通过学习整理其他优秀资源,本文解决三个问题:
- redis如何持久化?
- 生产环境中,redis的可用性如何保证?
- redis中遇到存到存储上限如何解决?
一、redis持久化
redis是基于内存的, 内存特点是断电易失。就必然涉及到持久化操作。redis持久化有两种方式:快照(rdb)和日志(aof)。
1.快照和日志
快照类似于序列化和反序列化过程。把数据序列化成二进制放到磁盘,加载时把磁盘当中的数据直接反序列化,读过来,不需要执行什么。
日志:redis每用一个操作(写、修改),就把操作写到日志文件里去。日志里存放的是操作指令(快照存的是数据自身)。日志是恢复的时候,读到日志的东西还要去执行,变成数据。因此,日志比快照恢复的慢。但快照比日志丢东西丢得多(两次快照之间挂机了,那么中间的东西会丢失。)
日志有三个级别:
- 每操作(就是每次操作就保存数据fsync做数据同步)。好处:数据完整性比较强。缺点是使redis性能下降。
- 每秒钟
(定时器每到1秒,就刷写)最多也就丢1秒钟的数据。操作系统os的缓冲(缓冲满了,os自己会刷写),所以保证至多丢一个buffer(如果1秒之内buffer满了,os自己刷写;如果1s内buffer没满,定时器设置1s,也会刷写。因此最多丢一个buffer的内容)
- os缓冲刷写,丢一个buffer的内容
一般是写满buffer才写入磁盘:程序要调系统调用,即调用内核,操作系统里有buffer缓冲区,程序要向磁盘中写数据,要先把数据交给内核的缓冲区,缓冲区满了之后, 内核才会把数据刷新到磁盘。程序可以flush缓冲区,让内核现在就把数据从缓冲区存到磁盘。(这就是为什么在关闭之前要flush,不然可能丢东西。)
调用fsync()函数可让操作系统现在把缓冲区的数据写到磁盘上,而不是等待缓冲区装满数据。
redis的日志默认级别是每秒钟。追求完整性和一致性的时候,就要把级别调高至每操作。
快照rdb的优势是恢复的快但丢失的多,日志aof的优势是恢复的数据更完整但恢复速度慢。
2.使用方法
早期是默认开启快照rdb。因为不会频繁的对磁盘有io操作。那时用于缓存,而不是数据库,丢失一些数据也无所谓。也可以手动开启日志aof,但开启了快照rdb也就不起作用了。
后来(redis4.0)可以混合使用(各有优缺点),日志aof中包含一个历史状态的快照rdb。比如说8点的快照,然后后面追加的日志。这个混合的还叫做aof日志。(全是日志比较慢,混合的是周期(比如每个小时)的把前面的rof变成rdb(二进制),然后再把后面的日志追加进去)。整体性能高于上面两者。
在redis配置文件中, APPEND ONLY MODE下 的appendonly默认是no,即关闭的。可以打开yes,那么就开启了aof。目的文件是appendfilename "appendonly.aof"。三个级别:# appendfsync always(每笔操作都向磁盘刷写)、appendfsync everysec(每秒钟刷写)和# appendfsync no(程序不触发,让操作系统自己触发刷写)。
新版本在配置文件的APPEND ONLY MODE最后有个aof-use-rdb-preamble yes表示混合模式。在SNAPSHOTTING下,有个dir ./表示存放的路径是当前文件夹。
假如只是aof(没有rdb)的模式(开启了aof:appendonly yes,默认是rdb,关闭混合的aof-use-rdb-preamble no),当在redis里操作时,在./文件夹下的appendonly.aof里就有指令:*2代表后面有两个东西。S6代表后面的单词有6个字符。redis重启时要读取这个文件,然后要把里面set这个过程执行一遍,内存里面才会有数据。
有个问题,如果删除k1,再setk1,一直这么操作,.aof文件会变大,但内存数据反而很少,所以有个压缩机制,将创建和删除抵消掉。比如都对k1进行set操作(set k1 aaa; set k1 222.....)日志只会记录最后一条。BGREWRITEAOF通过后台的方式重写aof(重写会创建一个当前 AOF 文件的体积优化版本)。
当开启了混合的(aof使用rdb),aof-use-rdb-preamble yes,此时设置值,再BGREWRITEAOF就.aof文件就由指令变成rdb二进制文件(序列化内容:rdb原生的文件做个序列化放到里面了)。这个时候再设置值,没有BGREWRITEAOF再打开.aof,就在序列化的内容后面追加刚才设置值的指令。redis重启时,.aof二进制内容直接读,后面的指令就执行。---》比单单执行所有指令快很多。
总之,就是利用镜像的速度,利用日志的全量(完整性)。
二、redis可用性
redis用在生产系统中,有两种问题:可用性(单点故障,会挂);压力(存储上限:存不进去或者高并发访问不过来)。也适用其他服务。
解决可用性问题,最先想到的是集群。但更细来说,应该是主从/主备集群。压力过大可以使用分片集群或者代理集群。都是集群,因此单单说集群就不恰当。
单点挂了,那么就多准备几个备份的(多机),首先就涉及到这几个redis的数据同步问题,注意这是主从/主备,才会有数据同步,而分片集群是不会有数据同步这概念(分片是每个redis存不同的数据)
数据同步
数据同步方式:(1)强一致性:客户端给主写了,主先不给客户端回送消息,而是让备也去写数据,备写成功就通知主,然后主再通知客户端。(强一致性就是主备内容绝对一致)。问题:主这边没问题,而主和备之间有问题(延时、备挂了),那么会阻塞客户端,就是强制一致性破坏可用性(从外界来看应用不可用了)问题。
(2)弱一致性:客户端给主写了,主立即告诉客户端成功,然后异步的通知给备(中间有些地方可能有问题)。主挂掉后,备接管可能之前的数据有些丢失,因此叫弱一致性。
(3)最终一致性:假设有个黑盒,具备自身是可靠的,是集群的(不会挂),主先把数据写到可靠的黑盒中,这个过程是同步和强一致的,然后不可靠的其他redis在可用的时候就从黑盒中读回内容,那么备就会最终具备主挂机之前的状态。redis没有使用最终一致性。
redis主从复制默认工作在弱一致性级别。(强一致性也可开启,但响应速度退化到关系型数据库)。redis做缓存场景比较多,弱一致性是接受的(丢失点数据)
redis基于单点故障需要主从复制(集群方式),特点是节点间数据是全量的(每个redis里的内容是一样的,全部都有)。
三、负载问题
1.akf划分
redis实例中数据太多(压力过大)怎末办?(1)根据业务划分数据到不同的redis实例,不同维度存储。(比如,一个维度是用户信息的redis的主从,再一个维度是购物车的,再一个是商品详情的.....)。(2)分片:将一个redis实例的全量数据分散到不同实例,具体分法可以是hash取模(单号hash模上实例的个数),也可以按照区间划分(0-100,101-200...)
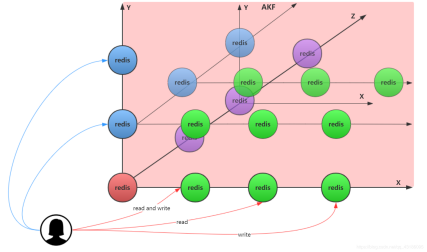
x轴解决问题:冗余数据,提高可靠性。y轴解决问题:业务划分,分治(不同业务治理自己的数据)。z轴对同类数据做负载均衡或者是分片sharding。(相同业务分片)。
这个划分划小的过程就是akf。akf是微服务划分的拆分原则。
2.分片
每个redis存放1/n的数据,但单个redis也可能挂,因此针对单个redis做主从复制。因此分片和主从要混合使用。
实现方式:
在客户端实现。任何大的数据流经客户端后,就通过算法(映射算法)最终流向不同的redis实例中。弊端:多个客户端同时消耗这批数据,就谁涉及到算法同步问题,因此在部署和更新版本上有一定难度;客户端是个service,会消耗指令集占用cpu内存等-----》拆出去好点。
代理集群。多个客户端里都有个轻量级线程,把数据扔给代理,代理里面有算法,代理给不同的redis写不同的数据。如果代理压力大,也可以做个负载均衡。
两个问题:数据分片存储,如果现在是分片2个节点,但未来又要扩展到更多节点,这个扩展好做吗?客户端并发时,代理层处理负载均衡,那么redis能不能不需要代理层,自发满足负载均衡?
解决分片的问题:
redis提出一个槽位(虚拟)的概念。第一步:假设槽位数是1000,算法对数据的key进行hash计算,然后模的是槽位1000,而不是物理节点数,得到key的模数值(0-999)。第二步:用物理节点绑定(映射)不同的模数值。比如0-500的模数值放到node1,500-999映射到node2。好处:未来增加物理节点,将前面node里的槽位属于新增节点的迁移到新增节点。
应用场景:HBASE和Elastic Search。HBASE里有个预分区(HBASE是分布式的,数据分布在不同节点),刚开始建表时分100个小表,未来数据放在小表里。Elastic Search有个分片的概念,分片分多点,以后数据量增大,直接增加物理台数,就可以动态扩展集群的分布式能力。(动态扩缩容)
解决负载的问题:
无主模型/无主集群。(ES在使用环节也是无主的:应用业务接入的寻址操作是无主的,即客户端可以发送请求给任何一节点,该节点就会变成代理节点,帮助把客户端的请求分散到所有节点或者找到正确的节点)。redis也是。算法在每一台redis实例里,实例里除了有算法,还有一个映射(节点和槽位的对应)。客户端现在随便连个节点,该节点的算法算出区间,然后对应映射,找到正确的节点,再告诉客户端,客户端就重新连到正确的节点(这样客户端的增删改查就在正确的节点上。)。