(); if (list.size() == 1) { SqlNode firstItem = list.get(0); if (item.op == SqlStdOperatorTable.UNARY_MINUS && firstItem instanceof SqlNumericLiteral) { return SqlLiteral.createNegative((SqlNumericLiteral) firstItem, item.pos.plusAll(list)); } if (item.op == SqlStdOperatorTable.UNARY_PLUS && firstItem instanceof SqlNumericLiteral) { return firstItem; } } return item.op.createCall(item.pos.plusAll(list), list); default: throw new AssertionError(token); } }
以上就是其转换list到tree的框架代码了,关键词是:优先级,转换,。。。
2. 具体的list->tree过程
树的转换过程,主要是将list进行合并组合的过程。大体是按照每个符号的优先级,将其前后元素作为其操作数,合并。比如:a > 1 or b < 2, 会被构建 >a1 or b < 2, >a1 or <b2, (or)(>a1)(<b2) 。 而要选出优先级最高的元素,优先从其开始做树合并,才是正确的选择。确定最高优先级元素过程示意图如下:
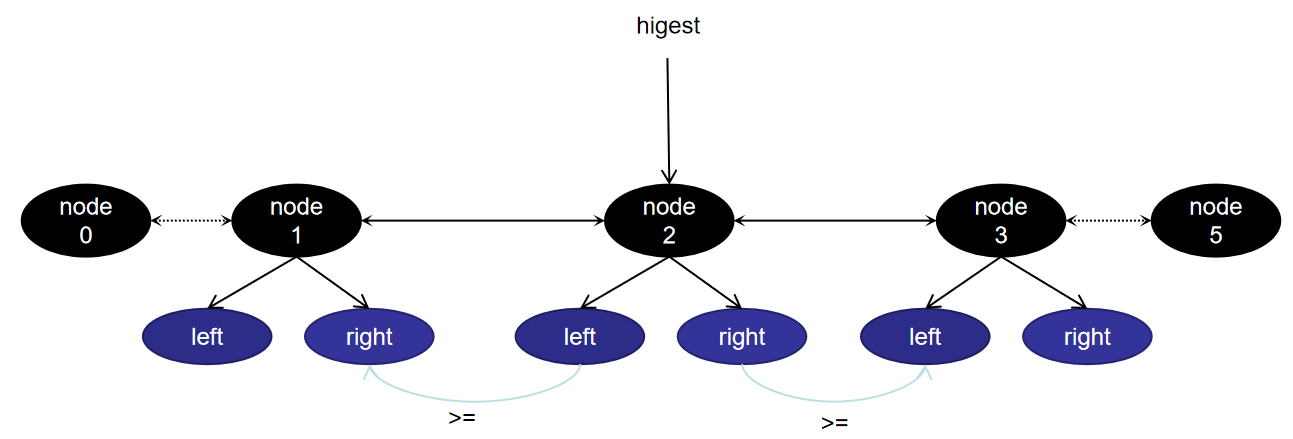
具体解析过程如下:
// org.apache.calcite.sql.parser.SqlParserUtil.OldTokenSequenceImpl#parser @Override public PrecedenceClimbingParser parser(int start, Predicate<PrecedenceClimbingParser.Token> predicate) { final PrecedenceClimbingParser.Builder builder = new PrecedenceClimbingParser.Builder(); for (Object o : Util.skip(list, start)) { if (o instanceof ToTreeListItem) { final ToTreeListItem item = (ToTreeListItem) o; final SqlOperator op = item.getOperator(); if (op instanceof SqlPrefixOperator) { builder.prefix(item, op.getLeftPrec()); } else if (op instanceof SqlPostfixOperator) { builder.postfix(item, op.getRightPrec()); } else if (op instanceof SqlBinaryOperator) { builder.infix(item, op.getLeftPrec(), op.getLeftPrec() < op.getRightPrec()); } else if (op instanceof SqlSpecialOperator) { builder.special(item, op.getLeftPrec(), op.getRightPrec(), (parser, op2) -> { final List<PrecedenceClimbingParser.Token> tokens = parser.all(); final SqlSpecialOperator op1 = (SqlSpecialOperator) requireNonNull((ToTreeListItem) op2.o, "op2.o").op; SqlSpecialOperator.ReduceResult r = op1.reduceExpr(tokens.indexOf(op2), new TokenSequenceImpl(parser)); return new PrecedenceClimbingParser.Result( tokens.get(r.startOrdinal), tokens.get(r.endOrdinal - 1), parser.atom(r.node)); }); } else { throw new AssertionError(); } } else { builder.atom(requireNonNull(o, "o")); } } return builder.build(); } // org.apache.calcite.util.PrecedenceClimbingParser#partialParse public void partialParse() { for (;;) { // 每次循环,找到一个符号,将树收缩,若没有找到,则说明树已全部构建完成 // 按照优先级,会先将 > < = 这些符号替换完,然后再替换 and or 等等 // 比如: a > 1 or b < 2, 会被构建 >a1 or b < 2, >a1 or <b2, (or)(>a1)(<b2) // 所以,优先级的定义非常重要,它是在符号定义的时候就确定下来的 Op op = highest(); if (op == null) { return; } final Token t; switch (op.type) { case POSTFIX: { Token previous = requireNonNull(op.previous, () -> "previous of " + op); t = call(op, ImmutableList.of(previous)); replace(t, previous.previous, op.next); break; } case PREFIX: { Token next = requireNonNull(op.next, () -> "next of " + op); t = call(op, ImmutableList.of(next)); replace(t, op.previous, next.next); break; } case INFIX: { Token previous = requireNonNull(op.previous, () -> "previous of " + op); // 构造token关系,如 = a b Token next = requireNonNull(op.next, () -> "next of " + op); // 替换首尾节点关系 // 此处的call, 会将left,right 置为-1, 以便在后续的遍历中, 不再找出当前节点 // replace 将call的next, previous 设置为下一跳节点, 将call设置到整个树的尾部, 即整个树形结构收缩 t = call(op, ImmutableList.of(previous, next)); replace(t, previous.previous, next.next); // switch 的break, 转到下一次for循环 break; } case SPECIAL: { Result r = ((SpecialOp) op).special.apply(this, (SpecialOp) op); requireNonNull(r, "r"); replace(r.replacement, r.first.previous, r.last.next); break; } default: throw new AssertionError(); } // debug: System.out.println(this); } } // org.apache.calcite.util.PrecedenceClimbingParser#replace private void replace(Token t, @Nullable Token previous, @Nullable Token next) { t.previous = previous; t.next = next; // 如果上一节点不为空,则将上一节点的下 if (previous == null) { first = t; } else { previous.next = t; } if (next == null) { last = t; } else { next.previous = t; } } // org.apache.calcite.sql.parser.SqlParserUtil#replaceSublist /** * Replaces a range of elements in a list with a single element. For * example, if list contains <code>{A, B, C, D, E}</code> then <code> * replaceSublist(list, X, 1, 4)</code> returns <code>{A, X, E}</code>. */ public static <T> void replaceSublist( List<T> list, int start, int end, T o) { requireNonNull(list, "list"); Preconditions.checkArgument(start < end); // 从后往前remove, 保证remove的准确性 for (int i = end - 1; i > start; --i) { list.remove(i); } list.set(start, o); }
3. 各符号定义
符号定义时,就将优先级定义好了。以便在后续构建时使用。其基本都被定义在 SqlStdOperator 中。 以加减乘除为例,加减会是同一个优先级,乘除是另一个高优先级的操作。
// org.apache.calcite.sql.fun.SqlStdOperatorTable#AND public static final SqlBinaryOperator AND = new SqlBinaryOperator( "AND", SqlKind.AND, 24, // AND 优先级24 true, ReturnTypes.BOOLEAN_NULLABLE_OPTIMIZED, InferTypes.BOOLEAN, OperandTypes.BOOLEAN_BOOLEAN); /** * Arithmetic division operator, '<code>/</code>'. */ public static final SqlBinaryOperator DIVIDE = new SqlBinaryOperator( "/", SqlKind.DIVIDE, 60, // 除号的优先级比较高 true, ReturnTypes.QUOTIENT_NULLABLE, InferTypes.FIRST_KNOWN, OperandTypes.DIVISION_OPERATOR); /** * Arithmetic multiplication operator, '<code>*</code>'. */ public static final SqlBinaryOperator MULTIPLY = new SqlMonotonicBinaryOperator( "*", SqlKind.TIMES, 60, true, ReturnTypes.PRODUCT_NULLABLE, InferTypes.FIRST_KNOWN, OperandTypes.MULTIPLY_OPERATOR); /** * Infix arithmetic minus operator, '<code>-</code>'. * * <p>Its precedence is less than the prefix {@link #UNARY_PLUS +} * and {@link #UNARY_MINUS -} operators. */ public static final SqlBinaryOperator MINUS = new SqlMonotonicBinaryOperator( "-", SqlKind.MINUS, 40, true, // Same type inference strategy as sum ReturnTypes.NULLABLE_SUM, InferTypes.FIRST_KNOWN, OperandTypes.MINUS_OPERATOR); /** * Logical equals operator, '<code>=</code>'. */ public static final SqlBinaryOperator EQUALS = new SqlBinaryOperator( "=", SqlKind.EQUALS, 30, // =号的优先级比较小 true, ReturnTypes.BOOLEAN_NULLABLE, InferTypes.FIRST_KNOWN, OperandTypes.COMPARABLE_UNORDERED_COMPARABLE_UNORDERED); /** * Logical less-than-or-equal operator, '<code><=</code>'. */ public static final SqlBinaryOperator LESS_THAN_OR_EQUAL = new SqlBinaryOperator( "<=", SqlKind.LESS_THAN_OR_EQUAL, 30, true, ReturnTypes.BOOLEAN_NULLABLE, InferTypes.FIRST_KNOWN, OperandTypes.COMPARABLE_ORDERED_COMPARABLE_ORDERED);
最终的树形结果示例如下:
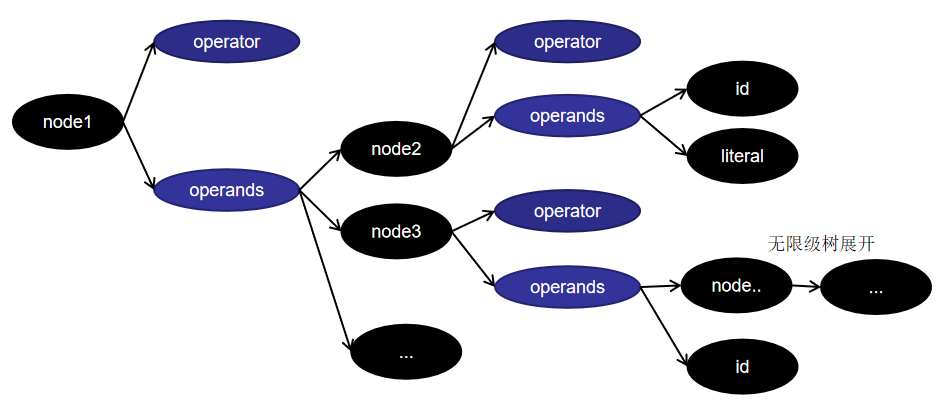
即由操作数和操作符组成的树结构,即可认为它是一种基于栈的编译结构,对于我们表达语义,比较清晰。
实际上,树结构只是一种表现形式,它需要在不同的场合应用不同的结构,灵活变换,方能如鱼得水。比如整个sql语句,在calcite的树结构中,又不是这样的了。