环境:ubuntu 16.0
需要软件:jdk ssh
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
2.8.3
安装 jdk并配置环境变量
安装ssh和rshync,主要设置免密登录
sudo apt-get install ssh
sudo apt-get install rshync
sh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh
安装hadoop
root@hett-virtual-machine:/usr/local/hadoop# tar -xzvf /home/hett/Downloads/hadoop-2.8.3.tar.gz
root@hett-virtual-machine:/usr/local/hadoop# mv hadoop-2.8.3 hadoop
root@hett-virtual-machine:/usr/local# cd hadoop/
root@hett-virtual-machine:/usr/local/hadoop# mkdir tmp
root@hett-virtual-machine:/usr/local/hadoop# mkdir hdfs
root@hett-virtual-machine:/usr/local/hadoop# mkdir hdfs/data
root@hett-virtual-machine:/usr/local/hadoop# mkdir hdfs/name
root@hett-virtual-machine:/usr/local/hadoop# nano /etc/profile
配置
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/local/jdk1.8.0_151
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH:$HADOOP_HOME/bin
root@hett-virtual-machine:/usr/local/hadoop# source /etc/profile
root@hett-virtual-machine:/usr/local/hadoop# cd etc/hadoop/
root@hett-virtual-machine:/usr/local/hadoop/etc/hadoop# ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml.template
core-site.xml httpfs-site.xml slaves
hadoop-env.cmd kms-acls.xml ssl-client.xml.example
hadoop-env.sh kms-env.sh ssl-server.xml.example
hadoop-metrics2.properties kms-log4j.properties yarn-env.cmd
hadoop-metrics.properties kms-site.xml yarn-env.sh
hadoop-policy.xml log4j.properties yarn-site.xml
hdfs-site.xml mapred-env.cmd
root@hett-virtual-machine:/usr/local/hadoop/etc/hadoop#
root@hett-virtual-machine:/usr/local/hadoop/etc/hadoop# nano hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_151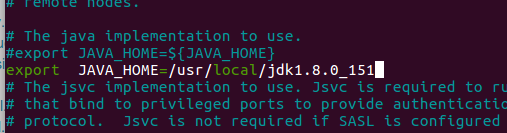
配置yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_151
3)配置core-site.xml
添加如下配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>4),配置hdfs-site.xml
添加如下配置
<configuration>
<!—hdfs-site.xml-->
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>5),配置mapred-site.xml
添加如下配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>6),配置yarn-site.xml
添加如下配置:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.241.128:8099</value>
</property>
</configuration>4,Hadoop启动
1)格式化namenode
$ bin/hdfs namenode –format
2)启动NameNode 和 DataNode 守护进程
$ sbin/start-dfs.sh3)启动ResourceManager 和 NodeManager 守护进程
$ sbin/start-yarn.sh

- $ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
- $ ssh-keygen -t rsa # 会有提示,都按回车就可以
- $ cat id_rsa.pub >> authorized_keys # 加入授权

root@hett-virtual-machine:~# cd /usr/local/hadoop/
root@hett-virtual-machine:/usr/local/hadoop# sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-hett-virtual-machine.out
localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-hett-virtual-machine.out
........
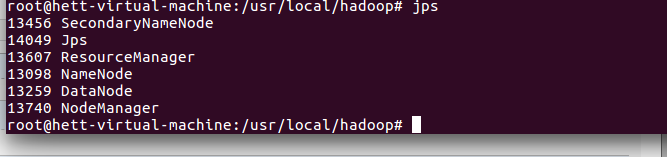
5,启动验证
1)执行jps命令,有如下进程,说明Hadoop正常启动
# jps
6097 NodeManager
11044 Jps
7497 -- process information unavailable
8256 Worker
5999 ResourceManager
5122 SecondaryNameNode
8106 Master
4836 NameNode
4957 DataNode