一.算法简介
线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为一元线性回归,大于一个自变量情况的叫做多元线性回归。对于一元线性回归,其线性方程为:h(x) = a1x1 + b。对于多元线性方程,在上述方程中增加一个自变量,得到其线性方程为:h(x) = a1x1 + a2x2 + b。因此,不论是一元线性方程还是多元线性方程,可统一写成如下格式:h(x) = aTx。若上式中x0=1,而求线性方程则演变为求方程的参数aT。对于参数a的求解,需要检测评估a是否为最优,所以说需要对h函数进行评估。一般这个函数被称为损失函数(loss function),用来描述h函数好坏的程度。
损失函数为:

损失函数是x(i)的估计值与真实值之差的平方和,其中1/2系数是为了在求导的时候使得系数为1。如何调整a以使得取得最小值有很多方法,其中有最小二乘法(min square)和梯度下降法等。
二.最小二乘法
将训练特征表示为X矩阵,结果表示为y向量,仍然是线性回归方程,误差函数不变。那么a可以直接由如下公式得出:a = (XTX)-1XT-y,但此方法要求X是列满秩的,而且求矩阵的逆比较慢。
备注:
1.线性独立【线性无关】:指一组向量中任意一个向量都不能有其它一个或几个向量线性表示。
2.上述公式中红色部分表示列秩。
3.一个矩阵的列秩是矩阵的线性无关的列向量的极大数目,行秩与其类似。矩阵的列秩和行秩总是相等的,可以称为矩阵的秩。
三.梯度下降算法
1.批量梯度下降
初始时aT可设置为0,然后迭代使用公式计算aT中的每个参数,直至收敛为止。由于每次迭代计算aT时,都使用了整个样本集,因此我们称该梯度下降算法为批量梯度下降算法【batch gradient descent】。
2.随机梯度下降
当样本集数据量很大时,批量梯度下降算法没迭代一次的复杂度为O(mn),复杂度很高。因此,为了减小复杂度,当m很大时,一般会使用随机梯度下降算法【stochastic gradient descent】,算法如下:

即每读取一条样本,就迭代对aT进行更新。然后判断是否收敛,若没有收敛则继续读取样本进行计算,若样本读取完还未收敛,则重新开始读取样本。这样迭代一次的复杂度为O(n)。对于大数据集,很可能只需要读取一小部分数据函数就收敛了。所以当数据量很大时,更倾向于选择随机梯度下降算法。
不过,相比较批量梯度下降算法,随机梯度下降算法使得函数趋近于最小值的速度更快,但是有可能会在最小值周围震荡,造成永远无法收敛。但是在实践中,大部分值都能够接近最小值,效果也都还不错。为了减小震荡,可以设置当变化小于某个阈值时认定为收敛。
四.源码分析
MLlib的线性回归模型采用随机梯度下降算法来优化目标函数。MLlib实现了分布式的随机梯度下降算法。其分布方法为:在每次迭代中,随机抽取一定比例的样本作为当前迭代的计算样本;对计算样本中的每一个样本分布计算梯度【分布式计算】;然后再通过聚合函数对样本的梯度进行累计,得到该样本的平均梯度损失;最后根据最新的梯度及上次迭代的权重进行权重的更新。线性回归模型没有使用正则化方法。

MLlib线性回归源码执行流程及相关概念:

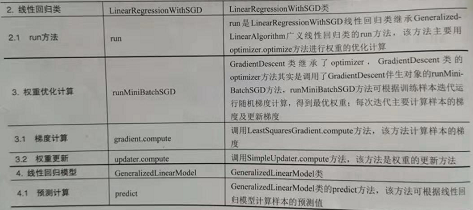
线性回归伴生对象四LinearRegressionWithSGD,该对象是建立线性回归模型的入口,该对象主要定义训练线性回归模型的train方法。train方法可通过设置训练参数进行模型训练,其参数主要包括:
1.input:训练样本,格式为RDD[LabeledPoint],其中LabelPoint的格式为(label,features)
2.numIterations:迭代次数,默认为100
3.stepSize:每次迭代步长,默认为1
4.miniBatchFraction:每次迭代参与计算的样本比例,默认为1,表示全部样本参与计算
5.initialWeights:初始化权重
线性回归类是LinearRegressionWithSGD,该类是基于随机梯度下降法的线性回归模型,该类继承了GeneralizedLinearAlgorithm广义回归类。该类主要初始化梯度下降的方法、梯度更新方法、优化方式等,其中线性回归的梯度计算的损失函数不采用正则化;然后根据初始化的方法调用继承GeneralizedLinearAlgorithm的run方法开始训练模型。
五.代码实现
1 import org.apache.spark.sql.SparkSession 2 import org.apache.spark.sql.DataFrame 3 import org.apache.spark.ml.feature.VectorAssembler 4 import org.apache.spark.ml.regression.LinearRegression 5 /** 6 * Created by zhen on 2018/3/10. 7 */ 8 object LinearRegression { 9 def main(args: Array[String]) { 10 //设置环境 11 val spark = SparkSession.builder ().appName ("LinearRegressionTest").master ("local[2]").getOrCreate() 12 val sc = spark.sparkContext 13 val sqlContext = spark.sqlContext 14 //准备训练集合 15 val raw_data = sc.textFile("src/sparkMLlib/man.txt") 16 val map_data = raw_data.map{x=> 17 val mid = x.replaceAll(","," ,") 18 val split_list = mid.substring(0,mid.length-1).split(",") 19 for(x <- 0 until split_list.length){ 20 if(split_list(x).trim.equals("")) split_list(x) = "0.0" else split_list(x) = split_list(x).trim 21 } 22 ( split_list(1).toDouble,split_list(2).toDouble,split_list(3).toDouble,split_list(4).toDouble, 23 split_list(5).toDouble,split_list(6).toDouble,split_list(7).toDouble,split_list(8).toDouble, 24 split_list(9).toDouble,split_list(10).toDouble,split_list(11).toDouble) 25 } 26 val mid = map_data.sample(false,0.6,0)//随机取样,训练模型 27 val df = sqlContext.createDataFrame(mid) 28 val colArray = Array("c1", "c2", "c3", "c4", "c5", "c6", "c7", "c8", "c9", "c10", "c11") 29 val data = df.toDF("c1", "c2", "c3", "c4", "c5", "c6", "c7", "c8", "c9", "c10", "c11") 30 val assembler = new VectorAssembler().setInputCols(colArray).setOutputCol("features") 31 val vecDF = assembler.transform(data) 32 //准备预测集合 33 val map_data_for_predict = map_data 34 val df_for_predict = sqlContext.createDataFrame(map_data_for_predict) 35 val data_for_predict = df_for_predict.toDF("c1", "c2", "c3", "c4", "c5", "c6", "c7", "c8", "c9", "c10", "c11") 36 val colArray_for_predict = Array("c1", "c2", "c3", "c4", "c5", "c6", "c7", "c8", "c9", "c10", "c11") 37 val assembler_for_predict = new VectorAssembler().setInputCols(colArray_for_predict).setOutputCol("features") 38 val vecDF_for_predict: DataFrame = assembler_for_predict.transform(data_for_predict) 39 // 建立模型,进行预测 40 // 设置线性回归参数 41 val lr1 = new LinearRegression() 42 val lr2 = lr1.setFeaturesCol("features").setLabelCol("c5").setFitIntercept(true) 43 // RegParam:正则化 44 val lr3 = lr2.setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8) 45 // 将训练集合代入模型进行训练 46 val lrModel = lr3.fit(vecDF) 47 // 输出模型全部参数 48 lrModel.extractParamMap() 49 //coefficients 系数 intercept 截距 50 println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}") 51 // 模型进行评价 52 val trainingSummary = lrModel.summary 53 trainingSummary.residuals.show() 54 println(s"均方根差: ${trainingSummary.rootMeanSquaredError}")//RMSE:均方根差 55 println(s"判定系数: ${trainingSummary.r2}")//r2:判定系数,也称为拟合优度,越接近1越好 56 val predictions = lrModel.transform(vecDF_for_predict) 57 val predict_result = predictions.selectExpr("features","c5", "round(prediction,1) as prediction") 58 predict_result.rdd.saveAsTextFile("src/sparkMLlib/manResult") 59 sc.stop() 60 } 61 }
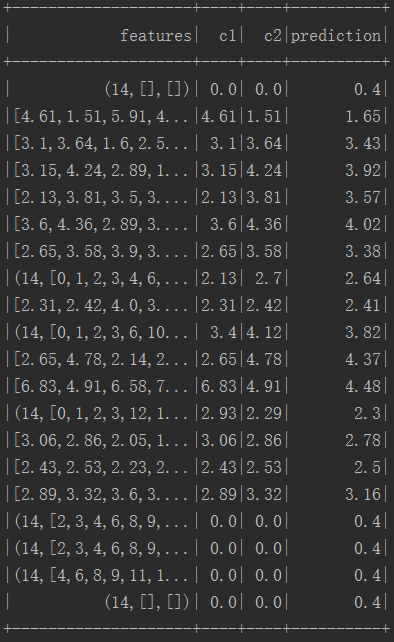
六.执行结果
性能评估:

结果: